
Income and Expenditure Accounts Technical Series
Annual Household Distribution Tables, Provisional estimates of asset, liability and net worth distributions, 2010 to 2016, Technical methodology and quality report

Archived Content
Information identified as archived is provided for reference, research or recordkeeping purposes. It is not subject to the Government of Canada Web Standards and has not been altered or updated since it was archived. Please "contact us" to request a format other than those available.
1 Overview
The global economy has undergone significant structural shifts in recent years due in part to the 2008 global financial crisis and rising levels of globalization. The impact of macroeconomic shifts on households has become a major focus for policymakers as inequality and financial stability become common themes on the international stage. Statistics Canada and other statistical agencies can help expand the body of scholarly research on this topic by publishing more comprehensive, relevant, and detailed data on national financial inequality.
Statistics Canada has undertaken development of new data sets that describe household net worth distributed according to various characteristics of households in order to more specifically define who holds wealth in Canada. This new data will provide policymakers and academics with new tools to examine inequality and its impact on our society. This new data is referred to as the Annual Household Distribution Tables (AHDT).The AHDT data will bring together the detail available from micro data sources with the SNA concepts covered by macro data which have fuller coverage and are internationally comparable. The main micro data source is the Survey of Financial Security (SFS), a household survey that collects information on assets, debts, and wealth (net worth). The SFS is not an annual survey, and so a different methodology is required in survey years and in non-survey years.
This paper presents in detail the methodology used to develop provisional distributions of household net worth for the reference years 2010 to 2016. It begins with a description of the international framework of the OECD Expert Group on Disparities within the National Accounts (EG DNA) which provides recommendations on producing distributional information aligned with System of National Accounts concepts; followed by Statistics Canada’s implementation of each step. These include the adjustments to the National Accounts totals; a description of the micro-data sources; the methodology for the derivation of indicators in survey years and non-survey years; and a description of the potential sources of error. A large section of the paper focuses on the methodology for years in which survey data is not available. In these years, modelling is required to derive wealth distributions. The modelling approach will be described as well as the various adjustments required to ensure internal consistency of the tables and consistency with the macroeconomic totals.
This is the beginning stage of progress for an integrated framework of distributions including income, consumption, savings and wealth. The tables produced using this methodology are provisional in nature and will be subject to revisions as the methodology is refined.
2 Introduction
Statistics Canada regularly publishes macroeconomic indicators on household assets, liabilities and net worth as part of the quarterly National Balance Sheet Accounts (NBSA). These accounts are aligned with the most recent international standards and are the source of estimates of national wealth for all sectors of the economy, including households, non-profit institutions, governments and corporations along with Canada’s wealth position vis-a-vis the rest of the world. While the NBSA provide high quality information on the overall position of households relative to other economic sectors, they lack the granularity required to understand vulnerabilities of specific groups and the resulting implications for economic wellbeing and financial stability.
There is a growing recognition, both in Canada and internationally, that building distributional dimensions into household macroeconomic indicators is becoming increasingly important. If information on disparities among households is consistent with macroeconomic indicators, it enriches the understanding of economic developments and allows for a fuller assessment of the risks associated with for example, rising inequality of income, consumption, saving and wealth.
Recent comprehensive revisions to the Canadian System of Macroeconomic Accounts published in 2012 and 2015 better positioned the macroeconomic statistical program to undertake this work. Changes were introduced to align measures with new international standards, including the creation of a separate sector for non-profit institutions serving households, (previously included in the household sector) and the measurement of employer-sponsored pensions on an entitlement basis. More detail on the changes made during the revisions in 2012 and 2015 can be found in Revisions analysis – Canadian System of National Accounts 2012 and Results from the 2015 Comprehensive Revision to the Canadian System of Macroeconomic Accounts.
This documentation outlines a first step towards a fuller program of annual distributional estimates for the household sector in the Canadian macroeconomic accounts. This documentation also presents the methodology used to develop, in the Annual Household Distribution Tables (AHDT), provisional distributions of wealth for the household sector of the National Balance Sheet Accounts (NBSA) for the reference years 2010 to 2016. It describes the technical details of the methodology and includes a report on the quality of the estimated distributions. These estimates will be further developed and refined prior to their official release by Statistics Canada as part of the ongoing statistical program. Subsequent releases will expand the suite of distributional estimates to macroeconomic indicators of household income, consumption and saving.
3 International framework
In order to produce distributional information aligned with System of National Accounts (SNA) concepts, Statistics Canada follows the basic steps recommended by the OECD Expert Group on Disparities within the National Accounts (EG DNA). Statistics Canada’s implementation of each step will be described in detail in the subsequent sections. The third step was not required in producing the AHDT. Instead, scaling and other adjustments were performed to the macro data after step 4, which are described in sections 7.2, 8.2 and 8.4.

Description of Figure 1
A step-by-step approach for the estimation of distributional information, provided by the EG DNA
Step 1. Adjust national account totals.
Step 2. Determine relevant variables from micro sources in relation to the national accounts variables.
Step 3. Impute for missing elements and scale the micro data to the adjusted national accounts totals.
Step 4. Cluster households.
Step 5. Derive relevant indicators for the household groups.
4 Adjust the national accounts totals
4.1 National Balance Sheet Accounts
The National Balance Sheet Accounts (NBSA) are statements of the non-financial assets owned/used in the economy and of the financial claims outstanding among the economic units in the economy. They consist of the National Balance Sheet for the nation as a whole, as well as the underlying sector balance sheets. At the core of the NBSA are assets and liabilities and the concepts of wealth and net worth.
The AHDT focusses specifically on the household sector of the national balance sheet. This covers the assets, liabilities, and net worth (including some sub-categories) of all households in Canada.
4.2 Adjustments
The OECD recommends isolating the household sector for distributional analysis; a process that may require adjusting the National Accounts sector total if it has been aggregated with the Non-Profit Institutions Serving Households (NPISH) sector.
