
6 Une autre application : l'Enquête mensuelle sur le lait et les produits laitiers
Marco Ballin et Giulio Barcaroli
Notre algorithme a également été appliqué à l'Enquête mensuelle sur le lait et les produits laitiers de 2010. Il s'agit d'une enquête par sondage qui dépend strictement de l'« Enquête annuelle sur le lait et les produits laitiers », qui est un recensement de toutes les exploitations agricoles italiennes produisant du lait et des produits laitiers. Les deux enquêtes recueillent la même information : la quantité de lait recueillie au niveau national et son utilisation (dans la transformation des produits laitiers : lait, fromage, beurre, etc.); l'objectif de l'enquête par sondage mensuelle est d'obtenir des renseignements à jour avant que les résultats de l'enquête annuelle (réalisée l'année précédente) soient disponibles. L'échantillon de 2010 a été planifié comme il suit :
- l'information recueillie auprès des 2 250 unités qui avaient répondu au cycle de 2008 de l'enquête annuelle a été structurée comme une base de sondage : en particulier, quatre des variables cibles de l'enquête annuelle, qui sont continues, ont été transformées en variables catégoriques (facteurs ordonnés) en utilisant la méthode de classification automatique à moyennes, et ont été considérées comme information auxiliaire dans le base de sondage;
- le produit croisé des variables catégoriques obtenues a donné une stratification de la base de sondage consistant en 152 strates (atomiques);
- l'information reliée aux moyennes et aux écarts-types des quatre variables cibles de l'enquête mensuelle a été calculée pour chacune des strates atomiques en utilisant les données de l'enquête annuelle.
Les contraintes sur les coefficients de variation des estimations des totaux sont présentées au tableau 6.1.
| Variable | CV maximal acceptable pour les estimations du total (%) |
|---|---|
| Lait recueilli | 1 |
| Lait | 15 |
| Beurre | 3,8 |
| Fromages de lait de vache | 3 |
Après cela, l'algorithme de Bethel a été appliqué afin de vérifier quelle était la taille d'échantillon requise pour la stratification (atomique) initiale disponible pour la base de sondage (en outre, dans cette application, la fonction de coût coïncide avec la taille totale de l'échantillon, car le coût fixe a été fixé à 0, et les coûts variables ont été fixés à 1 dans chaque strate atomique) : cela a donné 290 unités à interviewer, réparties entre les 152 strates différentes. La procédure habituelle se termine ici : à ce stade, les 290 unités seraient sélectionnées dans la base de sondage représentée par l'enquête annuelle, puis l'enquête mensuelle débuterait.
Au lieu de cela, l'application de l'algorithme génétique a suggéré un regroupement des 152 strates atomiques initiales en 88 strates agrégées, nécessitant une taille d'échantillon de 247 seulement pour satisfaire les mêmes contraintes, c.-à-d. une diminution d'environ 15 %.
Après de très nombreuses essais, les valeurs suivantes ont été données aux paramètres les plus importants :
- la taille de la génération a été fixée à 50;
- le nombre d'itérations a été fixé à 4 000;
- un minimum de deux unités par strate a été exigé;
- le nombre initial de strates (coïncidant avec le nombre maximal de celles-ci, parce que le paramètre addStrataFactor a été fixé à 0) a été pris égal au nombre de strates atomiques (152);
- les chances de mutation ont été fixées à 0,0005.
La combinaison des paramètres « taille de la génération » et « nombre d'itérations » a déterminé l'évaluation de 200 000 solutions. Le graphique de convergence présenté à la figure 6.1 montre qu'après 2 700/2 800, plus aucune amélioration de la meilleure solution identifiée n'a eu lieu.
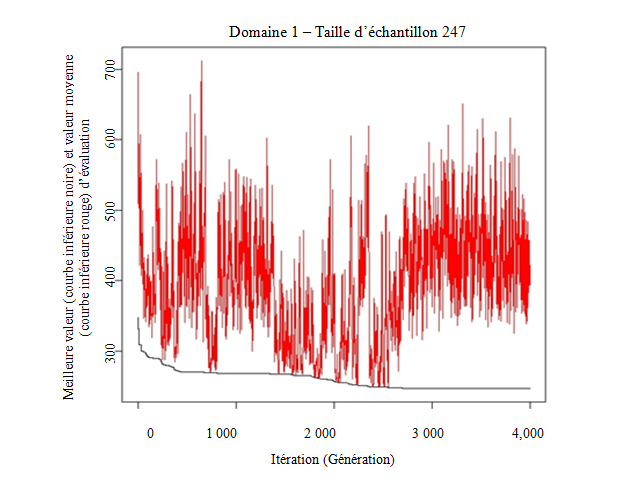
Figure 6.1 Meilleure valeur et valeur moyenne d'évaluation dans l'optimisation de l'Enquête mensuelle sur le lait
- Date de modification :