
5 Une application : l'Enquête italienne sur la structure des exploitations agricoles (ESEA)
Marco Ballin et Giulio Barcaroli
La base de sondage utilisée pour la sélection de l'échantillon de l'Enquête italienne sur la structure des exploitations agricoles de 2003 (ESEA) contient 2 153 710 exploitations agricoles. Pour l'établissement du plan de sondage de l'ESEA, les variables auxiliaires prises en considération sont les suivantes :
- régions (21 valeurs différentes);
- provinces (103 valeurs différentes);
- statut juridique (2 classes);
- secteur d'activité économique (9 classes);
- unités de dimension économique (3 classes);
- superficie agricole utilisée (3 classes);
- unités de bétail (3 classes);
- altimétrie du siège social de l'exploitation agricole (5 classes).
Quatorze variables cibles distinctes ont été prises en considération comme étant la cible principale de l'ESEA, pour lesquelles les niveaux de précision requis (en ce qui concerne la valeur maximale du coefficient de variation) ont été fixés à l'échelle régionale (domaines d'intérêt). La liste des variables et des contraintes de précision connexe est présentée au tableau 5.1.
Les 8 variables auxiliaires ainsi que les 14 variables cibles ont été observées durant le recensement de l'agriculture précédent de 2000, de sorte que leurs valeurs sont disponibles pour chaque unité présente dans la base de sondage. Il est donc possible de calculer les moyennes et les écarts-types se rapportant à n'importe quelle strate définie.
Pour commencer, nous décrivons la procédure « manuelle » courante suivie en 2003 pour choisir la stratification la plus appropriée pour sélectionner l'échantillon.
Configuration manuelle des strates de 2003 pour sélectionner l'échantillon de l'ESEA
À la première étape, on a défini une strate à tirage complet dans chaque région sur la base des caractéristiques locales. Les seuils pour la définition des strates à tirage complet ont été déterminés en appliquant la méthode de Hidiroglou (1986).
À la deuxième étape, on a effectué un choix entre une stratification fondée sur les provinces ou sur la région dans son ensemble, région par région, en se basant sur des considérations organisationnelles locales.
À la troisième étape, les six autres variables ont été utilisées l'une après l'autre dans chaque région ou province (selon le résultat obtenu à la deuxième étape) comme variables de stratification. Pour chacune de ces options de stratification, on a calculé la taille optimale d'échantillon (la taille minimale d'échantillon dans chaque strate a été fixée à 50) (dans la fonction de coût, le coût fixe a été égalé à 0 et les coûts variables ont été fixés à 1 dans chaque strate atomique : donc, la fonction de coût coïncide avec la taille totale d'échantillon). La stratification donnant lieu à la taille globale d'échantillon minimale dans chaque région (habituellement définie sur différentes variables) a été considérée comme la sortie de cette étape.
À la quatrième étape, les cinq variables restantes ont été utilisées séparément pour affiner la stratification obtenue antérieurement. Pour chacune de ces spécifications affinées, la taille optimale d'échantillon a été calculée en considérant les mêmes contraintes que celles utilisées à l'étape 3.
Cette procédure par étape a été répétée sur une base régionale, en affinant la meilleure stratification obtenue à chaque étape en se servant des variables disponibles restantes jusqu'à ce que la stratification obtenue s'avère être moins efficace que la stratification de l'étape précédente.
De cette façon, la valeur totale de la taille d'échantillon planifiée a été fixée à 42 465 unités (en fait, la taille d'échantillon utilisée pour l'ESEA de 2003 a été portée à 52 713 afin d'obtenir de meilleures estimations au niveau national. Ici, nous considérons le chiffre de 42 465 afin que soit correcte la comparaison avec les résultats obtenus au moyen de l'algorithme génétique).
Utilisation de l'algorithme génétique pour déterminer les strates optimales et la meilleure répartition de l'échantillon
La stratification la plus détaillée disponible de la base de sondage, obtenue sous forme du produit cartésien de toutes les variables auxiliaires, comprend 24 454 strates distinctes, dont 1 787 sont définies comme étant des strates à tirage complet. Donc, les strates atomiques sont données par les 22 667 strates d'échantillonnage obtenues en soustrayant les 1 787 strates à tirage complet. Ces dernières sont regroupées en une seule strate, dont les 6 971 unités seront toujours sélectionnées quel que soit l'échantillon.
