
5 Simulations en utilisant des données réelles
Pierre Lavallée et Sébastien Labelle-Blanchet
Les simulations reflètent une enquête auprès des entreprises type de Statistique Canada. Nous avons choisi trois populations qui sont fréquemment la cible d'enquêtes menées par Statistique Canada. Les populations d'établissements des secteurs de la fabrication, du commerce de détail et de la restauration ont été extraites du Registre des entreprises (RE). On sait que ces trois populations ont une distribution asymétrique pour des variables économiques telles que le revenu, surtout les deux premières. Les simulations ont été effectuées sous EASSR stratifié selon le secteur d'activité, la région et la catégorie de revenu. L'algorithme de Lavallée-Hidiroglou (1988) a été utilisé pour créer les catégories de revenu, déterminer la taille d'échantillon et effectuer la répartition. Les établissements étaient répartis en trois strates en fonction de leur taille, à savoir une strate à tirage complet et deux strates à tirage partiel. Un coefficient de variation de 5 % était visé dans chaque strate par secteur d'activité et par région. Le tableau qui suit contient certaines statistiques sur la population.
| Secteur d’activité | Revenu moyen | Variance | Asymétrie | |||
|---|---|---|---|---|---|---|
| Fabrication | 96 955 | 100 109 | 2 223 | 4 364 808 | 1,08x1016 | 164 |
| Commerce de détail | 142 020 | 159 247 | 3 627 | 2 034 111 | 3,29x1014 | 133 |
| Restauration | 107 358 | 113 425 | 2 439 | 561 764 | 4,43x1012 | 106 |
| Total | 346 333 | 372 781 | 8 289 | --- | --- | --- |
La variable de revenu disponible dans le RE a été utilisée comme variable d'intérêt Puisque les valeurs de cette variable sont connues pour toutes les unités, aucun échantillon n'a dû être sélectionné pour la plupart des méthodes. Il convient de souligner que, pour la méthode 2 proportionnel à une mesure de taille on s'est servi du nombre d'employés.
Sauf pour les méthodes 7 et 8, nous avons calculé les variances réelles d'après les données en utilisant la formule (2.11). Pour la méthode 7, nous avons utilisé la formule (4.23). Pour la méthode 8, nous avons dû calculer les probabilités de sélection réelles de toutes les entreprises. Nous aurions pu calculer ces probabilités en nous servant de formules exactes, mais nous avons choisi de le faire en exécutant une simulation Monte Carlo en deux étapes. L'une des raisons est que la formule de variance (4.27) qui utilise les probabilités de sélection conjointe fait intervenir un trop grand nombre de paires Pour la première étape de la simulation Monte Carlo, nous avons sélectionné 20 000 échantillons selon le plan d'EASSR stratifié décrit plus haut. Pour chaque échantillon, nous avons déterminé quelle entreprise finissait par être sélectionnée. Sur ces 20 000 échantillons, nous avons pu estimer la probabilité de sélection de chaque entreprise sous ce plan de sondage à probabilités inégales. Une fois que ces probabilités ont été calculées, nous avons exécuté une autre simulation Monte Carlo pour calculer la variance. Nous avons sélectionné 20 000 échantillons d'établissements en utilisant de nouveau le plan d'EASSR stratifié décrit plus haut. Nous avons alors obtenu les échantillons correspondants d'entreprises. Pour chaque réplique nous avons produit une estimation de en utilisant l'estimateur (4.26). Nous avons calculé la variance en utilisant la formule
(5.1)
où Notons que, comme l'estimateur (4.26) est sans biais, nous avons
Pour chaque estimateur nous avons calculé le coefficient de variation en utilisant
(5.2)
5.1 Résultats de la simulation
Pour la MGPP classique et pour toutes les méthodes présentées, nous avons calculé les estimations, les variances et les coefficients de variation. Le graphique qui suit donne les CV obtenus au niveau national.
Graphique 5.1 Coefficients de variation par méthode

À part la méthode 7, toutes les méthodes donnent une diminution de la variance et la réduction est souvent considérable. Comme il est décrit plus haut, la méthode 7 (utilisant les établissements désignés) consiste à sélectionner un seul établissement au sein d'une entreprise en se basant sur la variable auxiliaire et à affecter l'entreprise complète à cet établissement. Autrement dit, un établissement donné hérite de tous les revenus de l'entreprise. Cette approche est avantageuse quand l'établissement désigné se trouve dans une strate à tirage complet. Cependant, si l'établissement désigné se trouve dans une strate à tirage partiel, la distribution à l'intérieur de cette strate devient encore plus asymétrique. On attribue à cette strate la totalité des revenus de l'entreprise multipliés par le poids de sondage de cette entreprise, ce qui fait augmenter considérablement la variance. Toutes les autres méthodes donnent des résultats raisonnables que nous analysons en détail au moyen des graphiques qui suivent.
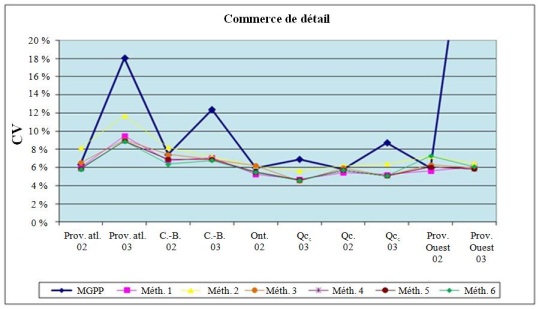
Les graphiques qui suivent donnent le CV pour chaque strate à tirage partiel par industrie.
Graphique 5.2 CV pour la fabrication par strate

Graphique 5.3 CV pour le commerce de détail par strate
Graphique 5.4 CV pour la restauration par strate

Note 1 : L'échelle du CV n'est pas la même pour la fabrication que pour les deux autres industries.
Note 2 : Les CV par strate des méthodes 7 et 8 ne sont pas présentés ici parce qu'ils ne sont pas pertinents pour la comparaison qui est faite. En effet, la notion de strate n'est pas la même pour ces deux méthodes que pour les autres. La stratification définie par le plan de sondage original est effectuée au niveau de l'établissement. Pour les méthodes 7 et 8, l'échantillonnage est effectué au niveau de l'entreprise et, par conséquent, une strate type pour les méthodes 1 à 6 devient un domaine pour les méthodes 7 et 8. Évidemment, les variances associées aux méthodes 7 et 8 sont beaucoup plus grandes, ce qui rend non pertinente toute comparaison avec les autres méthodes.
Les CV sont particulièrement élevés pour la MGPP classique dans certaines strates, surtout pour le secteur de la fabrication. Nous nous y attendions, parce que ce dernier est, des trois secteurs examinés, celui pour lequel l'asymétrie de la distribution de la variable d'intérêt était la plus prononcée. En outre, dans ce secteur, nous avons des établissements dont les revenus peuvent varier fortement au sein d'une même entreprise, et ces établissements peuvent être répartis entre plusieurs strates. Ce sont les raisons pour lesquelles la variance de la MGPP classique devient très élevée.
Tous les graphiques montrent que l'utilisation de n'importe laquelle des méthodes proposées donne lieu à une réduction du CV, donc de la variance. Les CV sont généralement plus faibles pour les autres méthodes que pour la MGPP classique (représentée par la ligne bleu foncé avec les losanges).
5.2 Comparaison des méthodes proposées
La méthode 1 donne des résultats très prometteurs, étant donné sa simplicité. Elle produit certains des CV les plus faibles observés pour l'ensemble des méthodes. Elle cible réellement la source du problème de la MGPP, à savoir la nécessité d'une répartition inégale des poids, proportionnelle dans une certaine mesure à la taille de la variable d'intérêt. Puisque la plupart des enquêtes auprès des entreprises s'appuient sur une stratification par taille, cette méthode donne de bons résultats. Elle a également l'avantage de ne pas dépendre directement de la variable d'intérêt.
La méthode 2 utilise une variable auxiliaire (ici, le nombre d'employés) pour répartir les poids. Cette variable n'est pas bien corrélée avec la variable d'intérêt, ce qui explique pourquoi cette méthode produit la plus petite réduction de la variance. En fait, il s'agit d'une version plus faible de la méthode 3.
La méthode 3 répartit le poids proportionnellement à la variable d'intérêt c'est-à-dire le revenu de l'établissement dans l'entreprise. La méthode donne de très bons résultats au niveau national ainsi que provincial. Le résultat est généralement plus élevé que pour les méthodes 1, 4, 5 et 6, à cause de l'asymétrie prononcée de la distribution du revenu.
Les méthodes 4, 5 et 6 donnent des résultats fort semblables, produisant un CV compris entre 6 % et 10 % pour le commerce de détail et la restauration, et entre 10 % et 25 % pour la fabrication. La similarité des résultats obtenus par les trois méthodes est raisonnable parce que toutes visent à produire la variance la plus faible possible. Chaque fois qu'un établissement d'une entreprise se trouve dans une strate à tirage complet, ces méthodes concentrent toutes les valeurs sur cet établissement et attribuent des liens nuls à tous les autres établissements de l'entreprise. Il s'agit d'un choix naturel pour minimiser la variance, puisque la contribution de cette entreprise à la variance devient nulle. Comme un établissement d'une grande entreprise peut se trouver dans une strate à tirage complet, la variance devient plus faible que celle produite par n'importe quelle autre méthode. Ce sont les raisons pour lesquelles ces trois méthodes représentent le meilleur moyen de partager les poids. Cependant, il n'a pas été possible de déterminer laquelle des trois est la meilleure.
La méthode 7 ne donne pas de bons résultats. Rappelons que pour cette méthode, nous avons permis qu'un seul établissement désigné représente l'ensemble de l'entreprise. Les valeurs de la variable d'intérêt de tous les établissements sont totalisées au niveau de l'entreprise, puis attribuées à cet établissement désigné. La distribution de la variable d'intérêt par strate devient encore plus asymétrique, ce qui produit une plus grande variance. Du point de vue de l'échantillonnage, une entreprise se retrouve dans une strate unique (parce qu'elle est représentée par un seul établissement) qui pourrait ne pas être une strate à tirage complet. En outre, la méthode n'est pas efficace quand il faut produire des estimations au niveau provincial ou du secteur d'activité. Les estimations ne peuvent pas bénéficier de la stratification des établissements, alors que cela est possible dans le cas des autres méthodes. Ce fait contribue également à une plus grande variance.
La méthode 8 utilise les probabilités de sélection des entreprises obtenues par des simulations. Elle donne de bons résultats, le CV étant de 1,3 % au niveau national. Sa performance égale celle des méthodes 4, 5 et 6. Cependant, elle peut être difficile à appliquer en pratique. Nous devons soit calculer explicitement les probabilités de sélection de deuxième ordre ce qui peut être très compliqué, ou les estimer par simulation, ce qui prend beaucoup de temps.
- Date de modification :