Prior to the comprehensive revision in 2012, there were three main resident institutional sectors in the Canadian System of National Accounts (SNA): the persons and unincorporated business sector, the corporate sector and the government sector. The persons and unincorporated business sector included non-profit institutions serving households (NPISH), credit unions, life insurance companies, fraternal organizations and collective investment schemes such as pension plans and mutual funds. Due to data limitations, this sector also encompassed activities of aboriginal governments.
With the 2012 comprehensive revision, the Canadian SNA adopted the basic SNA institutional sectoring detail throughout the sequence of integrated accounts. The former persons and unincorporated business sector was split between households and non-profit institutions serving households.
Given this work already done to isolate the household sector, no adjustments need to be made to the current NBSA data.
5 Identifying microdata sources and variables
5.1 Survey of Financial Security
The microdata source identified for the distribution of net worth is the Survey of Financial Security (SFS). The purpose of the survey is to collect information from a sample of Canadian families on their assets, debts, employment, income and education. This helps in understanding how family finances change because of economic pressures. The SFS provides a comprehensive picture of the net worth of Canadians. Information is collected on the value of all major financial and non-financial assets and on the money owing on mortgages, vehicles, credit cards, student loans and other debts. A family's net worth is defined as the value of a family’s assets minus their debt and can be thought of as the amount of money they would be left with if they sold all of their assets and paid off all of their debts.
The SFS is a sample survey with a cross-sectional design. It has been conducted on an occasional basis, in 1999, 2005, and 2012, and will be triennial as of 2016. The SFS covers the population living in the ten provinces of Canada. Within the provinces, certain groups (for instance, persons living on reserves or other Aboriginal settlements and chronic care patients living in hospitals or nursing homes) representing about 2% of the population are excluded.
Over the years, the SFS sample size and design has varied. The initial sample size was approximately 23,000 dwellings in 1999, 9,000 dwellings in 2005, and 20,000 dwellings in 2012. In 1999 and 2012, provincial estimates were targeted but, with the sample size reduced significantly for budgetary reasons in 2005, that iteration of the survey focused on producing reliable estimates at the regional level.
Data are generally collected directly from respondents, while in some cases additional information is extracted from administrative files and derived from other Statistics Canada surveys and other sources via record linkage. Examples include the use of personal tax data records and regulatory information on the terms and conditions of employer-sponsored pension plans. Interviews are conducted via Computer-Assisted Personal Interviewing (CAPI) with an average interview length of approximately 45 minutes.
The survey is not mandatory and the response rate in 2012 was 68.6%.
More information can be found under Definitions, data source and methods for SFS (survey number 2620) and CANSIM table 205-0002.
5.2 Mapping and concordance
The full National Balance Sheet Accounts (NBSA) are comprised of 102 categories and sub-categories that contain all types of assets, liabilities and net worth in the economy. The provisional Annual Household Distribution Tables (AHDT) data will contain 11 of these categories. The NBSA categories were simplified for multiple reasons. One reason is that some types of assets and liabilities are not applicable in the household sector. Another reason is related to the quality of distributions which will be discussed in more detail in subsequent sections of this paper.
According to the United Nations Economic Commission for Europe (UNECE); “conceptually, macro and micro statistics on household income have much in common. However, there are significant differences in the objectives and purposes of the two datasets, in their coverage and the data sources used to compile them, and because of practical data reporting or estimation issues for individual households” (UNECE 2011). The concordance process allows for the identification of areas of conceptual difference between micro- and macro data and provides an indicator of the suitability of specific microdata variables as distributors of macro components.
The categories from the NBSA chosen for the AHDT are laid out in Table 1 below. The coverage ratios are shown for the latest year in which the SFS was conducted, 2012. These categories contain sufficient detail for analysis of household financial well-being while also being at a high enough aggregate that the distributions may be modelled in years for which there is no complementary micro data to the national accounts (non-survey years). These are the categories for which a suitable variable (or combination of variables) from the Survey of Financial Security has been identified. The concordance found in Table 1 was built by mapping variables from the SFS to a condensed version of the NBSA, the detail of which variables from each source were used to create this table are found in Table 2 below. Some details relating to the mapping in Table 2 are in sections 5.2.1 to 5.2.2.
5.2.1 Conceptual differences – valuables and collectibles
Valuables and collectibles are not an observed category in the NBSA and are not currently a part of the macro accounts asset boundary. Therefore, in order to align the micro source with the macro source the value of valuables and collectibles has been removed from the SFS total for net worth and non-financial assets.
5.2.2 Conceptual differences – other liabilities
The category with the lowest coverage ratio is ‘other liabilities’. The main reason for the under coverage of this category is due to the conceptual definition of credit card debt which is mapped to this category. The SFS asks respondents to report the amount of credit card debt that carries over to another period, while the NBSA reports the total balance outstanding at a specific point in time. The difference reflects the fact that many households use credit cards for consumption, but pay off their balance at the end of each period.
5.3 T1 Family File
Since SFS data are not available on an annual basis, the methodology used to produce the provisional wealth tables includes a modelling component. The auxiliary information used for these models is the Annual Income Estimates for Census Families and Individuals, commonly called T1 Family File (T1FF), an annual administrative data file created by Statistics Canada primarily from income tax returns submitted to the Canada Revenue Agency (CRA). These microdata cover all persons who completed a T1 tax return for the year of reference or who received CCTB (Canada Child Tax Benefits), along with their spouses and children. More information about Annual Income Estimates for Census Families and Individuals (T1 Family File) (survey number 4105) can be found under Definitions, data source and methods.
6 Clustering households
6.1 Unit of analysis: the household
The unit of analysis chosen for Annual Household Distribution Tables (AHDT) is the household, defined by the OECD as “either an individual person or a group of persons who live together under the same housing arrangement and who combine to provide themselves with food and possibly other essentials of living” (OECD 2013). The SFS data is available at the family unit level, which is comprised of unattached individuals and economic families defined as “a group of two or more persons who live in the same dwelling and are related to each other by blood, marriage, common-law or adoption” (Statistics Canada 2014). For the AHDT project the economic family units have been aggregated to the household level by combining economic families that reside at the same address, which creates a unit definition that includes groups of people who share resources but are not necessary related by blood, marriage, common-law or adoption. This brings the SFS data as close as possible to the OECD definition of household.
Related to this concept is the OECD recommendation to estimate distributions based on equivalised household values. This process takes into account differences in household size and the resulting economies of scale for income and consumption. Wealth data presented in the provisional estimates has not been equivalised. This will be investigated for future releases, when an integrated picture of income, consumption and wealth distributions is developed.
6.2 Distribution categories
Provisional Annual Household Distribution Tables for assets, liabilities and net worth include four separate distribution variables. Households are grouped by province, household disposable income quintile, age group, and household type (multiple-person vs. one-person). With the exception of household disposable income, these groupings are based on definitions used in the 2012 SFS.
6.2.1 Provinces
The province represents that of the principal residence of the household. Household members that are temporarily away from their principal residence, for instance for work or study, are included in the province of their principal residence.
6.2.2 Age groups
Households are grouped into age groups according to the age of the major income earner as identified by the SFS. This differs from the OECD definition of a reference person for a household, which requires applying a number of characteristic criteria to each member of each household. This approach will be reviewed as the methodology is further developed.
The age group categories used are: under 35, 35 to 44, 45 to 54, 55 to 64, and 65 and over.
6.2.3 Household type
Grouping by household type is done according to a simplified definition of household composition, with only two categories: households composed of one person and households composed of more than one person. This simplified version is used in order to have similar definitions on both the SFS data and the auxiliary data source used for modelling distributions for non-survey years.
6.2.4 Household disposable income quintiles
The household disposable income concept is unique to the System of National Accounts (SNA) and is not measured directly in the SFS. In order to assign SFS households to disposable income quintiles, disposable income must first be estimated for each household on the 2012 SFS as follows:
- The SNA household disposable income aggregate is broken down into components (for example compensation of employees, transfers to and from other sectors, etc.) for which corresponding variables or proxies can be found on the SFS.
- For each of these components, the SNA aggregate value is distributed over SFS households according to the value of the corresponding SFS variable or proxy. SFS survey weights are taken into account when calculating each household’s share of the component.
- For each household, the distributed components are summed up to calculate the household’s estimated disposable income.
The result is a new income variable for each SFS household, more closely aligned with the SNA concept of household disposable income than the available measure of after-tax income. Household disposable income is nevertheless highly correlated with after-tax income excluding capital gains, with a coefficient of correlation of 92.7%. This is an important feature for modelling disposable income distributions in non-survey years. Once every SFS household has been assigned a household disposable income, the households are grouped into household disposable income quintiles, which again are calculated taking into account the SFS weights.
7 Deriving indicators in survey years
The provisional wealth tables are all of the form shown in Table 3, with National Balance Sheet Accounts (NBSA) totals in the right hand column (indicated by C) that are split over the various distribution categories: provinces, household disposable income quintiles, age groups, and household types. The distribution columns (indicated by A and B) are completed based on microdata.
The Survey of Financial Security (SFS) is the main source of distribution information for the Annual Household Distribution Tables (AHDT) for wealth. However, the SFS has been an occasional survey in the past and will be triennial beginning in 2016. This leaves gaps that need to be filled in order to produce a series of annual tables. The proposed methodology for deriving these tables is two-fold, with a simpler, more direct approach being used in survey years and a more complex model-based approach being required in non-survey years. (The modeling approach for cells indicated by A and B differ as described in section 8.) Throughout this section and the next, tables will be given to show how much each step of the process modifies the estimates.
This section describes the methodology used to populate the tables in survey years. It consists of two steps: obtaining distribution estimates from SFS which are scaled to NBSA totals, and raking to produce tables in which rows and column totals are coherent. For this preliminary set of tables, this methodology is used only for 2012. Going forward, this process would be used for every survey year.
7.1 Distribution estimates
For each of the four tables, the total values of net worth and of each of the asset and liability subcategories for each distribution category is estimated directly from SFS. For these estimates, measures of sampling error in the form of coefficients of variation (CVs) are in the appendix in Tables 10 to 13. The CVs range from 1.8% to 12.4% for total net worth, from 1.7 to 10.9% for total assets, and from 2.3% to 15.6% for total liabilities.
These survey totals are scaled to the NBSA totals. The factor by which each cell must be multiplied varies by row and is the reciprocal of the coverage ratios given above in Table 1. This factor is the same for all four of the provisional tables.
Table 4 is the first of a series of tables showing how much the cells of the tables are modified by each step of the methodology. In this case, most of the scaling factors are close to 1, an indication that the modifications are not large for most categories. Conceptual differences between the NBSA totals and SFS means that a larger factor is required for the “Other liabilities” line, as explained in section 5.2.2.
7.2 Raking
After scaling survey estimates to NBSA totals, the row and column sums of the resulting tables are not coherent. The sum of the distribution categories will be equal to the NBSA totals; in other words, the row sums will be coherent. However, the relationships between assets, liabilities and net worth will not be respected; in other words, the column sums will not be coherent. This occurs because different scaling factors are used for each row. An adjustment process is required to ensure consistency within the resulting tables. This re-establishes the relationships between assets, liabilities, net worth, etc. within each distribution category (relationships down the columns of the tables); while ensuring that the sum of the distribution categories are kept equal to the NBSA total (relationships across rows); and leaves the NBSA totals and net worth/wealth lines untouched. This type of adjustment goes by many names: raking, balancing, and reconciliation. A key characteristic of raking is that it ensures that specified relationships are respected while minimizing the change to individual cells of the table.
The raking variant that has been used to produce the preliminary table uses alterability coefficients to allow some quantities to move more than others do. In general, it may be desirable to allow estimates that are deemed to be of lower quality to move more. In this case, the values in rows whose coverage ratios are farther from 100% are allowed to vary more than rows with coverage ratios close to 100%. The raking methods used are derived from the Dagum and Cholette (2006) regression-based approach and are further described in Quenneville and Fortier (2012) and the references therein. The procedures are implemented in PROC TSRAKING, described in Bérubé and Fortier (2009), as part of Statistics Canada’s G-SERIES software and can be obtained by contacting statcan.g-series-g-series.statcan@canada.ca.
Tables 19 to 22 in the appendix show by how much raking modifies the internals cells of the 2012 wealth tables. As with the scaling ratios above, the ratios in these tables are generally close to 1, indicating that raking the tables does not result in major changes to the distributions. One of the reasons for limiting these provisional tables to 11 categories and sub-categories of wealth is to ensure that raking would not modify the cells too much.
8 Deriving indicators in non-survey years
Since the Survey of Financial Security (SFS) is not undertaken annually, a different methodology is required to derive wealth measures for the Annual Household Distribution Tables (AHDT) in years for which survey information is not available. Without a direct measure of net worth and its components, the non-survey years must be modelled based on auxiliary information. As in survey years, every table is of the form shown in Table 3, though in non-survey years the distribution columns are derived from models. A different modelling approach is used for the distribution of net worth (indicated by B) and the distribution of asset and liability categories and subcategories (indicated by A).
The bulk of this section, 8.1 to 8.4, will cover the methodology developed to estimate the distributions of net worth for non-survey years. In particular, it gives a description of the area-level modelling approach used to estimate net worth, a description of the benchmarking that is used to ensure coherence with survey years, and the alternative modelling approach that is needed for 2015 and 2016. Following this, the approach for the interior of the table is described in 8.4. Here, a simpler modelling approach is used and, as in survey years, coherence of tables is ensured by raking. Lastly, section 8.5 describes alternative modelling approaches for net worth that were evaluated while developing the AHDT methodology and includes comparisons to the selected area-level modelling approach. Throughout the section, tables are given to show how much each step of the process modifies the estimates.
8.1 Area-level models of net worth
This approach of estimating net worth is based on models that predict the net worth of groups or "areas" of households. It is motivated by the area-level models that are a standard small area estimation technique (Rao and Molina 2015). Area-level models are so-called because the units over which the model is fit is a set domains of interest that are often geographic areas.
This method was evaluated against two alternatives, a macro-level approach and a unit-level approach. These three were evaluated and compared with the area-level being identified as the most appropriate approach based on its ability to predict the distribution of net worth. A description of the alternative methods and a summary of the comparison is presented in section 8.5.
8.1.1 Impact of data sources and their availability
As mentioned above, the Survey of Financial Security has only been undertaken three times in the past, in 1999, 2005 and 2012. This gives a very short data series with which to work to construct tables for 2010 to 2016. Moreover, two of the available SFS years, 1999 and 2005, cannot be considered timely, especially with the 2008 financial crisis which occurred in the interim, and the 2005 SFS has a substantially smaller sample and was designed to produce regional rather than provincial estimates.
Fortunately, wealth is linked to income, and there is much more data available on income. The T1 Family File (T1FF) is an evident choice of auxiliary microdata since it is available annually and since the individual-level data can be readily grouped into families. However, the T1FF becomes available approximately one year and a half after the end of the reference year. The 2014 T1FF is the latest version available for this production of provisional tables covering reference years 2010 to 2016. As a result, a different methodology will be used for 2015 and 2016 than for 2010 to 2014.
8.1.2 Modelling approach
The methodology for estimating distributions of net worth in non-survey years using area-level models is as follows:
- The country is divided into domains over which the variable of interest, total net worth, is aggregated from the 2012 SFS data. Domains are defined by crossing geographic areas with the distribution categories of interest.
- A model is fit over these domains predicting total net worth based on auxiliary information that is available for those domains. The variables used as predictors are T1FF variables that have been aggregated over the domains. This is done using the 2012 reference year for both the SFS and the T1FF.
- This model is then applied to all years where the auxiliary data is available (2010 to 2014) giving an estimated total net worth for every domain in both survey and non-survey years.
- Finally, the modelled distributions for the wealth tables are obtained by summing estimated total net worth over the relevant domains.
Experience from small area estimation suggest that an area-level approach may be especially helpful when coverage of the auxiliary data source is not complete or when there are conceptual differences between the survey and auxiliary data. This is the case for the T1FF; the T1FF's coverage of the Canadian population is quite good but not perfect as conceptual differences between data sources do exist. For example, the SFS is aggregated to the household level for the ADHT while the T1FF groups individuals into families. Similarly, the AHDT use the SNA household disposable income concept while the T1FF contains tax-based definitions of total income.
Though only information derived from the T1FF has been included in the models at this point, another advantage of area-level models is that they can incorporate auxiliary information that is only available at aggregate levels. This option will be evaluated as methods are refined for later publication of official estimates.
Development work to determine the best implementation of this approach is on-going. The implementation used for the provisional wealth tables is described below. Three models were fit: one for household disposable income, one for age groups, and one for household composition. The options selected for implementation were chosen by comparing the modelled distributions to the SFS distributions for 2012, 2005, and 1999 (see section 8.1.7).
8.1.3 Modelling Period
All models were built using 2012 data only. The 2005 and 1999 SFS were deemed not timely enough to be used for the 2010 to 2016 period. These previous iterations of SFS were used only to evaluate the models fit on 2012 data.
8.1.4 Domain Definition
The domains are defined by crossing 49 geographic areas with the distribution categories of the wealth tables. The 49 geographic areas are based on economic regions, with some neighbouring economic regions being combined when necessary.
With the domains defined over two dimensions, geography and distribution category, the models could be fit on all domains together or over the 49 geographic areas for each of the distribution categories individually. The second option was implemented, as it gave better results. It allows for different relationships between net worth and income covariates in each distribution category. Taking age groups as an example, this amounts to saying that the relationship between income variables and net worth is different by age group, which is reasonable since net worth is accumulated over a person’s lifetime.