En fait, l'une des variables auxiliaires, région, est considérée comme la variable de domaine. Donc, notre tâche consiste à optimiser la stratification de la base de sondage et la répartition de l'échantillon séparément pour chacune des 21 régions de l'Italie. Par exemple, la première région (Piémont) est caractérisée par 105 074 unités dans 1 646 strates d'échantillonnage, et 597 unités dans 129 strates à tirage complet.
Les contraintes de précision (de nouveau exprimées en fonction des limites supérieures des coefficients de variation) ont été fixées, pour chacune des 14 variables cibles distinctes, aux mêmes valeurs que celles choisies durant la configuration manuelle des strates exécutée pour l'enquête de 2003 : ces limites sont 5 %, 6 % ou 10 % pour les variables les plus importantes dans chaque région. Le tableau 5.1 donne le jeu complet de coefficients de variation utilisé pour planifier l'ESEA de 2003.
| Région | Céréales | Cultures industrielles | Légumes frais | Fleurs | Vignobles | Olives | Agrumes | Fruits | Bovins | Porcins | Ovins | Unités de dimension économique | Superficie agricole utilisée | Unités de bétail |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Piémont | 5,0 | 10,0 | 5,0 | 5,0 | 5,0 | 6,0 | 6,0 | |||||||
| Vallée d'Aoste | 5,0 | 5,0 | 6,0 | 6,0 | ||||||||||
| Lombardie | 5,0 | 10,0 | 5,0 | 5,0 | 5,0 | 6,0 | 6,0 | |||||||
| Bolzano | 5,0 | 5,0 | 6,0 | 6,0 | ||||||||||
| Trente | 5,0 | 5,0 | 6,0 | 6,0 | ||||||||||
| Vénétie | 5,0 | 10,0 | 5,0 | 5,0 | 5,0 | 6,0 | 6,0 | |||||||
| Frioul-VJ | 5,0 | 10,0 | 5,0 | 6,0 | 6,0 | |||||||||
| Ligurie | 5,0 | 5,0 | 6,0 | 6,0 | ||||||||||
| Émilie-Romagne | 5,0 | 10,0 | 5,0 | 5,0 | 5,0 | 5,0 | 5,0 | 6,0 | 6,0 | |||||
| Toscane | 5,0 | 10,0 | 5,0 | 5,0 | 6,0 | 6,0 | ||||||||
| Ombrie | 5,0 | 5,0 | 6,0 | 6,0 | ||||||||||
| Marches | 5,0 | 6,0 | 6,0 | |||||||||||
| Latium | 5,0 | 5,0 | 5,0 | 5,0 | 5,0 | 6,0 | 6,0 | |||||||
| Abruzzes | 5,0 | 5,0 | 6,0 | 6,0 | ||||||||||
| Molise | 5,0 | 5,0 | 6,0 | 6,0 | ||||||||||
| Campanie | 5,0 | 10,0 | 5,0 | 5,0 | 5,0 | 5,0 | 6,0 | 6,0 | ||||||
| Pouilles | 5,0 | 5,0 | 5,0 | 5,0 | 5,0 | 6,0 | 6,0 | |||||||
| Basilicate | 5,0 | 5,0 | 6,0 | 6,0 | ||||||||||
| Calabre | 5,0 | 5,0 | 5,0 | 5,0 | 6,0 | 6,0 | ||||||||
| Sicile | 5,0 | 5,0 | 5,0 | 5,0 | 5,0 | 5,0 | 5,0 | 6,0 | 6,0 | |||||
| Sardaigne | 5,0 | 5,0 | 5,0 | 6,0 | 6,0 |
Le tableau 5.2 donne les résultats des deux solutions en ce qui concerne la taille requise d'échantillon : celle prévue en 2003 par le spécialiste chargé de la conception de l'échantillon de l'ESEA (colonne 6) et celle obtenue en appliquant l'algorithme génétique (colonne 7).
| (1) Domaine (région) | (2) Nombre total d'unités dans la base de sondage | (3) Nombre de strates atomiques d'échantil-lonnage dans la base de sondage | (4) Nombre d'unités dans les strates d'échantillonnage | (5) Nombre d'unités dans les strates à tirage complet | (6) Taille de l'échantillon selon la stratification de 2003 | (7) Taille de l'échantillon selon la solution de l'algorithme génétique | (8) Nombre de strates dans la solution de l'AG | (9) Différence relative en % (7) c. (6) |
|---|---|---|---|---|---|---|---|---|
| Piémont | 105 671 | 1 646 | 105 074 | 597 | 2 687 | 1 497 | 9 | -44,29 |
| Vallée d'Aoste | 6 125 | 65 | 6 074 | 51 | 408 | 317 | 7 | -22,30 |
| Lombardie | 71 257 | 1 902 | 69 495 | 1 762 | 3 428 | 2 151 | 7 | -37,25 |
| Bolzano | 23 362 | 127 | 23 202 | 160 | 692 | 430 | 7 | -37,86 |
| Trente | 30 021 | 124 | 29 908 | 113 | 676 | 523 | 7 | -22,63 |
| Vénétie | 176 999 | 1 450 | 176 064 | 935 | 3 531 | 1 868 | 11 | -47,10 |
| Frioul | 32 981 | 638 | 32 805 | 176 | 807 | 498 | 6 | -38,29 |
| Ligurie | 29 992 | 584 | 29 967 | 25 | 766 | 485 | 7 | -36,68 |
| Émilie-Romagne | 103 702 | 2 157 | 102 922 | 780 | 2 584 | 2 022 | 11 | -21,75 |
| Toscane | 107 288 | 1 959 | 106 964 | 324 | 2 099 | 1 337 | 16 | -36,30 |
| Ombrie | 46 074 | 435 | 45 897 | 177 | 1 354 | 751 | 7 | -44,53 |
| Marches | 60 439 | 1 005 | 60 271 | 168 | 918 | 488 | 8 | -46,84 |
| Latium | 162 109 | 1 304 | 161 801 | 308 | 3 233 | 2 216 | 14 | -31,46 |
| Abruzzes | 67 117 | 888 | 66 941 | 176 | 1 035 | 743 | 10 | -28,21 |
| Molise | 28 890 | 375 | 28 834 | 56 | 1 190 | 630 | 6 | -47,06 |
| Campanie | 212 145 | 1 271 | 211 833 | 312 | 2 559 | 1 883 | 13 | -26,42 |
| Pouilles | 288 087 | 1 026 | 287 877 | 210 | 4 712 | 2 009 | 14 | -57,36 |
| Basilicate | 68 470 | 504 | 68 355 | 115 | 703 | 493 | 7 | -29,87 |
| Calabre | 145 812 | 1 624 | 145 654 | 158 | 2 798 | 1 792 | 17 | -35,95 |
| Sicile | 295 637 | 2 345 | 295 472 | 165 | 3 955 | 3 140 | 22 | -20,61 |
| Sardaigne | 91 532 | 1 238 | 91 329 | 203 | 2 330 | 982 | 7 | -57,85 |
| Italie | 2 153 710 | 22 667 | 2 146 739 | 6 971 | 42 465 | 26 255 | 213 | -38,17 |
Comme la détermination de la meilleure stratification a été effectuée séparément pour chaque région, 21 résultats indépendants attestent de la grande commodité de l'algorithme dans la plupart des domaines. On constate une diminution spectaculaire de la taille globale d'échantillon requise, comme en témoigne l'économie de 38,17 % par rapport au total antérieur. Ce résultat varie de région en région, la diminution maximale étant observée pour la Sardaigne (-57,85 %) et la diminution minimale, pour la Sicile (-20,61 %). En outre, en ce qui concerne les strates, en partant du nombre initial de strates atomiques (22 667), on observe une réduction énorme à l'étape de la stratification finale, qui est caractérisée par 213 strates distinctes seulement (nombre variant d'un minimum de 6 strates dans la région de Frioul à 22 strates en Sicile).
Pour ce qui est des paramètres utilisés pour obtenir le résultat susmentionné, les plus importants étaient les suivants :
- nombre d'itérations (ou de générations);
- taille de la génération (nombre d'individus, ou de solutions, évalué à chaque itération);
- chances de mutation;
- nombre initial de strates;
- facteur d'accroissement du nombre initial de strates.
Leurs valeurs finales ont été déterminées, après de nombreux essais, sur la base de l'analyse des exécutions pour chaque région.
En particulier, en inspectant le graphique de convergence, il est possible de voir si le nombre d'itérations est suffisant pour avoir la certitude que la solution finale est définitivement la meilleure qu'il est possible d'obtenir, ou si un nombre plus élevé d'itérations est nécessaire. Pour cela, on peut analyser le comportement des deux courbes du graphique : la courbe inférieure donne la meilleure valeur d'évaluation, tandis que la courbe supérieure donne la valeur moyenne d'évaluation. Lorsque la valeur moyenne d'évaluation continue à diminuer, de même que la meilleure valeur d'évaluation, cela vaut la peine de poursuivre les itérations. Lorsque la courbe de la meilleure valeur devient stablement constante (et, habituellement, que la courbe de la valeur moyenne commence à fluctuer vers le haut et le bas), aucun gain supplémentaire ne peut être attendu de nouvelles itérations. C'est ce que montre, par exemple, le graphique de convergence pour la région de Trente, à la figure 5.1.
Pour le paramètre iterations, une valeur de 5 000 s'est révélée commode. Pour les chances de mutation, nous avons constaté que 0,001 était une valeur appropriée : cela signifie que, pour tout chromosome dans le génome (toute valeur dans le vecteur ), une mutation n'a lieu, en moyenne, qu'une fois sur mille. Un élément critique consiste à fixer le nombre initial de strates. Puisque la solution finale est très sensible au nombre de strates, nous avons décidé de laisser l'algorithme faire le choix. On peut, pour cela, comme nous l'avons déjà expliqué à la section 4, attribuer une faible valeur à initialStrata, et donner une valeur plus grande que 0 à addStrataFactor : cela permet à l'algorithme d'explorer les solutions correspondant à une grande gamme de nombre de strates. Dans notre expérience, nous avons fixé le nombre initial de strates à la valeur 5 et avons attribué une valeur de 0,01 au facteur d'accroissement du nombre initial de strates (cela signifie que, chaque fois qu'une mutation a lieu, il existe une probabilité de 1 % d'augmenter le nombre courant de strates).
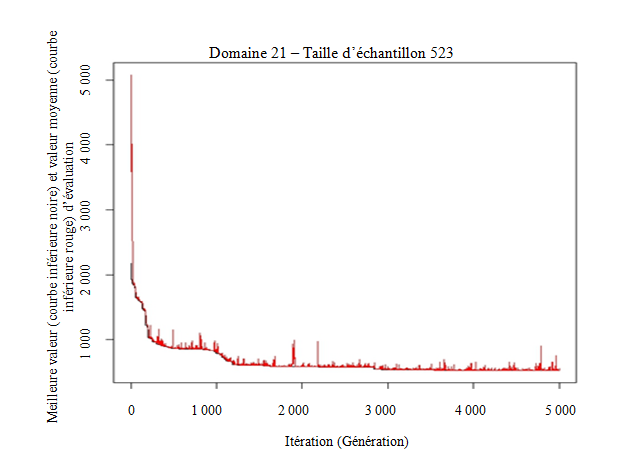
Figure 5.1 Meilleure valeur et valeur moyenne d'évaluation pour la région de Trente
Du point de vue des calculs, l'exécution de la tâche globale a pris 641 820 secondes (plus de 178 heures, près d'une semaine) (la tâche a été exécutée sur un ordinateur de bureau AMD Athlon (2,90 Ghz, 3 GB RAM)).
- Date de modification :