
A short note on quantile and expectile estimation in unequal probability samples 5. Simulations
We run a small simulation study to show the performance of the expectile based estimates. In the following, we make use of the Mizuno sampling method (see Midzuno 1952) and define the inclusion probabilities proportional to a measure of size see R package “sampling” by Tillé and Matei (2015). We examine two data sets also used in Kuk (1988). The first data set (Dwellings) contains two variables, the number of dwelling units and the number of rented units which are highly correlated (with a correlation of 0.97); see also Kish (1965). The second data set (Villages) includes information on the population and on the number of workers in household industry for 128 villages in India; see Murthy (1967). In the second data set the correlation between and is 0.54. In order to compare our simulation results with the results of Kuk (1988) we choose the same sample size of (from a total population of for the Dwellings data and for the Villages data).
We compare quantiles defined by inversion of with quantiles defined by inversion of In Table 5.1 we give the root mean squared error (RMSE) and the relative efficiency for specified quantiles. We note that the median for the village data and for the Dwelling data also upper quantiles derived from expectiles yield increased efficiency. Also the efficiency gain does not hold uniformly as we observe a loss of efficiency for lower quantiles.
| quantiles |
quantiles from expectiles |
relative efficiency |
||
|---|---|---|---|---|
| Dwellings | 0.1 | 2.57 | 2.76 | 1.07 |
| 0.25 | 1.77 | 1.97 | 1.11 | |
| 0.5 | 2.45 | 2.35 | 0.96 | |
| 0.75 | 3.15 | 2.91 | 0.92 | |
| 0.9 | 4.20 | 3.43 | 0.82 | |
| Villages | 0.1 | 5.52 | 6.65 | 1.21 |
| 0.25 | 11.41 | 10.31 | 0.90 | |
| 0.5 | 12.29 | 11.69 | 0.95 | |
| 0.75 | 16.24 | 15.41 | 0.95 | |
| 0.9 | 13.31 | 18.34 | 1.38 |
To obtain more insight we run a simulation scenario which involves a larger sample size of selected from populations of sizes and We draw and from a bivariate log standard normal distribution with and The variables and are drawn such that the correlation between the variables is equal to 0.9. We again calculate the root mean squared error for a range of values and show the relative efficiency of the expectile based approach in Figure 5.1. For better visual presentation we show a smoothed version of the relative efficiency. We notice a reduction in the root mean squared error for both cases and We may conclude that the expectiles can easily be fitted in unequal probability sampling and the relation between expectiles and the distribution function can be used numerically to calculate quantiles with increased efficiency. This efficiency gain holds for upper quantiles only, that is for bounded away from zero. Note however that the sampling scheme is such that large values of are sampled with higher probability, reflecting that the sampling scheme aims to get more reliable estimates for the right hand side of the distribution function, i.e., for large quantiles. If we are interested in small quantiles we should use a different samling scheme by giving individuals with small values of an increased inclusion probability. In this case the behavior shown in Figure 5.1 would be mirrored with respect to
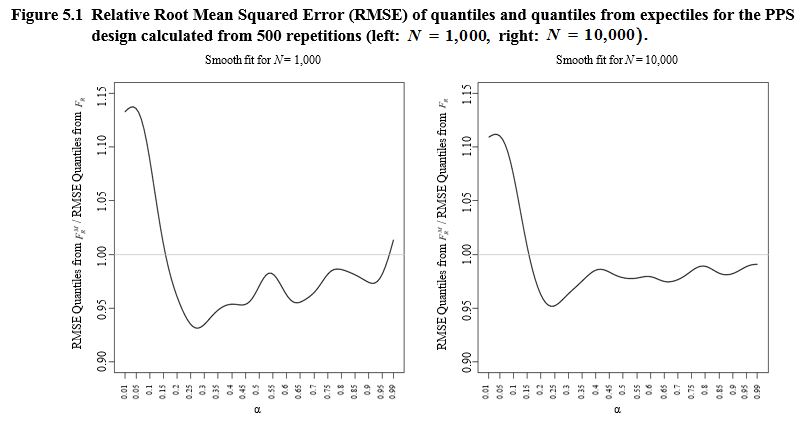
Description of Figure 5.1
Figure made of two graphs presenting the relative root mean squared error of quantiles and quantiles from expectiles for the Probability Proportional to Size (PPS) design calculated from 500 repetitions, for and For both graphs, the y axis is the ratio of RMSE quantiles from and from going from 0.90 to 1.15. is on the x axis, going from 0.01 to 0.99. For the ratio is close to 1.15 for small values before decreasing between 0.90 and 0.95 for an value of about 0.25. After, the ratio is globally increasing slowly toward 1.00 when increases. For the ratio is close to 1.10 for small values before decreasing to about 0.95 for between 0.20 and 0.25. After, the ratio is globally increasing more quickly toward 1.00 when increases.
- Date modified: