Sample-based estimation of mean electricity consumption curves for small domains
Section 5. Application to electricity consumption curves
We
will now test the methods that we have just presented to compare their
performance on electricity consumption data for French residential clients.
5.1 Presentation
of the data set
We
worked with a data set belonging to EDF that contains electricity consumption
curves for
French residential clients by daily interval from October 2011
to March 2012, without any missing values
points). This population is subdivided
into
domains corresponding to geographic areas with respective sizes
of 573, 195, 304, 121, 228, 219, 45 and 220. For
confidentiality purposes, we cannot describe the data set in great detail, or
show the mean curves by domain.
By
way of illustration, Figure 5.1 shows the appearance of the standardized
curves (i.e., each curve is divided by its mean calculated over the period of
time studied) for five random individuals, and Figure 5.2 shows the
appearance of the first five principal components of the functional PCA created
for this data set.
We
see that the first component, the overall appearance of which is similar to
that of the mean curve, is a “level” effect. Components two and three, which present peaks
during the coldest period in February, describe the sensitivity of consumption
to outside temperatures. The fourth compares “mid-season” consumption to
“wintertime” consumption and, finally, the fifth shows a low at about Christmas
(and about February 14).
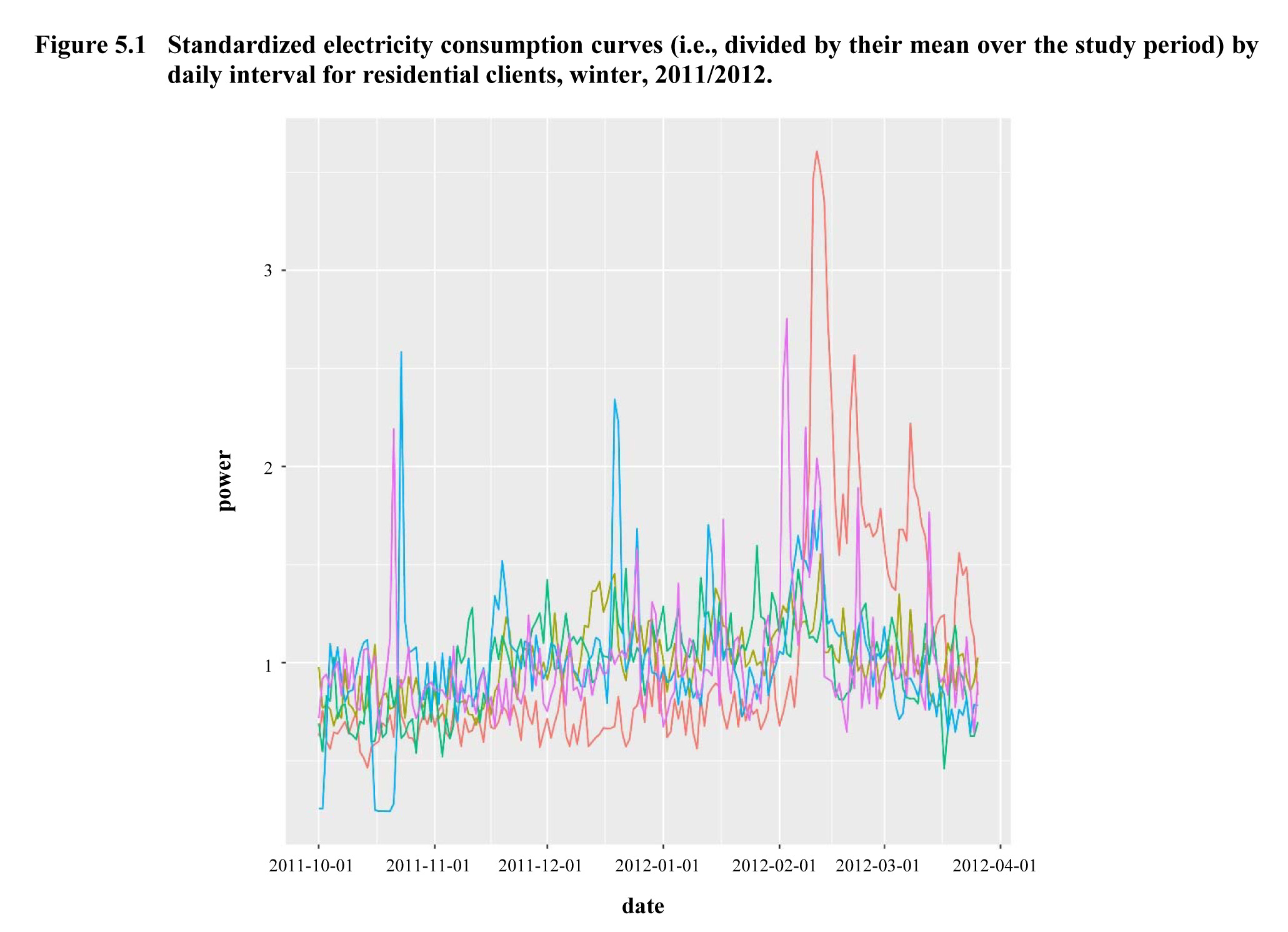
Description for Figure 5.1
Linear graph showing the standardized electricity consumption curves by daily interval for residential clients during the 2011/2012 winter. Power is on the y-axis, ranging from 0 to 3.5. Time is on the x-axis, going from October 1st, 2011 to April 1st, 2012. There are five lines on the graph, each one representing the standardized electricity consumption of a randomly selected client. The consumption is generally between 0.5 and 1.5 exept for the occasional peaks.
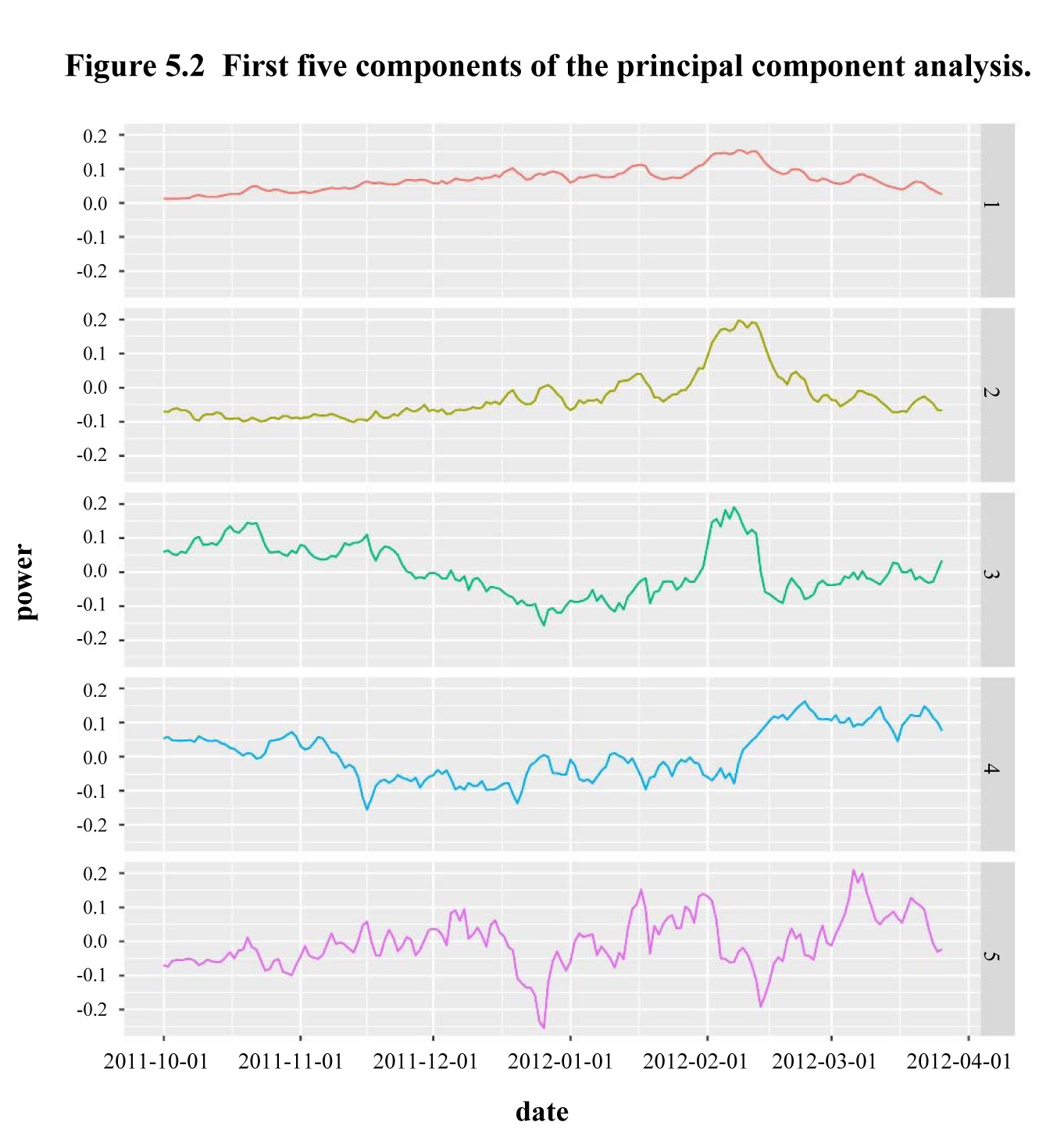
Description for Figure 5.2
Figure made of five linear graphes each one presenting one of the first five components of the principal component analysis. Power is on the y-axis, ranging from -0.2 to 0.2. Time is on the x-axis, going from October 1st, 2011 to April 1st, 2012. We see that the first component, the overall appearance of which is similar to that of the mean curve, is a “level” effect. Components two and three, which present peaks during the coldest period in February, describe the sensitivity of consumption to outside temperatures. The fourth compares “mid-season” consumption to “wintertime” consumption and, finally, the fifth shows a low at about Christmas (and about February 14).
For
each individual in our population of study, we have four auxiliary variables at
the individual level: contract power (in three classes), rate option (base or
off-peak periods) (in the base option, the price per kWh remains constant,
while the rate for off-peak periods is reduced for eight hours [referred to as
off-peak]. The
largest consumers tend to prefer that rate. Off-peak
periods can vary from one client to another, but this factor has no impact
here, as we are working on a daily interval), the previous year’s annual
consumption, and the type of dwelling (apartment or single home). These auxiliary variables remain the same for all methods used
in order to compare identical auxiliary information. All
tests were implemented in R.
5.2 Test
protocol
We
compare various estimators obtained using the methods set out in this chapter,
for various types of modelling (unit-level linear mixed models, linear
functional regressions, regression trees, random forests). We test two versions of
the unit-level linear mixed model, one by placing linear mixed models on the
PCA scores, as suggested in Section 4.2, and the other by applying them
directly to the values of the curves of instants of discretization.
For
non-parametric methods, the forests and trees have a depth (number of levels)
of 5 and a minimum size of 5 leaves. There are 40 trees in the forests. The algorithms can be applied by separating the estimation of
the level of the curve and its form (standardization = “yes”) or not
separating (standardization = “no”). To not
multiply the possible combinations, we finally focused on the estimators listed
in Table 5.1. The parameters of the regression
tree and random forest models are set out in Table 5.2.
Table 5.1
Various estimation method tests
Table summary
This table displays the results of Various estimation method tests. The information is grouped by Title (appearing as row headers), Reference and Projection (appearing as column headers).
| Title |
Reference |
Projection |
| Horvitz-Thompson |
Equation (3.1) |
None |
| Calibration |
Equation (3.2) |
None |
| Linear mixed model |
Section (4.2) |
None |
| Linear mixed model on PCA |
Equation (4.11) |
PCA |
| Linear regression |
Equation (4.4) |
None |
| Courbotree |
Section (4.3) |
None |
| Standardized Courbotree |
Section (4.3) |
None |
| Courboforest |
Section (4.4) |
None |
Table 5.2
Parameters for trees and random forests
Table summary
This table displays the results of Parameters for trees and random forests. The information is grouped by Title (appearing as row headers), Depth (number of levels), Number of trees and Standardization (appearing as column headers).
| Title |
Depth (number of levels) |
Number of trees |
Standardization |
| Courbotree |
5 |
1 |
No |
| Standardized Courbotree |
5 |
1 |
Yes |
| Courboforest |
5 |
40 |
No |
To
evaluate the quality of our estimation methods, our test protocol consists of
conducting a large number
of sampling simulations from our original population and then estimating
the mean curve for each
domain based on each sample gathered by the various proposed
methods. In our simulations, the eighth domain
will always be unsampled in order to measure the performance
of our various estimators in this scenario. For each
simulation, we select
individuals by simple random sampling from among those in the
seven sampled domains
Let
the mean curve for the domain
at the instant
and
its estimator by a given method. We calculate the relative bias of
where
is the Monte Carlo expectation of the estimator
with
the estimator of the mean curve obtained for the
simulation, for
A second indicator, known as relative efficiency (RE), is
calculated as follows:
where
is the Monte Carlo mean square error,
The lower the RE indicator, the more
the estimator will be considered effective. An RE of 100 corresponds to an indicator as effective as the
reference estimator.
Here,
the reference estimator
is the Horvitz-Thompson estimator (which, for our simple
random sampling plan, is the simple mean of the curves in the domain
considered); it corresponds to the model described by equation (3.1). This estimator cannot be calculated for the unsampled domain.
The RE estimator is then obtained
by dividing the MSE of the various estimators by the
mean MSE of the Horvitz-Thompson estimator over the seven sampled domains, i.e.
with
For
each indicator and each instant
the results obtained for the various sampled domains are then
aggregated for all domains,
and
for
while the indicators obtained for the unsampled domain are
used as-is.
Finally,
to evaluate overall performance, we consider the mean of those indicators for
all instants in the test period, while still separating the sampled domains
from the unsampled domain. We also look at the calculation times of the various
estimators.
5.3 Results
and test conclusions
The
test results of the methods are presented in Table 5.3 and illustrated in
Figures 5.3 to 5.5.
Table 5.3
Mean method performance indicators (RB, RE) for all instants of discretization and domains, separating the unsampled domain from the others
Table summary
This table displays the results of Mean method performance indicators (RB. The information is grouped by Domain type (appearing as row headers), Method, RE (%) and RB (%) (appearing as column headers).
| Domain type |
Method |
RE (%) |
RB (%) |
| Sampled |
Horvitz-Thompson |
100.00 |
0.25 |
| Sampled |
Calibration |
37.13 |
-0.47 |
| Sampled |
Linear mixed model |
14.69 |
0.60 |
| Sampled |
Linear mixed model PCA |
15.40 |
0.67 |
| Sampled |
Linear regression |
24.87 |
1.20 |
| Sampled |
Courbotree |
20.54 |
0.80 |
| Sampled |
Standardized Courbotree |
22.35 |
1.45 |
| Sampled |
Courboforest |
24.66 |
0.62 |
| Unsampled |
Horvitz-Thompson |
This is an empty cell |
This is an empty cell |
| Unsampled |
Calibration |
This is an empty cell |
This is an empty cell |
| Unsampled |
Linear mixed model |
13.43 |
4.66 |
| Unsampled |
Linear mixed model PCA |
13.49 |
4.77 |
| Unsampled |
Linear regression |
14.38 |
5.09 |
| Unsampled |
Courbotree |
14.29 |
3.48 |
| Unsampled |
Standardized Courbotree |
16.63 |
5.88 |
| Unsampled |
Courboforest |
15.97 |
0.37 |
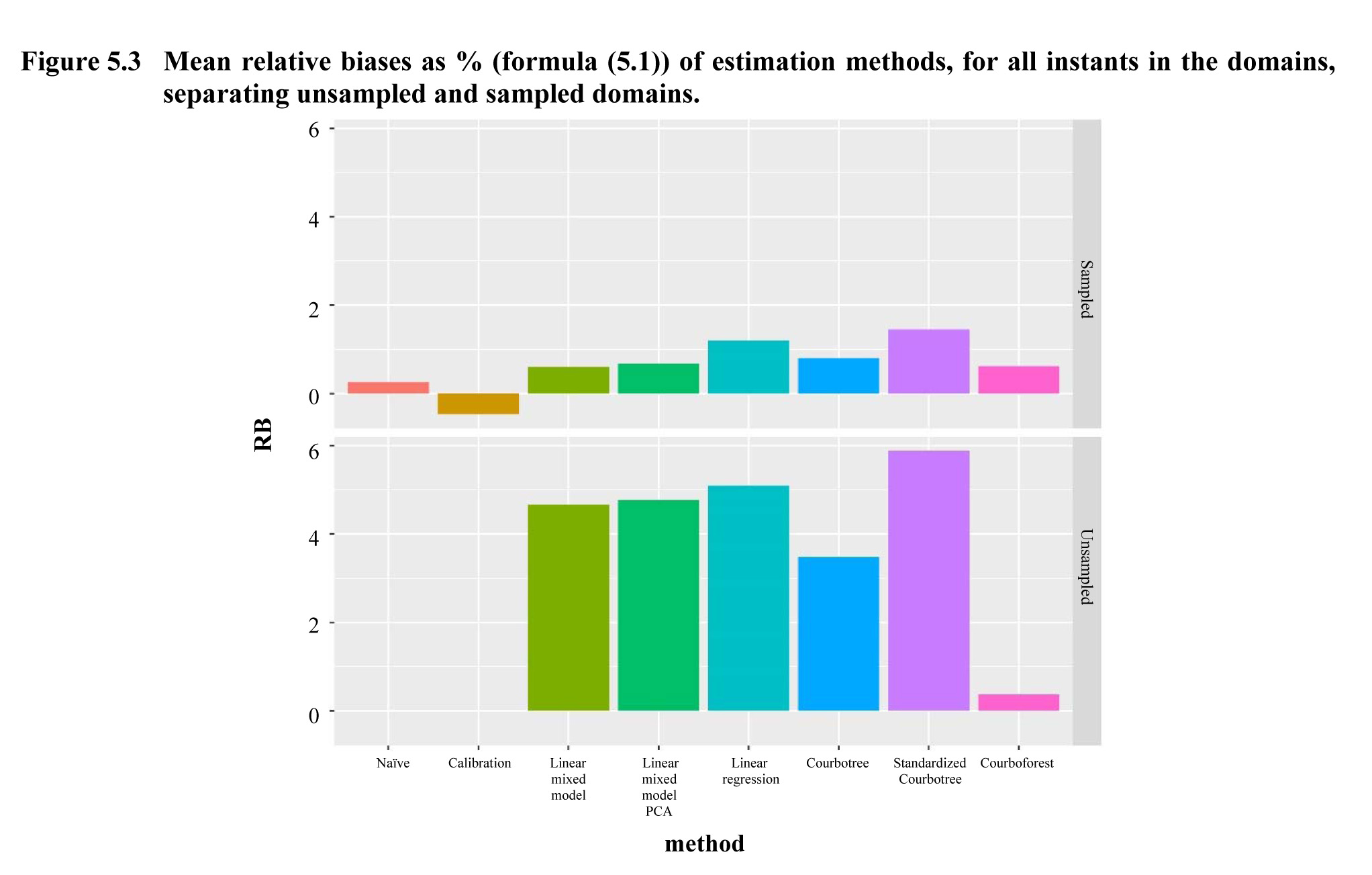
Description for Figure 5.3
Figure made of two vertical band diagrams. Each diagram presents the mean relative biases as % of eight estimation methods for either the unsampled or the sampled domains. The relative bias is on the y-axis and the estimation methods are on the x-axis. Data are in the following table:
Data table 5.3
Table summary
This table displays the results of Data table 5.3. The information is grouped by Estimation method (appearing as row headers), Sampled domains and Unsampled domains (appearing as column headers).
| Estimation method |
Sampled domains |
Unsampled domains |
| RB (%) |
RB (%) |
| Horvitz-Thompson |
0.25 |
This is an empty cell |
| Calibration |
-0.47 |
This is an empty cell |
| Linear mised model |
0.6 |
4.66 |
| Linear mixed model PCA |
0.67 |
4.77 |
| Linear regression |
1.2 |
5.09 |
| Courbotree |
0.8 |
3.48 |
| Standardized Courbotree |
1.45 |
5.88 |
| Courboforest |
0.62 |
0.37 |
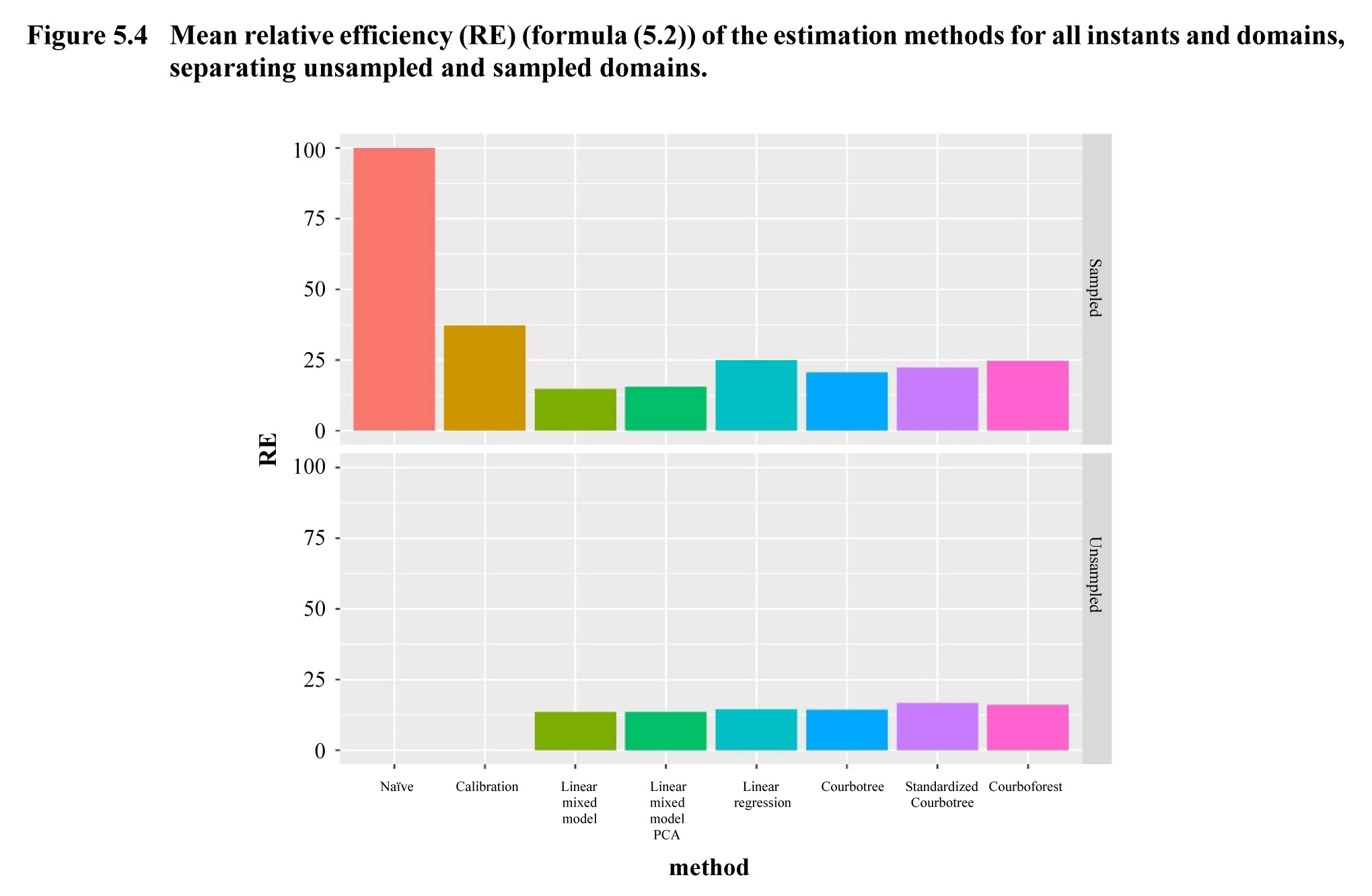
Description for Figure 5.4
Figure made of two vertical band diagrams. Each diagram presents the mean relative efficiency of eight estimation methods for either the unsampled or the sampled domains. The relative efficiency is on the y-axis and the estimation methods are on the x-axis. Data are in the following table:
Data table 5.4
Table summary
This table displays the results of Data table 5.4. The information is grouped by Estimation method (appearing as row headers), Sampled domains and Unsampled domains (appearing as column headers).
| Estimation method |
Sampled domains |
Unsampled domains |
| RE (%) |
RE (%) |
| Horvitz-Thompson |
100 |
|
| Calibration |
37.13 |
|
| Linear mised model |
14.69 |
13.43 |
| Linear mixed model PCA |
15.4 |
13.49 |
| Linear regression |
24.87 |
14.38 |
| Courbotree |
20.54 |
14.29 |
| Standardized Courbotree |
22.35 |
16.63 |
| Courboforest |
24.66 |
15.97 |
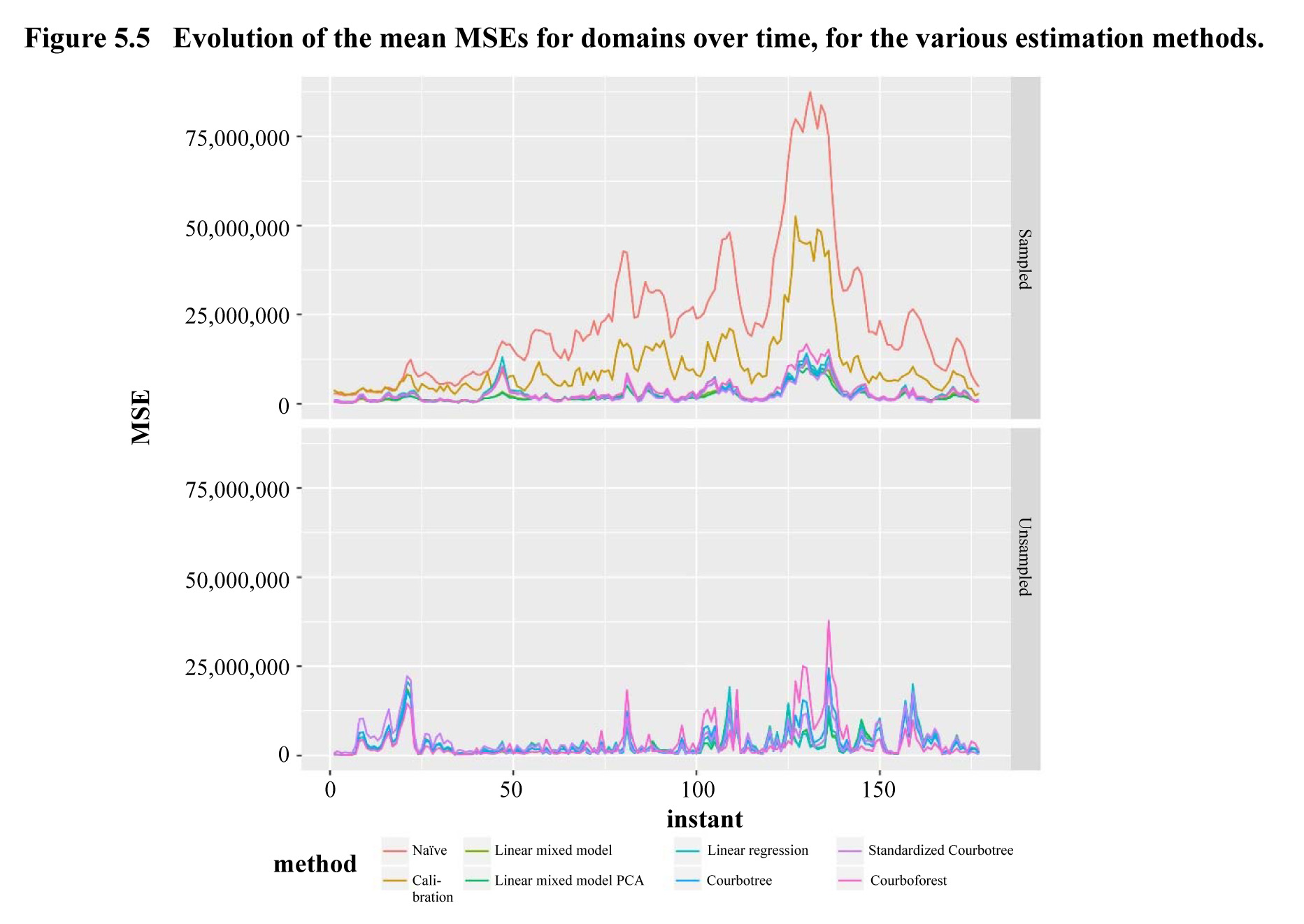
Description for Figure 5.5
Figure made of two linear graphes. Each graph presents the evolution of the mean MSEs for domains over time, for eight estimation methods, for either the samples or the unsampled domains. The MSE is on the y-axis, ranging from 0 to 75,000,000. Time is on the x-axis. There are eight lines on the first graph, one for each estimation methods: naive, calibration, linear mixed model, linear mixed model PCA, linear regression, courbotree, standardized courbotree and courboforest. Only the last six are represented on the second graph. For both graphes, the MSE is higher in the winter (January and February). The naive and calibration estimators adapt least well to this situation. The other methods give similar results among themselves.
For
sampled domains, we see that the integration of explanatory variables in the
estimate, regardless of the method used, leads to a net gain in performance:
thus, for the least effective method (the estimator by calibration), the error
is divided by three when explanatory variables are used.
As
well, the use of our various estimators based on superpopulation models leads
to an additional gain in accuracy: the RE for our various methods thus range from 15% for
linear mixed models to 25% for random forests.
The
linear mixed models are the most effective method, so we can assume that there
are characteristics of the domains that are unexplainable using only the
auxiliary variables that this type of model is able to capture. We therefore go
from an RE of 25% for the linear functional regression to an RE of
approximately 15% by including these random effects.
The
tree and random forest methods capture non-linearities in the relationship
between explanatory variables and the interest variable, which explains why
these methods give better results than linear functional regressions: the RE of the various
non-parametric methods are between 20% and 25%, compared to 25% for linear
functional regressions. Very surprisingly, the
regression tree gives better results than the random forest. We can put forth the theory that this is because our objective
is to best estimate the mean curve of a series of units, not each curve
individually. It is therefore possible that the tree is
not as good for predicting each curve, but better at the aggregate level. As well, on this particular data set, the method gives the
best results when working on raw curves, not when distinguishing between the
estimation of form and level.
Projecting
curves based on the PCA does not seem to lead to any significant gains in
accuracy here.
The
Horvitz-Thompson estimator cannot be produced on unsampled domains. The differences between
the other methods are much more restricted than on the sampled domains: the
random effects cannot be estimated for unsampled domains.
Finally,
in Figure 5.5, we trace the mean square error of our estimators for the
sampled and unsampled domains.
We note that this square error is higher in the winter
(January and February). This high variability could be
due to a sharp drop in outside temperatures during those months, which
increases the variability of heating consumption (difference in behaviour and
electrical heating equipment depending on clients). The
naive and calibration estimators adapt least well to this situation.
5.4 Comparison
of methods and selection criteria
Each
model-based method has benefits and drawbacks. Unit-level linear mixed
models are the only ones that, due to random effects, make it possible for the
modelling to include domain characteristics not reflected in auxiliary
information. It thus seems relevant to use them when
assuming that the explanatory variables do not make it possible to explain all
differences between domains.
The
linear functional regression ignores the random effect of the domains, so we
expect it to be less effective than linear mixed models due to its
construction. Finally, the two non-parametric methods allow for better
modelling of the non-linear relationships between the explanatory variables and
the interest variable, but on the other hand, does not make it possible to
capture the differences between domains that are not reflected in the auxiliary
information. They also require the availability of
auxiliary information
for each individual in the population when, in the past, we
only needed mean values
for each domain in the population and
for the sample. The choice between a
parametric and non-parametric approach will therefore depend on the nature of
the problem, the diversity of domains and the explanatory variables available.
Be believe that neither of the two approaches is
systematically preferable over the other.
A
process for choosing between the two approaches could be to estimate the
respective variances in the random effects and the residuals in the linear
mixed models and, depending on the relative scope of those effects, moving more
toward one or the other type of model. Conversely, cross-validation can be used to
quantify the respective performance of the linear mixed models and the
non-parametric models for predicting the aggregates of individual curves in
order to direct our choice.
Among
the non-parametric methods, the choice between regression trees and random
forests will depend on the predictive performance of those methods on data, for
the mean curves of domains. Generally, we can assume that random forests will give better
results than regression trees for individual data (see Breiman et al.,
1984); however, it is entirely possible that the best of the two methods for
predicting each curve may not be the one that gives the best results to all
domains or, at the very least, that the two methods are reduced when we
consider the prediction of mean curves of individual aggregates. As well, due to their construction, random forests require a
lot more calculation time than regression trees and that aspect cannot be
ignored when the data sets being processed are large in size.
