
Figure 1
Flowchart of how the PCCF plus matches individuals in a user-supplied postal code dataset to subsets of PCCF records
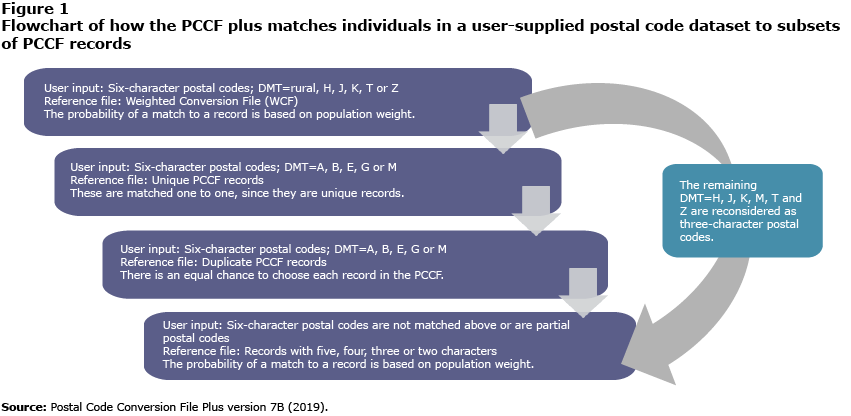
Description for Figure 1
This is a flow chart that explains how the Postal Code Conversion File Plus selects records from the source file, the Postal Code Conversion File. The flow chart comprises four boxes, which indicate the order in which this process occurs.
The first box describes the first step, where postal codes of delivery mode type H, J, K, T, or Z are matched to a weighted conversion file using population weights.
The second box describes the second step, where postal codes of delivery mode type A, B, E, G, or M with unique records on the Postal Code Conversion File are matched one to one to the file.
The third box describes the third step, where postal codes of delivery mode type A, B, E, G, or M with duplicate records on the Postal Code Conversion File are matched randomly to one of the records for the postal code.
The fourth box describes the fourth step, where postal codes that are not yet matched to the Postal Code Conversion File or have a partial postal code are matched to reference files, using population weights.
A grey arrow with a box indicates a possible shortcut between the first step and the last step, in that remaining postal codes from the first step with delivery mode type H, J, K, M, T, or Z are reconsidered in the last step as three-character postal codes. Source for the flowchart is as follows:
Source: Postal Code Conversion File Plus version 7B (2009).
- Date modified: