Adaptive survey designs to minimize survey mode effects – a case study on the Dutch Labor Force Survey
4. Case study: The Dutch Labor Force SurveyAdaptive survey designs to minimize survey mode effects – a case study on the Dutch Labor Force Survey
4. Case study: The Dutch Labor Force Survey
In this section, we discuss a case study linked to the
Dutch Labor Force Survey (LFS) of the years 2010
−
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaeyOeI0caaa@3864@
2012. We briefly describe the design of the
LFS first. We then proceed to a description of the selected design features and
the selected population subgroups. Next, we explain how we have estimated the
main input parameters to the optimization problem: response propensities,
telephone registration propensities, variable costs and adjusted method effects
with respect to two different benchmark designs. Following the estimation, we
present the main optimization results. We end with a discussion of the
sensitivity of optimal designs to inaccuracy of input parameters. For full
details, we refer to Calinescu and
Schouten (2013b).
4.1 The Dutch
LFS design and redesign in 2010
–
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9IqqrpepC0xbbL8F4rqqr=hbbG8pue9Fbe9q8
qqvqFr0dXdbrVc=b0P0xb9peuD0xXddrpe0=1qpeea0=yrVue9Fve9
Fve8meaabaqaciGacaGaaeWabaWaaeaaeaaakeaaieqajugWbabaaa
aaaaaapeGaa83eGaaa@38AC@
2012
The Dutch LFS is a monthly household survey using a
rotating panel with five waves at quarterly intervals. The LFS is based on an
address sample using a two-stage design in which the first stage consists of
municipalities and the second consists of addresses. A stratified simple random
sample is drawn based on the household age, ethnicity and registered
unemployment composition. All households, to a maximum of eight, that are
residents at the address are invited to participate. Within each household, all
members of 15 years and older are eligible; they form the potential labor force
population. The LFS contains a variety of topics, from employment status,
profession and working hours to educational level, but the main survey
statistic is the unemployment rate.
Up to 2010, the LFS consisted of a face-to-face first
wave and telephone subsequent waves. For various reasons, costs being the most
important, the first wave went through a major redesign. The other waves were
left unchanged, except for a few relatively small changes to the
questionnaires. The redesign consisted of two phases: First, telephone was
added as a survey mode, and, second, also Web was added as a survey mode. In
the first phase, the face-to-face first wave was replaced by a concurrent mode design
where all households with at least one listed/registered phone number were
assigned to telephone and all other households to face-to-face. The listed
phone numbers consist of both landline and mobile phone numbers that can be
bought from commercial vendors. In the second phase, the telephone and
face-to-face concurrent design was preceded by a Web invitation, resulting in a
mix of a sequential and a concurrent design. All households were sent an
invitation to participate through an on-line questionnaire. Nonresponding
households were approached by telephone if a listed number was available and
otherwise by face-to-face. The first phase was performed during 2010 and the
second phase during 2012. In both years large parallel samples were drawn in
order to assess method effects between the designs on the unemployment rate.
The 2010 parallel run compared the old design to the intermediate concurrent
design and the 2012 parallel run compared the intermediate design to the final
design with all three modes.
The redesign did not change the data collection strategy
per mode. In all years, the face-to-face contact strategy for the LFS first
wave consists of a maximum of six visits to the address and contacts are varied
over days of the week and times during the day. If no contact is made at the
sixth visit, then the address is processed as a noncontact. The telephone
contact strategy consists of three series of three calls. The three series are
termed contact attempts and represent three different interviewer shifts. In
each shift the phone number is called three times with a time lag of roughly an
hour. The Web strategy is an advance letter with a login code to a website and
two reminder letters with time lags of one week.
We use the 2010
−
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaeyOeI0caaa@3864@
2012 first wave LFS data to estimate various
input parameters for the optimization model. In order to keep the exposition
simple, and since the subsequent waves were not redesigned, we restrict
ourselves to methods effects on unemployment rate estimates based on the first
wave only. However, the first wave redesign may clearly have influenced the
recruitment and response to waves 2 to 5. In follow-up studies at Statistics
Netherlands, recruitment propensities to subsequent waves were included in the
optimization problem, but we do not discuss these here. The LFS data were
augmented with data from two administrative registers: the POLIS register and
the UWV register. The POLIS register contains information about employments,
allowances, income from employment and social benefits. The UWV register
contains persons that have registered themselves as unemployed and applied for
an unemployment allowance. Both registers contain relevant variables for the
LFS and will be used to stratify the population.
4.2 The strategy
set
The parallel runs in the LFS allow us to consider a
multi-mode optimization problem with various single mode and sequential
mixed-mode strategies. In the following, we abbreviate the telephone and
face-to-face modes to
T
e
l
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipu0de9LqFHe9fr
pepeuf0xe9q8qq0RWFaDk9vq=dbvh9v8Wq0db9Fn0dbba9pw0lfr=x
fr=xfbpdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbaaaa@395D@
and
F
2
F
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipu0de9LqFHe9fr
pepeuf0xe9q8qq0RWFaDk9vq=dbvh9v8Wq0db9Fn0dbba9pw0lfr=x
fr=xfbpdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaaik
dacaWGgbGaaiilaaaa@39AB@
respectively. Although, the sequential
strategy
W
e
b
→
F
2
F
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamOraiaaikdacaWGgbaaaa@3E62@
is observed only for large households and for
households without a registered phone, we do include this strategy in the
optimization.
Since later face-to-face and telephone calls are
relatively much more expensive than early calls, we also introduce a simple cap
on calls. For
T
e
l
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipu0de9LqFHe9fr
pepeuf0xe9q8qq0RWFaDk9vq=dbvh9v8Wq0db9Fn0dbba9pw0lfr=x
fr=xfbpdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbaaaa@395D@
we set the cap after two calls and for
F
2
F
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipu0de9LqFHe9fr
pepeuf0xe9q8qq0RWFaDk9vq=dbvh9v8Wq0db9Fn0dbba9pw0lfr=x
fr=xfbpdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaaik
dacaWGgbaaaa@38FB@
after three calls. These values are motivated
by historical survey data, e.g., after these numbers of calls the cost per call
increases quickly. We let
T
e
l
2
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipu0de9LqFHe9fr
pepeuf0xe9q8qq0RWFaDk9vq=dbvh9v8Wq0db9Fn0dbba9pw0lfr=x
fr=xfbpdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaGOmaaaa@3A19@
and
F
2
F
3
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipu0de9LqFHe9fr
pepeuf0xe9q8qq0RWFaDk9vq=dbvh9v8Wq0db9Fn0dbba9pw0lfr=x
fr=xfbpdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaaik
dacaWGgbGaaG4maaaa@39B8@
denote the strategies where a cap is placed on
the number of calls.
T
e
l
2
+
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipu0de9LqFHe9fr
pepeuf0xe9q8qq0RWFaDk9vq=dbvh9v8Wq0db9Fn0dbba9pw0lfr=x
fr=xfbpdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaGOmaiaaykW7cqGHRaWkaaa@3C86@
and
F
2
F
3
+
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipu0de9LqFHe9fr
pepeuf0xe9q8qq0RWFaDk9vq=dbvh9v8Wq0db9Fn0dbba9pw0lfr=x
fr=xfbpdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaaik
dacaWGgbGaaG4maiaaykW7cqGHRaWkaaa@3C25@
represent strategies where there is no cap and
the regular contact strategy is applied. We do realize that placing a cap is
not the same as restricting the number of calls in practice. This holds especially
for face-to-face. With fewer calls, interviewers or interviewer staff may
change behaviour and spread calls differently. At Statistics Netherlands the
T
e
l
2
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipu0de9LqFHe9fr
pepeuf0xe9q8qq0RWFaDk9vq=dbvh9v8Wq0db9Fn0dbba9pw0lfr=x
fr=xfbpdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaGOmaaaa@3A19@
and
F
2
F
3
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipu0de9LqFHe9fr
pepeuf0xe9q8qq0RWFaDk9vq=dbvh9v8Wq0db9Fn0dbba9pw0lfr=x
fr=xfbpdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaaik
dacaWGgbGaaG4maaaa@39B8@
strategies are viewed as censored strategies
with shorter data collection periods, e.g., two weeks instead of four weeks.
Hence, cases are removed from the interviewer workloads after the pre-specified
data collection period. From this perspective, it is more reasonable to assume
that the optimal contact strategy during the first two weeks of a
F
2
F
3
+
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipu0de9LqFHe9fr
pepeuf0xe9q8qq0RWFaDk9vq=dbvh9v8Wq0db9Fn0dbba9pw0lfr=x
fr=xfbpdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaaik
dacaWGgbGaaG4maiaaykW7cqGHRaWkaaa@3C25@
strategy is not so different from the optimal
contact strategy in
F
2
F
3.
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipu0de9LqFHe9fr
pepeuf0xe9q8qq0RWFaDk9vq=dbvh9v8Wq0db9Fn0dbba9pw0lfr=x
fr=xfbpdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaaik
dacaWGgbGaaG4maiaac6caaaa@3A6A@
Still, we may expect that realized response
propensities and costs in strategies with a cap are different from their
simulated propensities and costs. The strategy set now becomes
S =
{
W e b , T e l 2, T e l 2 + , F 2 F 3, F 2 F 3 + , W e b → T e l 2,
W e b → T e l 2 + , W e b → F 2 F 3, W e b → F 2 F 3 + , Φ } ,
( 4.1 )
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaqbaeaabiGaaa
qaamrr1ngBPrwtHrhAXaqeguuDJXwAKbstHrhAG8KBLbacfaGae8Ne
XpLaeyypa0dabaWaaiqaaeaacaWGxbGaamyzaiaadkgacaqGSaGaaG
jbVlaadsfacaWGLbGaamiBaiaabkdacaqGSaGaaGjbVlaadsfacaWG
LbGaamiBaiaabkdacqGHRaWkcaqGSaGaaGjbVlaadAeacaqGYaGaam
OraiaabodacaqGSaGaaGjbVlaadAeacaqGYaGaamOraiaabodacqGH
RaWkcaqGSaGaaGjbVlaadEfacaWGLbGaamOyaiabgkziUkaadsfaca
WGLbGaamiBaiaabkdacaqGSaaacaGL7baaaeaaaeaadaGacaqaaiaa
ysW7caaMc8UaaGPaVlaaykW7caaMc8UaaGPaVlaaykW7caaMc8UaaG
PaVlaaykW7caaMc8UaaGPaVlaaykW7caaMc8UaaGPaVlaaykW7caWG
xbGaamyzaiaadkgacqGHsgIRcaWGubGaamyzaiaadYgacaqGYaGaey
4kaSIaaeilaiaaysW7caWGxbGaamyzaiaadkgacqGHsgIRcaWGgbGa
aeOmaiaadAeacaqGZaGaaeilaiaaysW7caWGxbGaamyzaiaadkgacq
GHsgIRcaWGgbGaaeOmaiaadAeacaqGZaGaey4kaSIaaGilaiaaysW7
cqqHMoGraiaaw2haaiaacYcaaaGaaGzbVlaaywW7caaMf8UaaGzbVl
aaywW7caGGOaGaaGinaiaac6cacaaIXaGaaiykaaaa@B128@
where
Φ
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaeuOPdyeaaa@38F1@
denotes the nonsampling strategy.
The parallel runs for the LFS in 2010 and 2012 were
large. In both years the LFS sample was doubled in size for six months. Still,
estimated parameters are subject to sampling variation and in case of the
W
e
b
→
F
2
F
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamOraiaaikdacaWGgbaaaa@3E62@
strategies possibly also to bias. We return to
this issue in Section 4.6.
4.3 Population
groups
In order to stratify the population, the regular LFS
weighting variables were used as a starting point: unemployment office
registration, age, household size, ethnicity and registered employment.
Crossing the five variables led to 48 population strata (yes or no registered
unemployed in household times three age classes times two household size
classes times two ethnicity classes times yes or no registered employment in
household). These strata were collapsed to nine disjoint strata based on their
response behavior and mode effects:
Registered unemployed : Households
with at least one person registered to an unemployment office (7.5% of the
population).65+ households without employment :
Households with a maximum of three persons of 15 years and older without a
registration to an unemployment office, without employment and with at least
one person of 65 years or older (19.8% of population)
Young household members and no employment :
Households with a maximum of three persons of 15 years and older without a
registration to an unemployment office, without employment, with all persons
younger than 65 years, and with at least one person between 15 and 26 years of
age (2.4% of population).Non-western without employment :
Households with a maximum of three persons of 15 years and older without a
registration to an unemployment office, without employment, with all persons
younger than 65 years and older than 26 years of age, and at least one person
of non-western ethnicity (1.5% of population).Western without employment :
Households with a maximum of three persons of 15 years and older without a
registration to an unemployment office, without employment, with all persons
younger than 65 years and older than 26 years of age and all persons of western
ethnicity (11.0% of population).Young household member and employment :
Households with a maximum of three persons of 15 years and older without a
registration to an unemployment office, with at least one employment, with all
persons younger than 65 years, and with at least one person between 15 and 26
years of age (15.6% of population).Non-western and employment :
Households with a maximum of three persons of 15 years and older without a
registration to an unemployment office, with at least one employment, with all
persons older than 26 years of age, and at least one person of non-western
ethnicity (3.9% of population).Western and employment : Households
with a maximum of three persons of 15 years and older without a registration to
an unemployment office, with at least one employment, with all persons older
than 26 years of age and all persons of western ethnicity (33.5% of
population).Large households : Households with
more than three persons of 15 years and older without a registration to an
unemployment office (4.9% of population)
The nine population strata were given informal labels in
order to aid interpretation. Note, however, that the strata 7, 8 and 9 may have
household members that are 65+. Furthermore, some subgroups follow from
collapsing certain strata. For instance, households with at least one
employment are found by combining strata 6, 7 and 8, and households with no
more than three members of 15 years and older by combining all strata from 1 to
8.
In the optimization model, the nine strata were allowed
different strategies and with different strategy allocation probabilities. In
addition, we added precision constraints following the regular LFS on another
stratification. Minimum numbers of respondents were requested based on age,
ethnicity and registered unemployment. We refer again to Calinescu and Schouten (2013b) for
details about these strata and corresponding precision thresholds.
4.4 Estimation
of input parameters
The input parameters to the multi-mode optimization
problem are subpopulation response propensities per strategy, subgroup
telephone registration propensities, subgroup costs per sample unit per
strategy, and subgroup adjusted method effects per strategy. We sketch the
estimation of each set of parameters in the following subsections. More details
can be found in Appendix A.
There are three settings that may occur when estimating
input parameters: 1) The strategy is directly observed in historical survey
data, 2) the strategy is only partially observed in historical survey data,
i.e., only for a subset of the sample, and 3) the strategy is not observed at
all.
For the LFS case study, the first setting applies to
strategies
W
e
b
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipu0de9LqFHe9fr
pepeuf0xe9q8qq0RWFaDk9vq=dbvh9v8Wq0db9Fn0dbba9pw0lfr=x
fr=xfbpdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaaiilaaaa@3A06@
T
e
l
2
+
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipu0de9LqFHe9fr
pepeuf0xe9q8qq0RWFaDk9vq=dbvh9v8Wq0db9Fn0dbba9pw0lfr=x
fr=xfbpdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaGOmaiaaykW7cqGHRaWkcaGGSaaaaa@3D36@
F
2
F
3
+
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipu0de9LqFHe9fr
pepeuf0xe9q8qq0RWFaDk9vq=dbvh9v8Wq0db9Fn0dbba9pw0lfr=x
fr=xfbpdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaaik
dacaWGgbGaaG4maiaaykW7cqGHRaWkcaGGSaaaaa@3CD5@
W
e
b
→
T
e
l
2
+
.
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamivaiaadwgacaWGSbGaaGOmaiaaykW7cqGH
RaWkcaaMc8UaaiOlaaaa@442B@
The second setting applies to
W
e
b
→
F
2
F
3
+
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamOraiaaikdacaWGgbGaaG4maiaaykW7cqGH
RaWkaaa@418D@
and the third setting applies to
T
e
l
2
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipu0de9LqFHe9fr
pepeuf0xe9q8qq0RWFaDk9vq=dbvh9v8Wq0db9Fn0dbba9pw0lfr=x
fr=xfbpdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaGOmaiaacYcaaaa@3AC9@
F
2
F
3
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipu0de9LqFHe9fr
pepeuf0xe9q8qq0RWFaDk9vq=dbvh9v8Wq0db9Fn0dbba9pw0lfr=x
fr=xfbpdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaaik
dacaWGgbGaaG4maiaacYcaaaa@3A68@
W
e
b
→
T
e
l
2
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamivaiaadwgacaWGSbGaaGOmaaaa@3F81@
and
W
e
b
→
F
2
F
3.
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamOraiaaikdacaWGgbGaaG4maiaac6caaaa@3FD2@
Sequential mixed-mode designs with
face-to-face as the follow-up mode are only observed for households without a
listed phone number and fall under settings 2 or 3 depending on whether a cap
is placed on the number of calls. We attempted to deal with setting 2 by
modeling the input parameters based on the observed differences in parameters
between
T
e
l
2
+
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipu0de9LqFHe9fr
pepeuf0xe9q8qq0RWFaDk9vq=dbvh9v8Wq0db9Fn0dbba9pw0lfr=x
fr=xfbpdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaGOmaiaaykW7cqGHRaWkaaa@3C86@
and
F
2
F
3
+
.
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipu0de9LqFHe9fr
pepeuf0xe9q8qq0RWFaDk9vq=dbvh9v8Wq0db9Fn0dbba9pw0lfr=x
fr=xfbpdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaaik
dacaWGgbGaaG4maiaaykW7cqGHRaWkcaaMc8UaaiOlaaaa@3E62@
We assumed that the ratio in response
propensity between
F
2
F
3
(
+
)
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaaik
dacaWGgbGaaG4mamaabmaabaGaey4kaScacaGLOaGaayzkaaaaaa@3CF1@
and
T
e
l
2
+
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipu0de9LqFHe9fr
pepeuf0xe9q8qq0RWFaDk9vq=dbvh9v8Wq0db9Fn0dbba9pw0lfr=x
fr=xfbpdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaGOmaiaaykW7cqGHRaWkaaa@3C86@
for households with a listed phone number can
be applied to
W
e
b
→
F
2
F
3
(
+
)
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamOraiaaikdacaWGgbGaaG4mamaabmaabaGa
ey4kaScacaGLOaGaayzkaaaaaa@418B@
and
W
e
b
→
T
e
l
2
+
.
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamivaiaadwgacaWGSbGaaGOmaiaaykW7cqGH
RaWkcaaMc8UaaiOlaaaa@442B@
Furthermore, in the estimation, we assumed
that strategies involving caps on the number of calls are similar to simulated
strategies, i.e., by artificially restricting strategies with the full number
of calls to the specified cap. Hence, we attempted to deal with setting 3 by
censoring strategies. Calinescu and
Schouten (2013b) elaborate these modeling steps.
For the method effect
D
(
s
,
g
)
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamiramaabm
aabaGaam4CaiaaiYcacaWGNbaacaGLOaGaayzkaaGaaiilaaaa@3D13@
two benchmarks were selected
BM
1
=
y
¯
F 2 F 3 +
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaaeOqaiaab2
eadaWgaaWcbaGaaGymaaqabaGccqGH9aqpceWG5bGbaebadaWgaaWc
baGaamOraiaabkdacaWGgbGaae4maiabgUcaRaqabaaaaa@4028@
and
BM
2
= 1 / 3 * (
y
¯
W e b
+
y
¯
T e l 2 +
+
y
¯
F 2 F 3 +
) ,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaaeOqaiaab2
eadaWgaaWcbaGaaGOmaaqabaGccqGH9aqpdaWcgaqaaiaaigdaaeaa
caaIZaaaaiaacQcadaqadaqaaiqadMhagaqeamaaBaaaleaacaWGxb
GaamyzaiaadkgaaeqaaOGaey4kaSIabmyEayaaraWaaSbaaSqaaiaa
dsfacaWGLbGaamiBaiaabkdacqGHRaWkaeqaaOGaey4kaSIabmyEay
aaraWaaSbaaSqaaiaadAeacaqGYaGaamOraiaabodacqGHRaWkaeqa
aaGccaGLOaGaayzkaaGaaiilaaaa@4FFC@
where
y
¯
mode
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGabmyEayaara
WaaSbaaSqaaiaab2gacaqGVbGaaeizaiaabwgaaeqaaaaa@3C6A@
represents the average unemployment rate
estimated via the indicated survey mode. The first benchmark assumes that the
average unemployment rate that is estimated via a single mode face-to-face
design represents the target unemployment rate. The second benchmark assumes
there is no preferred mode, hence, it assigns an equal weight to each of the
three modes. The
F
2
F
3
+
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipu0de9LqFHe9fr
pepeuf0xe9q8qq0RWFaDk9vq=dbvh9v8Wq0db9Fn0dbba9pw0lfr=x
fr=xfbpdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaaik
dacaWGgbGaaG4maiaaykW7cqGHRaWkaaa@3C25@
benchmark is chosen because it is the
traditional mode for the LFS first wave and, hence, determines the LFS time
series up to 2010. Furthermore, we believe it is the mode that provides the
smallest nonresponse bias for many surveys, see, e.g., Klausch et al. (2013a). It is, however, unclear whether
F
2
F
3
+
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipu0de9LqFHe9fr
pepeuf0xe9q8qq0RWFaDk9vq=dbvh9v8Wq0db9Fn0dbba9pw0lfr=x
fr=xfbpdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaaik
dacaWGgbGaaG4maiaaykW7cqGHRaWkaaa@3C25@
should also be considered the mode with the
smallest measurement bias. Hence, we also introduced the second benchmark to
investigate the importance of the benchmark choice.
Standard errors for the estimated input parameters were
approximated using bootstrap resampling per sampling stratum, following the
stratified sampling design.
4.5 Optimization
results
In this section, we explore the optimal allocation and
minimal method effect for various budget levels, between stratum method effect
levels and sample size levels
B
∈ {
160,000; 170,000; 180,000 }
M
∈ {
1 % ; 0.5 % ; 0.25 % }
S
max
∈ {
9,500; 12,000; 15,000 } .
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpkpi0xe9LqFHe9fr
pepeuf0xe9q8qq0RWFaDk9vq=dbvh9v8Wq0db9Fn0dbba9pw0lfr=x
fr=xfbpdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaqbaeaaamGaaa
uaaiaadkeaaeaacqGHiiIZdaGadaqaaiaabgdacaqG2aGaaeimaiaa
bYcacaqGWaGaaeimaiaabcdacaqG7aGaaGjbVlaabgdacaqG3aGaae
imaiaabYcacaqGWaGaaeimaiaabcdacaqG7aGaaGjbVlaabgdacaqG
4aGaaeimaiaabYcacaqGWaGaaeimaiaabcdaaiaawUhacaGL9baaae
aacaWGnbaabaGaeyicI48aaiWaaeaacaaIXaGaaiyjaiaacUdacaaM
e8UaaGimaiaac6cacaaI1aGaaiyjaiaacUdacaaMe8UaaGimaiaac6
cacaaIYaGaaGynaiaacwcaaiaawUhacaGL9baaaeaacaWGtbWaaSba
aSqaaiaab2gacaqGHbGaaeiEaaqabaaakeaacqGHiiIZdaGadaqaai
aabMdacaqGSaGaaeynaiaabcdacaqGWaGaae4oaiaaysW7caqGXaGa
aeOmaiaabYcacaqGWaGaaeimaiaabcdacaqG7aGaaGjbVlaabgdaca
qG1aGaaeilaiaabcdacaqGWaGaaeimaaGaay5Eaiaaw2haaiaai6ca
aaaaaa@78D0@
Appendix B presents the minimal method effects for the
various levels and or the two benchmark designs,
BM
1
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaaeOqaiaab2
eadaWgaaWcbaGaaGymaaqabaaaaa@39F3@
and
BM
2
.
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaaeOqaiaab2
eadaWgaaWcbaGaaGOmaaqabaGccaGGUaaaaa@3AB0@
For the sake of brevity, here, we highlight
mostly the results for
BM
1
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaaeOqaiaab2
eadaWgaaWcbaGaaGymaaqabaGccaGGSaaaaa@3AAD@
which is the former LFS design. The actual
values for the non-adaptive regular three mode LFS design are
B
=
170,000
M
=
3.00
%
S
max
=
11,000
D
¯
BM
1
=
−
0.15
%
.
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipu0de9LqFHe9fr
pepeuf0xe9q8qq0RWFaDk9vq=dbvh9v8Wq0db9Fn0dbba9pw0lfr=x
fr=xfbpdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaqbaeaabiGbaa
aabaGaamOqaaqaaiabg2da9aqaaiaabgdacaqG3aGaaeimaiaabYca
caqGWaGaaeimaiaabcdaaeaacaaMc8UaaGPaVlaaykW7caWGnbaaba
Gaeyypa0dabaGaaG4maiaac6cacaaIWaGaaGimaiaacwcaaeaacaWG
tbWaaSbaaSqaaiGac2gacaGGHbGaaiiEaaqabaaakeaacqGH9aqpae
aacaqGXaGaaeymaiaabYcacaqGWaGaaeimaiaabcdaaeaacaaMc8Ua
aGPaVlaaykW7ceWGebGbaebadaahaaWcbeqaaiaabkeacaqGnbWaaS
baaWqaaiaaigdaaeqaaaaaaOqaaiabg2da9aqaaiabgkHiTiaaicda
caGGUaGaaGymaiaaiwdacaGGLaGaaiOlaaaaaaa@5F00@
Two main conclusions can be drawn from the results.
First, the adaptive design is able to decrease the absolute overall method
effect with respect to both benchmarks while respecting a strict constraint on
the maximal between stratum method effect and keeping the budget at the current
level. The only constraint that need to be relaxed in order to reduce the
overall method effect is the maximal sample size. Second, for benchmark
BM
2
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaaeOqaiaab2
eadaWgaaWcbaGaaGOmaaqabaGccaGGSaaaaa@3AAE@
smaller minimal overall method effects are
obtained than for
BM
1
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaaeOqaiaab2
eadaWgaaWcbaGaaGymaaqabaGccaGGSaaaaa@3AAD@
with the exception of
S
max
= 9,500 .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4uamaaBa
aaleaacaqGTbGaaeyyaiaabIhaaeqaaOGaeyypa0JaaeyoaiaabYca
caqG1aGaaeimaiaabcdacaGGUaaaaa@4095@
This difference is the result of the generally
smaller and more similar values of the stratum method effects
D
(
s
,
g
)
.
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamiramaabm
aabaGaam4CaiaaiYcacaWGNbaacaGLOaGaayzkaaGaaiOlaaaa@3D15@
We can explore the impact of the sample size
constraint by comparing the optimal allocations for
S
max
= 9,500
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4uamaaBa
aaleaacaqGTbGaaeyyaiaabIhaaeqaaOGaeyypa0JaaeyoaiaabYca
caqG1aGaaeimaiaabcdacaGGUaaaaa@4095@
and
S
max
= 15,000 .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4uamaaBa
aaleaacaqGTbGaaeyyaiaabIhaaeqaaOGaeyypa0Jaaeymaiaabwda
caqGSaGaaeimaiaabcdacaqGWaGaaeOlaaaa@413F@
Assume thresholds are set at
B = 170,000 ,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOqaiabg2
da9iaabgdacaqG3aGaaeimaiaabYcacaqGWaGaaeimaiaabcdacaGG
Saaaaa@3EDD@
M = 1 %
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamytaiabg2
da9iaaigdacaGGLaaaaa@3AB3@
and
BM
1
.
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaaeOqaiaab2
eadaWgaaWcbaGaaGymaaqabaGccaGGUaaaaa@3AAF@
Figures 4.1 and 4.2 present the optimal
allocation probabilities per stratum and strategy given that a unit is sampled.
Each figure can be seen as a matrix where each row represents one of the
strategies in
S
R
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaWefv3ySLgznf
gDOfdaryqr1ngBPrginfgDObYtUvgaiuaacqWFse=udaahaaWcbeqa
aiaadkfaaaaaaa@43DF@
and each column one of the nine strata described
in Section 4.3, e.g. ,
g
1
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaIXaaabeaaaaa@394A@
is the registered unemployed stratum. Each
cell in the matrix, i.e., intersection of a row with a column, shows the
probability of assigning the corresponding strategy to the corresponding
stratum. The probabilities are depicted as bars; the larger a bar, the larger
the proportion of the stratum that is allocated to the strategy. The
probabilities sum up to one over the strategies, i.e., over the rows. The exact
values are given in the bars in case they are 20% or larger. Figure 4.1 and 4.2
show a clear shift in allocation probabilities when the sample size is allowed
to increase, e.g. , stratum 6 (young household member and employment) is almost
fully allocated to
W
e
b
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipu0de9LqFHe9fr
pepeuf0xe9q8qq0RWFaDk9vq=dbvh9v8Wq0db9Fn0dbba9pw0lfr=x
fr=xfbpdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbaaaa@3956@
and stratum 8 (western and employment) and 9
(large households) change from sequential to face-to-face only strategies.
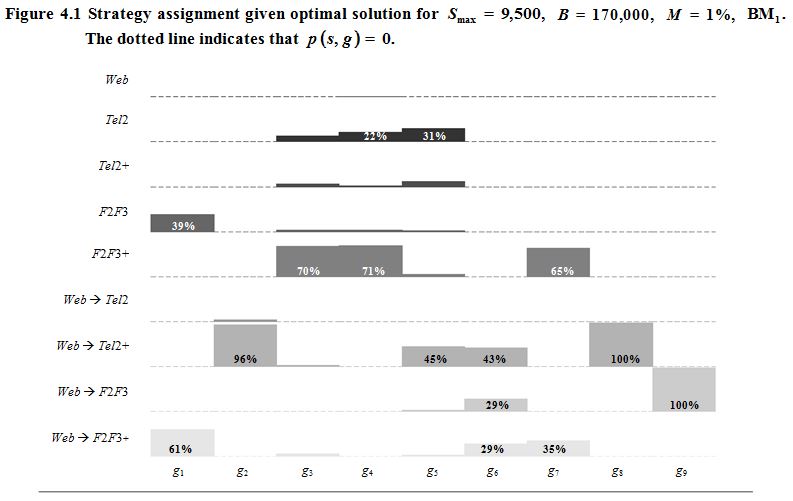
Description for Figure 4.1
Figure
that can be seen as a matrix where each row represents one of the strategies in
S
R
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaWefv3ySLgznf
gDOfdaryqr1ngBPrginfgDObYtUvgaiuaacqWFse=udaahaaWcbeqa
aiaadkfaaaaaaa@43E0@
and each column one of the nine strata,
g
1
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaIXaaabeaaaaa@394A@
to
g
9
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaI5aaabeaakiaacYcaaaa@3A0C@
described in Section 4.3. See
Section 4.2 and formula (4.1) for a list of the strategies and their
descriptions. For
g
1
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaIXaaabeaakiaacYcaaaa@3A04@
39% will be attributed to
F 2 F 3
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaabk
dacaWGgbGaae4maaaa@3A78@
and 61% to
W e b → F 2 F 3+ .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamOraiaabkdacaWGgbGaae4maiaabUcacaGG
Uaaaaa@40B4@
For
g
2
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaIYaaabeaakiaacYcaaaa@3A05@
96 % will be attributed to
W e b → T e l 2+
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamivaiaadwgacaWGSbGaaeOmaiaabUcaaaa@406A@
and 4% to
W e b → T e l 2 .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamivaiaadwgacaWGSbGaaeOmaiaac6caaaa@406E@
For
g
3
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaIZaaabeaakiaacYcaaaa@3A06@
96% will be attributed to
F 2 F 3+
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaabk
dacaWGgbGaae4maiaabUcaaaa@3B68@
and the rest to
T e l 2, T e l 2 + , F 2 F 3, W e b → T e l 2+ and W e b → F 2 F 3 + .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaeOmaiaabYcacaaMe8UaamivaiaadwgacaWGSbGaaeOm
aiabgUcaRiaabYcacaaMe8UaamOraiaabkdacaWGgbGaae4maiaabY
cacaaMe8Uaam4vaiaadwgacaWGIbGaeyOKH4QaamivaiaadwgacaWG
SbGaaeOmaiaabUcacaqGGaGaaeyyaiaab6gacaqGKbGaaeiiaiaadE
facaWGLbGaamOyaiabgkziUkaadAeacaaIYaGaamOraiaaiodacaqG
RaGaaiOlaaaa@5EDE@
For
g
4
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaI0aaabeaakiaacYcaaaa@3A07@
71% will be attributed to
F 2 F 3+,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaabk
dacaWGgbGaae4maiaabUcacaqGSaaaaa@3C17@
22% to
T e l 2
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaGOmaaaa@3B29@
and the rest to
W e b , T e l 2+ and F 2 F 3 .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaaeilaiaaysW7caWGubGaamyzaiaadYgacaqGYaGaae4k
aiaabccacaqGHbGaaeOBaiaabsgacaqGGaGaamOraiaabkdacaWGgb
Gaae4maiaac6caaaa@486E@
For
g
5
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaI1aaabeaakiaacYcaaaa@3A08@
45% will be attributed to
W e b → T e l 2+,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamivaiaadwgacaWGSbGaaeOmaiaabUcacaqG
Saaaaa@4119@
31% to
T e l 2
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaGOmaaaa@3B29@
and the rest to
T e l 2+, F 2 F 3 , F 2 F 3+, W e b → F 2 F 3 and W e b → F 2 F 3+ .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaeOmaiaabUcacaqGSaGaaeiiaiaadAeacaqGYaGaamOr
aiaabodacaGGSaGaaeiiaiaadAeacaqGYaGaamOraiaabodacaqGRa
GaaeilaiaabccacaWGxbGaamyzaiaadkgacqGHsgIRcaWGgbGaaeOm
aiaadAeacaqGZaGaaeiiaiaabggacaqGUbGaaeizaiaabccacaWGxb
GaamyzaiaadkgacqGHsgIRcaWGgbGaaeOmaiaadAeacaqGZaGaae4k
aiaac6caaaa@5B0F@
For
g
6
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaI2aaabeaakiaacYcaaaa@3A09@
43 % will be attributed to
W e b → T e l 2+,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamivaiaadwgacaWGSbGaaeOmaiaabUcacaqG
Saaaaa@4119@
29% to
W e b → F 2 F 3
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamOraiaabkdacaWGgbGaae4maaaa@3F54@
and 29% to
W e b → F 2 F 3+ .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamOraiaabkdacaWGgbGaae4maiaabUcacaGG
Uaaaaa@40B4@
For
g
7
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaI3aaabeaakiaacYcaaaa@3A0A@
65% will be attributed to
F 2 F 3 +
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaaik
dacaWGgbGaaG4maiaabUcaaaa@3B76@
and 35% to
W e b → F 2 F 3+ .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamOraiaabkdacaWGgbGaae4maiaabUcacaGG
Uaaaaa@40B4@
For
g
8
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaI4aaabeaakiaacYcaaaa@3A0B@
100% will be attributed to
W e b → T e l 2 + .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamivaiaadwgacaWGSbGaaGOmaiaabUcacaGG
Uaaaaa@4123@
For
g
9
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaI5aaabeaakiaacYcaaaa@3A0C@
100% will be attributed to
W e b → F 2 F 3 .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamOraiaabkdacaWGgbGaae4maiaab6caaaa@4005@
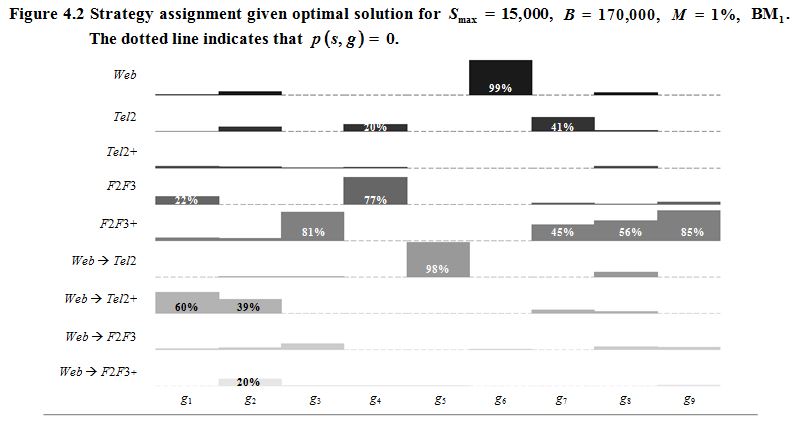
Description for Figure 4.2
Figure
that can be seen as a matrix where each row represents one of the strategies in
S
R
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaWefv3ySLgznf
gDOfdaryqr1ngBPrginfgDObYtUvgaiuaacqWFse=udaahaaWcbeqa
aiaadkfaaaaaaa@43E0@
and each column one of the nine strata,
g
1
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaIXaaabeaaaaa@394A@
to
g
9
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaI5aaabeaakiaacYcaaaa@3A0C@
described in Section 4.3. See
Section 4.2 and formula (4.1) for a list of the strategies and their
descriptions. For
g
1
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaIXaaabeaakiaacYcaaaa@3A04@
60 % will be attributed to
W e b → T e l 2+,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamivaiaadwgacaWGSbGaaeOmaiaabUcacaqG
Saaaaa@4119@
22 % to
F 2 F 3
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaabk
dacaWGgbGaae4maaaa@3A78@
and the rest to
W e b , T e l 2, T e l 2 + , F 2 F 3+ and W e b → F 2 F 3.
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaaiilaiaaysW7caWGubGaamyzaiaadYgacaqGYaGaaeil
aiaaysW7caWGubGaamyzaiaadYgacaqGYaGaey4kaSIaaeilaiaays
W7caWGgbGaaeOmaiaadAeacaqGZaGaae4kaiaabccacaqGHbGaaeOB
aiaabsgacaqGGaGaam4vaiaadwgacaWGIbGaeyOKH4QaamOraiaaik
dacaWGgbGaaG4maiaac6caaaa@58DB@
For
g
2
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaIYaaabeaakiaacYcaaaa@3A05@
39 % will be attributed to
W e b → T e l 2+,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamivaiaadwgacaWGSbGaaeOmaiaabUcacaqG
Saaaaa@4119@
20 % to
W e b → F 2 F 3+
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamOraiaabkdacaWGgbGaae4maiaabUcaaaa@4002@
and the rest to
W e b , T e l 2, T e l 2 + , F 2 F 3+, W e b → T e l 2 and W e b → F 2 F 3.
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaaiilaiaaysW7caWGubGaamyzaiaadYgacaqGYaGaaeil
aiaaysW7caWGubGaamyzaiaadYgacaqGYaGaey4kaSIaaeilaiaays
W7caWGgbGaaeOmaiaadAeacaqGZaGaae4kaiaabYcacaqGGaGaam4v
aiaadwgacaWGIbGaeyOKH4QaamivaiaadwgacaWGSbGaaGOmaiaabc
cacaqGHbGaaeOBaiaabsgacaqGGaGaam4vaiaadwgacaWGIbGaeyOK
H4QaamOraiaaikdacaWGgbGaaG4maiaac6caaaa@6237@
For
g
3
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaIZaaabeaakiaacYcaaaa@3A06@
81 % will be attributed to
F 2 F 3+
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaabk
dacaWGgbGaae4maiaabUcaaaa@3B68@
and the rest to
T e l 2 + , W e b → T e l 2, W e b → F 2 F 3 and W e b → F 2 F 3 + .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaeOmaiabgUcaRiaabYcacaaMe8Uaam4vaiaadwgacaWG
IbGaeyOKH4QaamivaiaadwgacaWGSbGaaeOmaiaabYcacaqGGaGaam
4vaiaadwgacaWGIbGaeyOKH4QaamOraiaaikdacaWGgbGaaG4maiaa
bccacaqGHbGaaeOBaiaabsgacaqGGaGaam4vaiaadwgacaWGIbGaey
OKH4QaamOraiaaikdacaWGgbGaaG4maiaabUcacaGGUaaaaa@5C49@
For
g
4
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaI0aaabeaakiaacYcaaaa@3A07@
77 % will be attributed to
F 2 F 3,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaabk
dacaWGgbGaae4maiaabYcaaaa@3B69@
20 % to
T e l 2
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaGOmaaaa@3B29@
and the rest to
T e l 2+ and W e b → F 2 F 3+ .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaeOmaiaabUcacaqGGaGaaeyyaiaab6gacaqGKbGaaeii
aiaadEfacaWGLbGaamOyaiabgkziUkaadAeacaqGYaGaamOraiaabo
dacaqGRaGaaiOlaaaa@48CD@
For
g
5
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaI1aaabeaakiaacYcaaaa@3A08@
98 % will be attributed to
W e b → T e l 2
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamivaiaadwgacaWGSbGaaeOmaaaa@3FBC@
and 2 % to
W e b → F 2 F 3+ .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamOraiaabkdacaWGgbGaae4maiaabUcacaGG
Uaaaaa@40B4@
For
g
6
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaI2aaabeaakiaacYcaaaa@3A09@
99 % will be attributed to
W e b
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbaaaa@3A66@
and 1 % to
W e b → F 2 F 3 .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamOraiaabkdacaWGgbGaae4maiaab6caaaa@4005@
For
g
7
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaI3aaabeaakiaacYcaaaa@3A0A@
45 % will be attributed to
F 2 F 3 +,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaaik
dacaWGgbGaaG4maiaabUcacaqGSaaaaa@3C25@
41 % to
T e l 2
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaGOmaaaa@3B29@
and the rest to
F 2 F 3 and W e b → T e l 2+ .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaaik
dacaWGgbGaaG4maiaabccacaqGHbGaaeOBaiaabsgacaqGGaGaam4v
aiaadwgacaWGIbGaeyOKH4QaamivaiaadwgacaWGSbGaaeOmaiaabU
cacaqGUaaaaa@482C@
For
g
8
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaI4aaabeaakiaacYcaaaa@3A0B@
56 % will be attributed to
F 2 F 3 +
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaaik
dacaWGgbGaaG4maiaabUcaaaa@3B76@
and the rest to
W e b , T e l 2, T e l 2 + , F 2 F 3 , W e b → T e l 2 , W e b → T e l 2 + and W e b → F 2 F 3.
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaaiilaiaaysW7caWGubGaamyzaiaadYgacaqGYaGaaeil
aiaaysW7caWGubGaamyzaiaadYgacaqGYaGaey4kaSIaaeilaiaays
W7caWGgbGaaGOmaiaadAeacaaIZaGaaiilaiaabccacaWGxbGaamyz
aiaadkgacqGHsgIRcaWGubGaamyzaiaadYgacaaIYaGaaiilaiaabc
cacaWGxbGaamyzaiaadkgacqGHsgIRcaWGubGaamyzaiaadYgacaaI
YaGaae4kaiaabccacaqGHbGaaeOBaiaabsgacaqGGaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamOraiaaikdacaWGgbGaaG4maiaac6caaaa@6BA3@
For
g
9
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaI5aaabeaakiaacYcaaaa@3A0C@
85 % will be attributed to
F 2 F 3+
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaabk
dacaWGgbGaae4maiaabUcaaaa@3B68@
and the rest to
F 2 F 3 , W e b → F 2 F 3 and W e b → F 2 F 3 + .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaaik
dacaWGgbGaaG4maiaacYcacaqGGaGaam4vaiaadwgacaWGIbGaeyOK
H4QaamOraiaaikdacaWGgbGaaG4maiaabccacaqGHbGaaeOBaiaabs
gacaqGGaGaam4vaiaadwgacaWGIbGaeyOKH4QaamOraiaaikdacaWG
gbGaaG4maiaabUcacaGGUaaaaa@50CF@
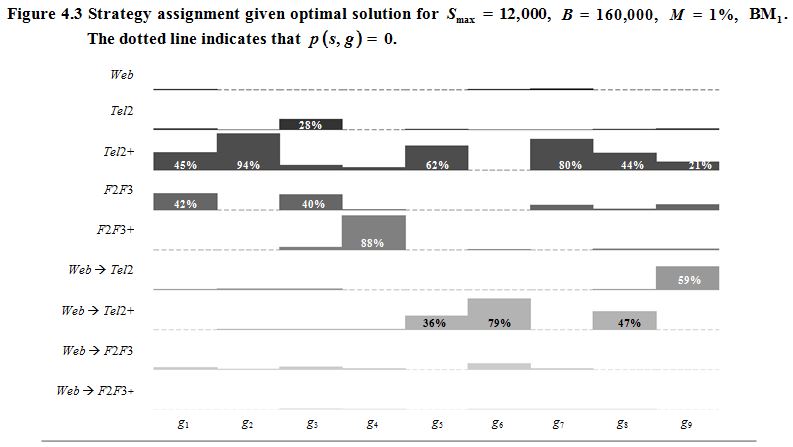
The impact of the available budget can be seen very
clearly for
S
max
= 12,000
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4uamaaBa
aaleaacaqGTbGaaeyyaiaabIhaaeqaaOGaeyypa0Jaaeymaiaabkda
caqGSaGaaeimaiaabcdacaqGWaaaaa@408B@
and
BM
1
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaaeOqaiaab2
eadaWgaaWcbaGaaGymaaqabaGccaGGSaaaaa@3AAD@
where the minimal overall method effect drops
from 0.10% for
B = 160,000
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOqaiabg2
da9iaabgdacaqG2aGaaeimaiaabYcacaqGWaGaaeimaiaabcdaaaa@3E2C@
to 0.01% for
B = 180,000 .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOqaiabg2
da9iaabgdacaqG4aGaaeimaiaabYcacaqGWaGaaeimaiaabcdacaGG
Uaaaaa@3EE0@
The optimal allocation probabilities are shown
in Figures 4.3 and 4.4. When increasing the budget, a shift takes place from
telephone only strategies to a mix of face-to-face only strategies and,
somewhat surprisingly, Web only strategies.
Description for Figure 4.3
Figure
that can be seen as a matrix where each row represents one of the strategies in
S
R
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaWefv3ySLgznf
gDOfdaryqr1ngBPrginfgDObYtUvgaiuaacqWFse=udaahaaWcbeqa
aiaadkfaaaaaaa@43E0@
and each column one of the nine strata,
g
1
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaIXaaabeaaaaa@394A@
to
g
9
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaI5aaabeaakiaacYcaaaa@3A0C@
described in Section 4.3. See
Section 4.2 and formula (4.1) for a list of the strategies and their
descriptions. For
g
1
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaIXaaabeaakiaacYcaaaa@3A04@
45 % will be attributed to
T e l 2 +,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaGOmaiaabUcacaqGSaaaaa@3C44@
42 % to
F 2 F 3
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaaik
dacaWGgbGaaG4maaaa@3A86@
and the rest to
W e b , T e l 2 , W e b → T e l 2 and W e b → F 2 F 3 .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaaiilaiaabccacaWGubGaamyzaiaadYgacaaIYaGaaiil
aiaabccacaWGxbGaamyzaiaadkgacqGHsgIRcaWGubGaamyzaiaadY
gacaaIYaGaaeiiaiaabggacaqGUbGaaeizaiaabccacaWGxbGaamyz
aiaadkgacqGHsgIRcaWGgbGaaeOmaiaadAeacaqGZaGaaeOlaaaa@54D4@
For
g
2
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaIYaaabeaakiaacYcaaaa@3A05@
94 % will be attributed to
T e l 2+
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaeOmaiaabUcaaaa@3BD0@
and the rest to
T e l 2 , W e b → T e l 2 and W e b → T e l 2 + .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaGOmaiaacYcacaqGGaGaam4vaiaadwgacaWGIbGaeyOK
H4QaamivaiaadwgacaWGSbGaaGOmaiaabccacaqGHbGaaeOBaiaabs
gacaqGGaGaam4vaiaadwgacaWGIbGaeyOKH4QaamivaiaadwgacaWG
SbGaaGOmaiaabUcacaqGUaaaaa@51F1@
For
g
3
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaIZaaabeaakiaacYcaaaa@3A06@
40 % will be attributed to
F 2 F 3,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaabk
dacaWGgbGaae4maiaabYcaaaa@3B69@
28 % to
T e l 2
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaGOmaaaa@3B29@
and the rest to
T e l 2 +, F 2 F 3 +, W e b → T e l 2 , W e b → T e l 2 + , W e b → F 2 F 3 and W e b → F 2 F 3 + .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaGOmaiaabUcacaqGSaGaaeiiaiaadAeacaaIYaGaamOr
aiaaiodacaqGRaGaaeilaiaabccacaWGxbGaamyzaiaadkgacqGHsg
IRcaWGubGaamyzaiaadYgacaaIYaGaaeilaiaabccacaWGxbGaamyz
aiaadkgacqGHsgIRcaWGubGaamyzaiaadYgacaaIYaGaey4kaSIaae
ilaiaabccacaWGxbGaamyzaiaadkgacqGHsgIRcaWGgbGaaGOmaiaa
dAeacaaIZaGaaeiiaiaabggacaqGUbGaaeizaiaabccacaWGxbGaam
yzaiaadkgacqGHsgIRcaWGgbGaaGOmaiaadAeacaaIZaGaae4kaiaa
b6caaaa@6A85@
For
g
4
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaI0aaabeaakiaacYcaaaa@3A07@
88 % will be attributed to
F 2 F 3+
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaabk
dacaWGgbGaae4maiaabUcaaaa@3B68@
and the rest to
T e l 2 +, F 2 F 3 , W e b → T e l 2 + , W e b → F 2 F 3 and W e b → F 2 F 3+ .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaGOmaiaabUcacaqGSaGaaeiiaiaadAeacaaIYaGaamOr
aiaaiodacaqGSaGaaeiiaiaadEfacaWGLbGaamOyaiabgkziUkaads
facaWGLbGaamiBaiaaikdacqGHRaWkcaGGSaGaaeiiaiaadEfacaWG
LbGaamOyaiabgkziUkaadAeacaaIYaGaamOraiaaiodacaqGGaGaae
yyaiaab6gacaqGKbGaaeiiaiaadEfacaWGLbGaamOyaiabgkziUkaa
dAeacaqGYaGaamOraiaabodacaqGRaGaaiOlaaaa@606F@
For
g
5
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaI1aaabeaakiaacYcaaaa@3A08@
62 % will be attributed to
T e l 2 + ,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaGOmaiabgUcaRiaacYcaaaa@3CBB@
36 % to
W e b → T e l 2 +
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamivaiaadwgacaWGSbGaaGOmaiaabUcaaaa@4071@
and 2 % to
T e l 2.
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaGOmaiaac6caaaa@3BDA@
For
g
6
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaI2aaabeaakiaacYcaaaa@3A09@
79 % will be attributed to
W e b → T e l 2 +
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamivaiaadwgacaWGSbGaaGOmaiaabUcaaaa@4071@
and the rest to
W e b , T e l 2 , F 2 F 3 +, W e b → F 2 F 3 and W e b → F 2 F 3 + .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaaiilaiaabccacaWGubGaamyzaiaadYgacaaIYaGaaeil
aiaabccacaWGgbGaaGOmaiaadAeacaaIZaGaae4kaiaabYcacaqGGa
Gaam4vaiaadwgacaWGIbGaeyOKH4QaamOraiaaikdacaWGgbGaaG4m
aiaabccacaqGHbGaaeOBaiaabsgacaqGGaGaam4vaiaadwgacaWGIb
GaeyOKH4QaamOraiaaikdacaWGgbGaaG4maiaabUcacaqGUaaaaa@5A3D@
For
g
7
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaI3aaabeaakiaacYcaaaa@3A0A@
80 % will be attributed to
T e l 2 +
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaGOmaiaabUcaaaa@3BD7@
and the rest to
W e b , T e l 2 , F 2 F 3 , W e b → F 2 F 3 and W e b → F 2 F 3 + .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaaiilaiaabccacaWGubGaamyzaiaadYgacaaIYaGaaeil
aiaabccacaWGgbGaaGOmaiaadAeacaaIZaGaaeilaiaabccacaWGxb
GaamyzaiaadkgacqGHsgIRcaWGgbGaaGOmaiaadAeacaaIZaGaaeii
aiaabggacaqGUbGaaeizaiaabccacaWGxbGaamyzaiaadkgacqGHsg
IRcaWGgbGaaGOmaiaadAeacaaIZaGaae4kaiaab6caaaa@598F@
For
g
8
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaI4aaabeaakiaacYcaaaa@3A0B@
47 % will be attributed to
W e b → T e l 2 + ,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamivaiaadwgacaWGSbGaaGOmaiabgUcaRiaa
cYcaaaa@4155@
44 % to
T e l 2 +
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaGOmaiaabUcaaaa@3BD7@
and the rest to
T e l 2 , F 2 F 3 , F 2 F 3 +, W e b → T e l 2 and W e b → F 2 F 3 + .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaGOmaiaabYcacaqGGaGaamOraiaaikdacaWGgbGaaG4m
aiaabYcacaqGGaGaamOraiaaikdacaWGgbGaaG4maiaabUcacaqGSa
GaaeiiaiaadEfacaWGLbGaamOyaiabgkziUkaadsfacaWGLbGaamiB
aiaaikdacaqGGaGaaeyyaiaab6gacaqGKbGaaeiiaiaadEfacaWGLb
GaamOyaiabgkziUkaadAeacaaIYaGaamOraiaaiodacaqGRaGaaeOl
aaaa@5AFF@
For
g
9
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaI5aaabeaakiaacYcaaaa@3A0C@
59 % will be attributed to
W e b → T e l 2 ,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamivaiaadwgacaWGSbGaaGOmaiaabYcaaaa@4072@
21 % to
T e l 2 +
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaGOmaiaabUcaaaa@3BD6@
and the rest to
T e l 2 , F 2 F 3 and F 2 F 3 + .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaGOmaiaabYcacaqGGaGaamOraiaaikdacaWGgbGaaG4m
aiaabccacaqGHbGaaeOBaiaabsgacaqGGaGaamOraiaaikdacaWGgb
GaaG4maiaabUcacaqGUaaaaa@47FA@
Description for Figure 4.4
Figure
that can be seen as a matrix where each row represents one of the strategies in
S
R
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaWefv3ySLgznf
gDOfdaryqr1ngBPrginfgDObYtUvgaiuaacqWFse=udaahaaWcbeqa
aiaadkfaaaaaaa@43E0@
and each column one of the nine strata,
g
1
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaIXaaabeaaaaa@394A@
to
g
9
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaI5aaabeaakiaacYcaaaa@3A0C@
described in Section 4.3. See
Section 4.2 and formula (4.1) for a list of the strategies and their
descriptions. For
g
1
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaIXaaabeaakiaacYcaaaa@3A04@
58 % will be attributed to
F 2 F 3+
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaabk
dacaWGgbGaae4maiaabUcaaaa@3B26@
and 42 % to
W e b .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaaiOlaaaa@3AD6@
For
g
2
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaIYaaabeaakiaacYcaaaa@3A05@
100 % will be attributed to
W e b → T e l 2+ .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamivaiaadwgacaWGSbGaaeOmaiaabUcacaqG
Uaaaaa@411B@
For
g
3
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaIZaaabeaakiaacYcaaaa@3A06@
67 % will be attributed to
F 2 F 3+,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaabk
dacaWGgbGaae4maiaabUcacaqGSaaaaa@3C17@
28 % to
W e b → F 2 F 3
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamOraiaabkdacaWGgbGaae4maaaa@3F54@
and 5 % to
F 2 F 3 .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaabk
dacaWGgbGaae4maiaab6caaaa@3B6B@
For
g
4
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaI0aaabeaakiaacYcaaaa@3A07@
73 % will be attributed to
F 2 F 3,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaabk
dacaWGgbGaae4maiaabYcaaaa@3B69@
22 % to
W e b → F 2 F 3+
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamOraiaabkdacaWGgbGaae4maiaabUcaaaa@4002@
and the rest to
F 2 F 3 + and W e b → F 2 F 3 .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaaik
dacaWGgbGaaG4maiaabUcacaqGGaGaaeyyaiaab6gacaqGKbGaaeii
aiaadEfacaWGLbGaamOyaiabgkziUkaadAeacaqGYaGaamOraiaabo
dacaGGUaaaaa@47C5@
For
g
5
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaI1aaabeaakiaacYcaaaa@3A08@
57 % will be attributed to
F 2 F 3 ,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaaik
dacaWGgbGaaG4maiaacYcaaaa@3B78@
32 % to
T e l 2 +
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaGOmaiaabUcaaaa@3BD7@
and the rest to
T e l 2 and F 2 F 3+ .
