5. Application à l'Enquête sur la population
active de la Corée
Jae-kwang Kim, Seunghwan Park et Seo-young Kim
Précédent | Suivant
Nous examinons maintenant une
application de la méthode proposée aux enquêtes sur la population active en Corée.
Dans ce pays, deux enquêtes distinctes sur la population active sont utilisées
pour obtenir des renseignements au sujet de l'emploi. L'une d'elles est
l'Enquête sur la population active coréenne (PAC) et l'autre est l'Enquête sur
la population active locale (PAL). L'enquête PAC est réalisée auprès d'un échantillon
d'environ 7 000 ménages, tandis que l'enquête PAL est réalisée auprès
d'un échantillon d'environ 200 000 ménages. Comme la PAL est une
enquête à grande échelle faisant appel à un grand nombre d'intervieweurs à
temps partiel, les données comportent un certain niveau d'erreurs de mesure. Nous
supposons que l'enquête PAC est exempte d'erreur de mesure, quoiqu'elle
présente d'importantes erreurs d'échantillonnage au niveau des petits domaines.
L'échantillon de l'enquête PAC est un échantillon de deuxième phase tiré de
l'échantillon de l'enquête PAL. Donc, les erreurs d'échantillonnage des
estimations d'après les deux enquêtes sont corrélées. Soit
le taux de chômage (réel) dans
le domaine
Le niveau de petit domaine que
nous considérons est appelé « Gu ». La Corée compte 229 « Gu ».
Nous observons
au moyen de l'enquête PAC et
au moyen de l'enquête PAL. Pour
construire des modèles de lien, nous commençons par diviser la population en
deux régions, une région urbaine et une région rurale, en nous basant sur la proportion
de ménages travaillant en agriculture. Nous spécifions des modèles distincts
pour chaque région (même modèle mais en permettant des paramètres différents) et
estimons les paramètres du modèle séparément. Le modèle structurel est
avec
Ici, nous posons que
pour garantir que l'estimateur
MCG de
n'est pas négatif. Le modèle
d'erreur d'échantillonnage reste le même. Dans ce cas, nous pouvons estimer
comme il suit
La variance d'échantillonnage de
est
calculée en utilisant la méthode d'échantillonnage à deux phases inverse
décrite à l'annexe. La variance sous le modèle est estimée par la
méthode des moments dans (3.8) avec
L'estimateur MCG peut être calculé
en utilisant (2.9) avec
En plus des deux enquêtes, nous pouvons
aussi utiliser l'information provenant du recensement. Le modèle MCG intégrant les
trois sources d'information peut être exprimé sous la forme
où
est le résultat du recensement pour
le domaine
Comme l'estimation d'après le
recensement ne présente pas d'erreur d'échantillonnage, nous avons une seule
erreur de modélisation
qui représente l'erreur commise
quand nous modélisons
Les paramètres du modèle peuvent
être obtenus en utilisant la méthode décrite à la section 3 avec
L'estimateur MCG de
s'obtient facilement. L'EQM peut
être calculée en utilisant le fait que
et en appliquant la méthode du jackknife pour corriger le biais.
La figure 5.1 donne le graphique du
taux de chômage selon l'enquête PAC en fonction du taux de chômage selon l'enquête PAL pour
les domaines urbains. La figure 5.1 montre qu'il existe une relation structurelle
linéaire entre les estimations PAC et PAL. Au lieu du résidu habituel
dans le modèle d'erreur
structurel, nous utilisons
en tant que résidu dans le
modèle de régression avec erreurs de mesure, où
La figure 5.2 donne le
graphique de
en fonction de
pour les domaines urbains. Le
graphique montre que l'hypothèse de variance
égale est légèrement violée. Nous
avons également considéré le modèle de variance hétéroscédastique décrit dans
la remarque 2, mais les résultats n'ont pas varié de manière significative.
Figure 5.1 Graphique du taux de chômage selon les enquêtes PAC
et PAL pour les domaines urbains
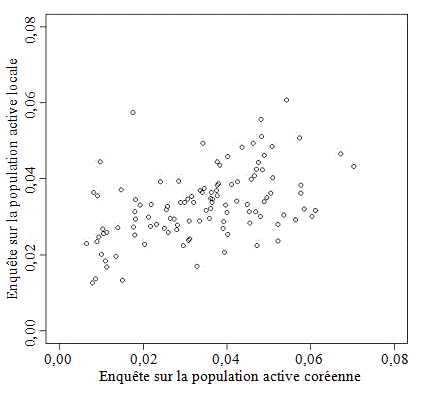
Description de la figure 5.1
Figure 5.2 Graphique des résidus en fonction des valeurs
estimées pour les domaines urbains
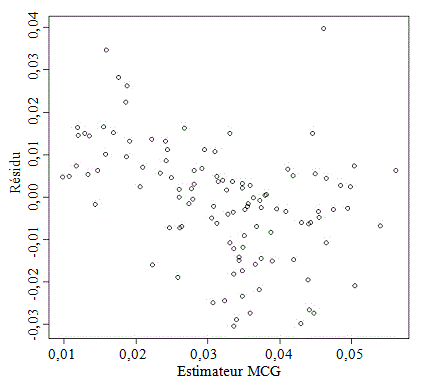
Description de la figure 5.2
Tableau 5.1
Quartile de la performance des estimations sur petits domaines selon l’EQM pour les 229 domaines
Sommaire du tableau
Le tableau montre les résultats de Quartile de la performance des estimations sur petits domaines selon l’EQM pour les 229 domaines. Les données sont présentées selon EQM (titres de rangée) et 1 Q, Médiane, 3 Q et Moyenne(figurant comme en-tête de colonne).
| EQM |
1er Q |
Médiane |
3e Q |
Moyenne |
| PAC |
0,0000630 |
0,0001210 |
0,0002395 |
0,0002476 |
| PAL |
0,0001123 |
0,0001330 |
0,0001695 |
0,0001482 |
| MCG 1 |
0,0000444 |
0,0000738 |
0,0001210 |
0,0000893 |
| MCG 2 |
0,0000405 |
0,0000543 |
0,0000721 |
0,0000575 |
Le tableau 5.1 donne les
propriétés des estimations sur petits domaines en ce qui concerne l'EQM estimée.
Nous avons examiné quatre estimateurs distincts de
PAC représente le résultat
obtenu en utilisant les données de l'enquête sur la population active coréenne
uniquement, PAL représente le résultat obtenu en utilisant les données de
l'enquête sur la population active locale uniquement, MCG 1 représente le résultat
obtenu en combinant les données des deux enquêtes PAC et PAL, et MCG 2 représente
le résultat obtenu en combinant les données des enquêtes PAC et PAL et du
recensement. Le tableau 5.1 montre que l'estimateur MCG 2 est celui qui
donne les erreurs quadratiques moyennes les plus petites.
Précédent | Suivant