8.1.5 Covariates and Linking Function
All covariates for the model were derived from the T1FF for reference year 2012. The T1FF contains a variety of demographic, income and income-related variables, and many ways of aggregating them over the domains were considered. The variables retained for modelling total net worth within each domain were: total income, total of absolute value of investment income, total income of persons of age 75 and older. Total income was the strongest variable and it is used in every model. Though the variables used are based on income, demographic trends are also captured by the models since totals also reflect population size.
The implemented models make use of a logarithmic linking function, with the log applied to both the variable of interest, total net worth, and the covariates. In the resulting model, the predicted log of total net worth is as a linear combination of the log of total income, potentially the log of additional covariates, and a constant term.
The use of a logarithmic linking function results in a biased estimator. No specific bias correction is introduced since benchmarking is used to align modelled distributions with the SFS distributions in survey years.
8.1.6 Province model
As mentioned above, three models were fit: one for household disposable income quintiles, one for age groups, and one for household composition. Since the geographic areas used to define the domains over which the area-level models were fit respect provincial boundaries, each of these three models can be used to derive a distribution by provinces. All three models gave similar distributions by provinces. For the provisional wealth table by provinces, the modelled province distribution was obtained by taking the average of the three models.
8.1.7 Comparison of implemented models to the SFS distributions
The following tables show how the modelled distributions compare to the SFS distributions in 2012, 2005, and 1999. The sum of the absolute differences by category between the SFS distribution and modelled distribution is shown as a measure of distance between the SFS distributions and those obtained by modelling.
As can be seen in Tables 5 to 8, even in 2012, the year on which the model was built, there is a difference between the SFS distribution and the model output. This discrepancy, which is partly due to the use of a log linear model, will be addressed through benchmarking.
8.2 Benchmarking net worth estimates
Benchmarking refers to techniques used to ensure coherence between time series data measured at different frequencies. In this case, the annual distribution series produced by the model is adjusted to be coherent with the SFS in survey years. It consists of imposing the level of the benchmarks while preserving the movement in the modelled series as much as possible. For the provisional tables, the modelled series was only benchmarked to the 2012 SFS distributions. When the series is expanded to include other survey years, the model outputs will be benchmarked to every survey year. The benchmarking methods used are derived from the Dagum and Cholette (2006) regression-based approach and are further described in Quenneville and Fortier (2012) and the references therein. The procedures are implemented in PROC BENCHMARKING, described in Latendresse, Djona and Fortier (2007), as part of Statistics Canada’s G-SERIES software and can be obtained by contacting statcan.g-series-g-series.statcan@canada.ca.
In certain situations, benchmarking can improve the accuracy of the output. In this situation, benchmarking is being used as a way to compensate for the bias resulting from the use of a log model.
Tables 15 to 18 in the appendix show the magnitude of the benchmarking adjustments to the net worth distributions. These adjustments are applied to each year from 2010 to 2014.
8.3 Net worth estimates for 2015 and 2016
The net worth modelling methodology described in sections 8.1 and 8.2 can only be applied in years for which the T1FF is available: 2010 to 2014. For the years 2015 and 2016, the 2014 distribution is carried forward to obtain net worth estimates. As a result, the provisional wealth tables show the same distribution for net worth in 2014, 2015, and 2016.
8.4 Including asset and liability categories in non-survey years and raking
In addition to net worth, specific asset and liability categories must also be modelled for non-survey years. Once modelled, the distributions are scaled to NBSA totals and the resulting tables raked to ensure consistency within each table, just as in survey years. Raking to table margins will transfer some of the distribution trends captured by the net worth model to the interior of the table. For this reason, a simple model for asset and liability categories was deemed acceptable. The provisional wealth tables were constructed by simply carrying forward or backward the 2012 distribution for assets, liabilities and their sub-categories. Alternatives to carrying forward or backward will be considered as the wealth tables are further developed and as more auxiliary data sources are identified.
These modelled totals for the asset and liability categories as well as net worth must be scaled to the NBSA totals, in the same way as in survey years. The factors, shown in Table 14 in the appendix, by which each cell must be multiplied varies by row. For 2012, it is the reciprocal of the coverage ratios. For other years, this factor is a global factor adjusting for both the coverage ratio and growth. This factor is the same for all four of the provisional tables.
After scaling survey estimates to NBSA totals, the row and column sums of the resulting tables are not coherent. The same raking process is used to ensure consistency within the resulting tables in non-survey years as is in survey years. Tables 19 to 22 in the appendix show the magnitude of the modifications to the internal cells of the 2010 to 2016 wealth tables that are introduced by raking. The ratios in these tables are generally close to 1, indicating that raking the tables does not result in major changes to the distributions, relative to the changes introduced through benchmarking.
8.5 Alternative net worth modelling approaches
To develop the wealth table methodology for the 2010 to 2016 period, two other approaches besides the area-level models were evaluated for modelling net worth: models constructed at the macro-level and models constructed at the micro-level. The area-level models can be considered as constructed at an intermediate level. There are substantial differences in these approaches, in particular in terms of how they incorporate auxiliary data sources. These two alternative approaches are described below, and are followed by a comparison with the area-level approach.
8.5.1 Macro-level approach: Interpolation and extrapolation
The macro-level approach to modelling net worth consists of estimating net worth distributions directly from SFS distributions available in survey years. With only three SFS years, over a 13 year period, macro-level modelling options were limited. Two types of interpolation/extrapolation were considered: linear and natural cubic splines.
As expected given the limitations of the SFS data, long gaps between survey years and smaller sample size in 2005, the results were deemed unsatisfactory. Interpolation resulted in unrealistic year over year trends. It could not capture events such as the 2008 recession. Also, 2005 consistently stood out as a turning point, with different trends before and after. This turning point in 2005 is not a reflection of a macro-economic trend but simply an artifact of having few SFS data points. Moreover, since the 2005 SFS was only designed to produce regional estimates, provincial estimates were not stable compared to the other SFS years due to large sampling variability.
It was therefore decided to use a different modelling option for net worth that would incorporate data from non-SFS sources. The limitations highlighted by the interpolation results are worth remembering and influence the selected implementation of benchmarking, described above. Finally, though it was deemed inadequate for net worth, a macro-level approach did reappear as part of the methodology in the form of carry-forwards for other lines of the table and for 2015 and 2016 when no T1FF data is available.
8.5.2 Micro-level approach: Unit-level models
The micro-level approach is based on models that predict the net worth of individual households, hence the “unit-level” name. These models are primarily based on the demographic and income information of household members.
Unit-level models can be used to estimate distributions of net worth for non-survey years as follows:
- A model is fit on the 2012 SFS data to predict the net worth of SFS households based on demographic and income information from these same households. The variables used as predictors in the model are chosen among variables that are also available on the T1FF.
- This model is then applied to families on the T1FF files for each year, giving each family on the T1FF a predicted net worth.
- Finally, distribution estimates are obtained by summing up predicted net worth on the T1FF files according to the characteristics of the T1FF families.
The unit-level model used to evaluate this approach is the one developed for the 2016 SFS stratifications and is used as a way to ensure oversampling of high and low net worth households (Laferrière and Boulet 2015). It is a linear model and uses the following variables as co-variates: total income of household members within the following age groups 35 to 44, 45 to 54, 55 to 64, 65 to 74, and 75 and over (five variables); absolute value of investment income; pension adjustment to allowed RRSP contributions; and average household income of all households within a postal code. The income by age group variables reflect the fact that the relationship between wealth and income varies by age group since wealth is accumulated over time. The average income within a postal code adds a hierarchical component to the model and captures the idea that neighbours have similar net worth. These models were fit using only the 2012 SFS data.
The performance of this model at the aggregate level is presented in section 8.5.3 when it is compared to results obtained from area-level models. Though the year over year trends and overall level estimates from this unit-level model do not appear as unrealistic as the results obtained by interpolation, there are challenges to working at the unit level, in particular with respect to outliers. Both net worth and income are highly skewed variables. Indeed, a relatively small number of households of very high net worth households hold a substantial proportion of overall wealth. These outliers are therefore very important when measuring total net worth. On the other hand, there is reason to believe that the relationship between net worth and income is different for these outliers at the very high net worth end of the spectrum than it is for most of the population. In modelling terms, a model that holds for most households may not extend to very high net worth households making it much harder to predict their net worth. This is especially problematic because of the influence of these households on total net worth.
8.5.3 Modelling approach evaluation and comparison
In order to determine which modelling approach to adopt, both unit-level and area-level models were constructed and compared. These comparisons were done on early versions of the models. In particular, it was done using after-tax income quintiles, since the determination of appropriate proxies to derive household disposable income was still ongoing at the time. Models were built using only 2012 data and compared to other years to gauge their performance over time.
The unit-level and area-level approaches were evaluated along two lines: their ability to capture macro-economic trends in level and their ability to predict the distribution of net worth. Between these, the second is of much greater importance since the distribution estimates coming out the model are scaled to the NBSA totals.
To evaluate the ability of the models to capture macro-economic trends in the overall level of net worth, the output of the models for total overall net worth was compared to SFS totals in 1999, 2005, and 2012 and NBSA totals for every year from 1999 to 2014. Chart 1 summarises the results in graphical format.
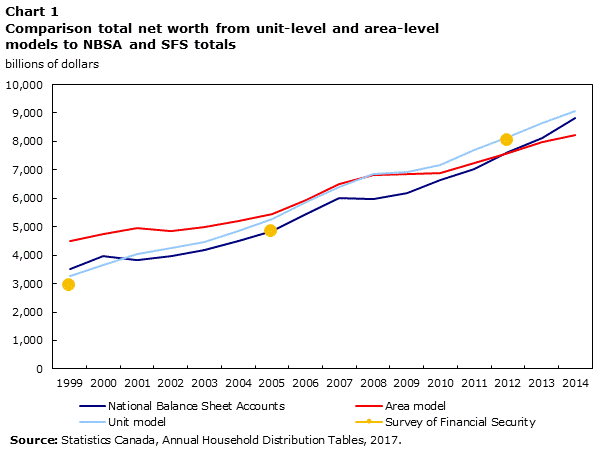
Data table for Chart 1
| Year | Area model | National Balance Sheet Accounts | Unit model | Survey of Financial Security |
|---|---|---|---|---|
| billions of dollars | ||||
| 1999 | 4,485.79 | 3,512.57 | 3,269.05 | 2,947.51 |
| 2000 | 4,738.88 | 3,982.76 | 3,641.16 | Note ...: not applicable |
| 2001 | 4,950.01 | 3,826.66 | 4,057.02 | Note ...: not applicable |
| 2002 | 4,844.71 | 3,959.89 | 4,240.02 | Note ...: not applicable |
| 2003 | 4,975.47 | 4,188.09 | 4,473.15 | Note ...: not applicable |
| 2004 | 5,193.66 | 4,505.38 | 4,854.62 | Note ...: not applicable |
| 2005 | 5,462.90 | 4,855.74 | 5,274.48 | 4,817.81 |
| 2006 | 5,957.69 | 5,447.26 | 5,863.78 | Note ...: not applicable |
| 2007 | 6,505.65 | 6,007.35 | 6,413.86 | Note ...: not applicable |
| 2008 | 6,830.25 | 5,989.96 | 6,849.38 | Note ...: not applicable |
| 2009 | 6,869.24 | 6,183.21 | 6,914.02 | Note ...: not applicable |
| 2010 | 6,887.99 | 6,631.09 | 7,169.11 | Note ...: not applicable |
| 2011 | 7,255.23 | 7,015.36 | 7,683.84 | Note ...: not applicable |
| 2012 | 7,587.84 | 7,638.80 | 8,165.61 | 8,030.46 |
| 2013 | 7,964.39 | 8,134.37 | 8,637.96 | Note ...: not applicable |
| 2014 | 8,215.62 | 8,821.23 | 9,065.66 | Note ...: not applicable |
|
... not applicable Source: Statistics Canada, Annual Household Distribution Tables, 2017. |
||||
Globally, the overall level of total net worth predicted by the unit-level model is closer to the NBSA totals than is the area-level model. Both reflect some macro-economic trends that are impossible to capture by interpolation. In particular, the recessions of 2000 and 2008 are captured by the models, but one year too late. Methods to correct for this lag will be considered as the methodology is further developed.