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaGOmaiaabccacaqGHbGaaeOBaiaabsgacaqGGaGaamOr
aiaabkdacaWGgbGaae4maiaabUcacaGGUaaaaa@438B@
For
g
6
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaI2aaabeaakiaacYcaaaa@3A09@
100 % will be attributed to
W e b .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaaiOlaaaa@3B18@
For
g
7
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaI3aaabeaakiaacYcaaaa@3A0A@
55 % will be attributed to
F 2 F 3 +
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaaik
dacaWGgbGaaG4maiaabUcaaaa@3B76@
and 45 % to
W e b → F 2 F 3.
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamOraiaaikdacaWGgbGaaG4maiaac6caaaa@4014@
For
g
8
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaI4aaabeaakiaacYcaaaa@3A0B@
63 % will be attributed to
W e b ,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaaiilaaaa@3B16@
31 % to
F 2 F 3 +
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaaik
dacaWGgbGaaG4maiaabUcaaaa@3B76@
and 6 % to
W e b → T e l 2 + .
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamivaiaadwgacaWGSbGaaGOmaiaabUcacaGG
Uaaaaa@4123@
For
g
9
,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4zamaaBa
aaleaacaaI5aaabeaakiaacYcaaaa@3A0C@
25 % will be attributed to
W e b → F 2 F 3 +,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamOraiaaikdacaWGgbGaaG4maiaabUcacaqG
Saaaaa@40BF@
21 % to
T e l 2 ,
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamivaiaadw
gacaWGSbGaaGOmaiaacYcaaaa@3BD8@
20 % to
W e b ,
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaaiilaaaa@3B16@
20% to
F 2 F 3+
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrVeFfea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaamOraiaabk
dacaWGgbGaae4maiaabUcaaaa@3B68@
and the rest to an of the other strategies.
A range of scenarios can be investigated using a wide
range of threshold values, which we leave to other papers. We conclude by
mentioning that optimal allocations with many small allocation probabilities
lead to very intractable data collection processes. Lower thresholds to the
allocation probabilities may be added to avoid strategies that get only small
numbers of cases.
4.6 Robustness
of optimal designs
In this section, we briefly discuss the robustness of
the optimal designs. Sensitivity analyses are beyond the scope of this paper
and are part of current research.
In the estimation of the response propensities,
telephone registration propensities, costs per sample unit and adjusted methods
effects, we make four main assumptions; apart from assumptions about the
logistic link function between response
−
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaeyOeI0caaa@3864@
nonresponse, telephone registration
−
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaeyOeI0caaa@3864@
no registration and auxiliary variables. These
are:
Model for
W
e
b
→
F
2
F
3
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamOraiaaikdacaWGgbGaaG4maaaa@3F1F@
and
W
e
b
→
F
2
F
+
:
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaam4vaiaadw
gacaWGIbGaeyOKH4QaamOraiaaikdacaWGgbGaaGzaVlabgUcaRiaa
ykW7caGG6aaaaa@4317@
these two strategies have only been employed
for households without a listed phone number.
Strategies with cap on calls estimated using
censoring: The strategies with a cap on calls have not been conducted and we
assume that their response propensities and costs can be approximated by
censoring strategies with the full contact strategy.
Costs linear in size allocated to strategies:
We assume that costs per sample unit do not depend on the size of the sample
allocated to a strategy.
Time stability of methods effects during
2010
−
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaeyOeI0caaa@3864@
2012: Since the
parallel runs were performed in two steps, the method effects for some
strategies were estimated in two steps. We implicitly assume that the methods
effects for these designs have not changed over 2010
−
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGaeyOeI0caaa@3864@
2012.
Furthermore, all estimated input parameters are subject
to sampling variation. Consequently, we expect that certain variations in the
optimal designs might occur due to inaccuracy of parameters. In order to assess
robustness of optimal designs we propose two types of sensitivity
analysis:
•
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9IqqrpepC0xbbL8F4rqqr=hbbG8pue9Fbe9q8
qqvqFr0dXdbrVc=b0P0xb9peuD0xXddrpe0=1qpeea0=yrVue9Fve9
Fve8meaabaqaciGacaGaaeWabaWaaeaaeaaakeaaruWqHXwAIjxAaG
qbaKqzGfaeaaaaaaaaa8qacaWFIacaaa@3B2A@
Repeated
optimization for input parameters obtained from resampled data. In other words,
all historical data are resampled multiple times and for each draw an
optimization is performed. The resulting optimal values for quality and costs
as well as the strategy composition of the optimal designs can thus be compared
across the various draws.
•
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9IqqrpepC0xbbL8F4rqqr=hbbG8pue9Fbe9q8
qqvqFr0dXdbrVc=b0P0xb9peuD0xXddrpe0=1qpeea0=yrVue9Fve9
Fve8meaabaqaciGacaGaaeWabaWaaeaaeaaakeaaruWqHXwAIjxAaG
qbaKqzGfaeaaaaaaaaa8qacaWFIacaaa@3B2A@
Performance
evaluation of the optimal design on resampled data. In other words, given
observed historical data, an optimization is performed. All historical data are
then resampled and for each draw the optimization input parameters are
recomputed. The optimal design is applied to each set of input parameters and
the corresponding quality and cost values are computed. Finally, the
statistical properties of quality and cost values are assessed across all draws
of input parameters.
Exploratory sensitivity analyses show that there is
relatively large variation in the strategy composition of the optimal designs,
but that optimal method effects
D
¯
BM
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiFu0Je9sqqrpepC0xbbL8F4rqqrpipeea0xe9Lq=Je9
vqaqFeFr0xbba9Fa0P0RWFb9fq0FXxbbf9=e0dfrpm0dXdirVu0=vr
0=vr0=fdbaqaaeGacaGaaiaabeqaamaabaabaaGcbaGabmirayaara
WaaWbaaSqabeaacaqGcbGaaeytaaaaaaa@3A1A@
are very stable. This implies that the method
effect, as objective function, is a relatively smooth function.
Editorial policy
Survey Methodology
Submission of Manuscripts
Survey Methodology statcan.smj-rte.statcan@canada.ca , Statistics Canada, 150 Tunney’s Pasture Driveway, Ottawa, Ontario, Canada, K1A 0T6). For formatting instructions, please see the guidelines provided in the journal and on the web site (www.statcan.gc.ca/SurveyMethodology).
Note of appreciation
Canada owes the success of its statistical system to a long-standing partnership between Statistics Canada, the citizens of Canada, its businesses, governments and other institutions. Accurate and timely statistical information could not be produced without their continued co-operation and goodwill.
Standards of service to the public
Statistics Canada is committed to serving its clients in a prompt, reliable and courteous manner. To this end, the Agency has developed standards of service which its employees observe in serving its clients.
Copyright
Published by authority of the Minister responsible for Statistics Canada.
© Minister of Industry, 2015
Catalogue no. 12-001-X
Frequency: semi-annual
Ottawa
Date modified:
2017-09-20