To evaluate the ability of the model to predict distributions of net worth over the years, the model, built using 2012 data only, was applied to 2005 and 1999 data and compared to the distributions obtained directly from SFS in those years. This comparison is shown in Table 9 and is similar to those of Tables 5 to 8. In terms of matching the SFS distributions, the area-level model performs much better than the unit-level model.
Table 9 also shows that, even in 2012, the year on which the model was built, there is a difference between the SFS distribution and the model output. As mentioned above, this discrepancy is addressed through benchmarking.
9 Sources of error
The Annual Household Distribution Tables (AHDT) are built by bringing together data from multiple sources. Each of these sources, as well as the way in which they are used and combined, is a potential source of gaps between the micro- and macro-level data. An overview of the sources of error for the AHDT wealth tables is given below, categorised according to their source:
- National accounts totals
- Survey data
- Model
A similar classification is found in Zwijnenburg (2016).
9.1 Quality of national accounts data
9.1.1 Quality of national accounts totals
The National Balance Sheet Accounts (NBSA) are estimated by using the most complete and high quality data sources available in order to establish benchmark annual estimates. This generally entails annual business surveys, administrative data files from the Canada Revenue Agency, annual household survey files, annual information from pension funds, financial institutions and government public accounts and establishing annual estimates. Data are analyzed for time series consistency, links to current economic events, issues arising from the source data, and finally with respect to coherence. It is not possible to produce an equivalent to national wealth or national net worth; nor is it possible to construct a balance sheet for the household sector, except periodically from household surveys. However, certain sub-sectors of the NBSA are largely comparable to estimates produced by source data divisions (e.g., pension funds, levels of government).
The NBSA are published quarterly, whereas AHDT refers to annual data. The NBSA data from the third quarter of each reference year has been selected as the data point to represent each reference year (i.e. 2012Q3 data is used as the 2012 total). This is the quarter that aligns with the collection period for the SFS and therefore minimizes potential timing quality issues.
9.1.2 Quality of the adjustments to the national accounts totals
As previously mentioned, the adjustment to isolate the household sector from the Non-Profit Institutions Serving Households (NPISH) sector was implemented in 2012. Work to build the NPISH sector began with the creation of a more broadly defined satellite account of non-profit institutions and volunteering, first released in 2004. The non-profit institutions serving households portion of this broader non-profit sector was implemented in the core System of National Accounts (SNA) in 2012, with estimates built from a variety of sources including administrative files on registered charities and other non-profit institutions. A range of statistical improvements to better define the universe and account for measurement deficiencies were undertaken in addition to the sectoring changes. These included delineating the purchases of households from the NPISH sector. Revised industry and final demand estimates were correspondingly introduced in the supply-use framework.
9.2 Quality of survey data
9.2.1 Sampling error
Sampling error is inevitable in any sample survey and occurs because data is collected and inferences are made from a sample, rather than the entire population. The sampling error is measured by estimating the extent to which sample estimates would vary over all possible samples that could have been selected with the same design and sample size. The magnitude of the sampling error is affected by several factors: the inherent variability in the population of the characteristic being measured, the sample size, the sample design, and the response rate. With its smaller size, the 2005 SFS has a larger sampling error than do the 1999 and 2012 SFS.
The coefficient of variation (CV) is a common measure of sampling error and can be used as one indicator of the accuracy of the estimates. It is defined as the ratio of the estimated standard error of the estimate to the value of estimate itself. In the 2012 SFS, the CV for total net worth at the national level was 1.7%. The CVs for total net worth for provinces ranged from 3.1% to 6.1% with the exception of Prince Edward Island whose CV was 12.4%. The CVs for estimates of totals are in the appendix in Tables 10 to 13.
9.2.2 Coverage error
Coverage errors are omissions, erroneous additions, duplicates and errors of classification of units in the survey frame. They can create biased estimates and the impact can vary for different sub-groups of the population.
For the AHDT, the population targeted by the SFS and the NBSA totals differ. In particular, the territories are excluded from SFS, as are about 2% of persons in the provinces that are difficult to survey for a variety of reasons.
9.2.3 Non-response error
There are two kinds of nonresponse: total nonresponse, not answering the whole survey, and item nonresponse, not answering some questions. In the SFS, this type of error is addressed by using follow-up procedures to minimize non-response, by weighting that takes into account non-response, and by imputation.
9.2.4 Measurement and processing error
Measurement error, also called response error, is the difference between the recorded response to a question and the “true” value. Measurement error can be caused by misunderstanding on the part of the respondent or the interviewer. Processing is required to transform survey responses into a form suitable to tabulation and analysis and may be a source of error.
9.3 Quality of the model used for non-survey years
In non-SFS years, the AHDT wealth tables depend heavily on a model of net worth. As such, their quality depends both on the quality of the auxiliary data on which the models are built and on the strength of the model itself. Model development work will continue for the AHDT wealth tables and will include evaluating the use of additional sources of auxiliary data.
9.3.1 Quality of auxiliary data sources
The auxiliary data source used for the net worth models from which estimates are derived in non-survey year are based on the T1 Family File. Based on demographic estimates, T1FF's coverage of persons is estimated at 95.6% nationally and is greater than 91% across all provinces and territories.
Since the T1FF and the SFS both draw their income information from the same source, their income variables are closely aligned conceptually which is useful for modelling. On the other hand, the T1FF uses the census family concept to either group individuals in a census family (parent(s) and children living at the same address) or identify them as persons not in census families. This concept is not quite aligned with the definition of household on which the AHDT are built. However, the type of models used in the AHDT, area-level models are more robust to this type of discrepancy than other types of models.
9.3.2 Quality of the model
The ability of the model to estimate net worth in non-SFS years, is discussed at length above. The net worth models are a fundamental component of the AHDT wealth tables methodology and, as with any model, they can only reflect the trends for net worth distributions that are related to trends in the auxiliary data, in this case, trends in net worth related to income and demographics.
At its core, the net worth model assumes that the relationship between T1FF data and net worth that exists over geographic areas in the 2012 SFS data, also holds over time and carries over into whole 2010 to 2016 period. This is an assumption of fundamental importance. It was partially evaluated by using data from the 1999 and 2005 SFS. A more complete evaluation of this assumption will be possible in 2018 when both the 2016 SFS and 2016 T1FF will be available.
Area-level models are an appropriate choice since they are more robust to difference in definitions between the survey data and on auxiliary data. By grouping household over large enough geographic areas, they are also less influenced by outliers.
9.4 Combining these sources
The AHDT brings together data from many difference sources and, so, it is not surprising that conceptual differences between micro and macro data sources are a major challenge. The use of modelling for non-SFS years adds an additional source of micro data to be reconciled with the others.
The methodology put forth in this paper and used to produce the preliminary AHDT wealth tables is comprised of multiple steps (reconciliation of micro and macro concepts, modelling, benchmarking, raking). Throughout these steps, the errors may accumulate or cancel out. One of the reasons to do benchmarking and raking is that it is hoped that these steps help limit the impact of the types of errors listed above.
10 Appendix
10.1 Sample error coefficients of variation for the Survey of Financial Security, 2012
10.2 Scaling factors
The following table shows the magnitude of the scaling adjustments to asset and liability categories. These factors account for coverage in 2012, and for differences in coverage and growth in the other years.
10.3 Benchmarking adjustment factors
The following tables show the magnitude of the benchmarking adjustments to the net worth distributions. These adjustments are applied to each year from 2010 to 2014.
10.4 Raking adjustment factors
The following tables show the magnitude of the raking adjustments to the distributions of asset and liability variables. These factors are calculated as values after raking divided by values after scaling. The net worth distributions are not changed by raking.
11 References
Bérubé J. and Fortier S. (2009). PROC TSRAKING: An in-house SAS® procedure for balancing time series. JSM Proceedings, Business and Economic Section. Alexandria, VA: American Statistical Association.
Dagum, E. B. and Cholette, P. A. (2006). Benchmarking, Temporal Distribution and Reconciliation Methods for Time Series Data. Springer-Verlag, New York. Lecture Notes in Statistics #186.
Laferrière, D. & Boulet, C. (2015). 2016 Survey of Financial Security (SFS) Net worth model development. Statistics Canada internal document.
Latendresse, E., Djona, M., and Fortier, S. (2007). Benchmarking Sub-Annual Series to Annual Totals – From Concepts to SAS® Procedure and SAS® Enterprise Guide® Custom Task. Proceedings of the SAS Global Forum, April 2007.
OECD. (2013). OECD Framework for Statistics on the Distribution of Household Income, Consumption and Wealth. OECD Publishing.
OECD. (2013). OECD Guidelines for Micro Statistics on Household Wealth. OECD Publishing.
Quenneville, B. and Fortier, S. (2012), Restoring accounting constraints in time series – Methods and software for a statistical agency, in Economic Time Series Modeling and Seasonality, ed. By Bell, W.R., Holan, S.H., and McElroy, T.S., Chapman and Hall/CRC, New York, 231–253.
Rao, J. N. K., & Molina, A. (2015). Small Area Estimation, 2nd Edition. Wiley, Hoboken, NJ.
Statistics Canada. (2012, 10 1). Revisions analysis – Canadian System of National Accounts 2012. Retrieved from Latest Developments in the Canadian Economic Accounts.
Statistics Canada. (2014, 02 24). Survey of Financial Security (SFS). Retrieved from CANSIM.
Statistics Canada. (2014, 02 24). Survey of Financial Security (SFS). Retrieved from the Integrated metadatabase (IMDB).
Statistics Canada. (2015, 12 1). Results from the 2015 Comprehensive Revision to the Canadian System of Macroeconomic Accounts. Retrieved from Latest Development in the Canadian Economic Accounts.
Statistics Canada. (2016, 07 13). Annual Income Estimates for Census Families and Individuals (T1 Family File). Retrieved from the Integrated metadatabase (IMDB).
Statistics Canada. (2016, 03 10). National Balance Sheet Accounts (NBSA). Retrieved from CANSIM.
Statistics Canada. (2016, 09 14). National Balance Sheet Accounts (NSBA). Retrieved from the Integrated metadatabase (IMDB).
Stiglitz, J. E., Sen, A., & Fitoussi, J.-P. (2009). Report by the Commission on the Measurement of Economic and Social Progress.
United Nations Economic Commission for Europe. (2011). Canberra Group Handbook on Household Income Statistics Second Edition. Geneva.
Van Rompaey, C. (2016). Wealth in Canada: Recent Development in Micro and Macro Measurement. Statistics Canada.
Zwijnenburg, J. (2016). Further Enhancing The Work On Household Distributional Data - Techniques for Bridging Gaps Between Micro and Macro Results And Nowcasting Methodologies For Compiling More Timely Results.
Zwijnenburg, J., Bournot, S., & Giovannelli, F. (2016). Expert Group on Disparities within a National Accounts Framework - Results from a recent exercise.
- Date modified: