
Publications
Bulletin d'analyse – Régions rurales et petites villes du Canada
Zones de travail autonomes : une proposition de délimitation et de classification selon le degré de ruralité
Données et définitions
 Consulter la version la plus récente.
Consulter la version la plus récente.
Information archivée dans le Web
L’information dont il est indiqué qu’elle est archivée est fournie à des fins de référence, de recherche ou de tenue de documents. Elle n’est pas assujettie aux normes Web du gouvernement du Canada et elle n’a pas été modifiée ou mise à jour depuis son archivage. Pour obtenir cette information dans un autre format, veuillez communiquer avec nous.
Encadré 1
Définitions de la géographie
Subdivision de recensement
Les subdivisions de recensement (SDR) sont les éléments de base de cette analyse. Une SDR est une municipalité (c.-à-d. une localité constituée en personne morale, une municipalité rurale, une ville, etc., selon la loi provinciale) ou son équivalent comme les réserves indiennes, les établissements indiens et les territoires non organisés. Dans le Recensement de la population de 2006, il y avait 5 418 SDR. Pour la description détaillée d'une SDR, voir Statistique Canada (2007). Les SDR peuvent varier beaucoup pour ce qui est de la taille de la population – de quelques habitants jusqu'à plus de deux millions à Toronto. En outre, l'étendue géographique d'une SDR peut varier beaucoup – de moins d'un kilomètre carré pour une petite ville rurale jusqu'aux vastes étendues géographiques des territoires dits « non organisés » dans la partie nord de nombreuses provinces. Les données au niveau des SDR sont regroupées par type de secteur, comme il est expliqué ci-après, selon la Classification des secteurs statistiques de Statistique Canada (Statistique Canada, 2007).
Les grands centres urbains comparés aux régions rurales et petites villes
Les grands centres urbains (GCU) sont composés de SDR classées en tant que parties des régions métropolitaines de recensement (RMR) et des agglomérations de recensement (AR).
- En 2006, on considérait qu'une RMR avait un noyau urbain de 50 000 habitants ou plus et une population de 100 000 habitants ou plus après l'ajout de toutes les SDR voisines dont 50 % ou plus de la population active résidente se déplaçait vers le noyau urbain de la RMR.
- En 2006, une AR avait un noyau urbain de 10 000 habitants ou plus et comprenait les SDR voisines dont 50 % ou plus de la population active résidente se déplaçait vers le noyau urbain de l'AR.
-
- Les grandes AR sont des agglomérations de recensement de 50 000 résidents ou plus. Ces AR englobent des secteurs de recensement désignés dans l'AR et sont aussi appelées AR subdivisées en secteurs de recensement.
- Les petites AR sont des agglomérations de recensement de moins de 50 000 habitants. Ces AR ne contiennent pas de secteurs de recensement désignés dans l'AR et elles sont aussi appelées « AR non subdivisées en secteurs de recensement ».
Les régions rurales et petites villes (RRPV) sont des SDR qui ne font pas partie d'une RMR ou d'une AR. Les RRPV sont ensuite classées en zone d'influence métropolitaine (ZIM), comme suit :
- Zone d'influence métropolitaine forte : SDR dans une RRPV dont 30 % ou plus de la population active résidente fait la navette vers une RMR ou une AR;
- Zone d'influence métropolitaine modérée : SDR dans une RRPV dont 5 % à 29 % de la population active résidente fait la navette vers une RMR ou une AR;
- Zone d'influence métropolitaine faible : SDR dans une RRPV dont plus de zéro mais moins que 5 % de la population active résidente fait la navette vers une RMR ou une AR;
- Zone d'influence métropolitaine nulle : SDR dans une RRPV dont la population active ne se déplace pas vers une RMR ou une AR pour travailler (ou dont la population active comprend moins de 40 travailleurs);
- Territoires des RRPV : SDR au Yukon, dans les Territoires du Nord-Ouest et au Nunavut située à l'extérieur des AR de Whitehorse et Yellowknife.
Population rurale du recensement
Ruralité au sens du recensement
: Il s'agit de la définition de ruralité utilisée dans le Recensement de la population de Statistique Canada. Sa définition a changé au fil du temps (voir annexe A dans du Plessis et coll., 2002). Il s'agit habituellement de la population qui vit à l'extérieur des agglomérations de 1 000 habitants ou plus. La définition actuelle énonce que la population rurale de recensement correspond à la population à l'extérieur des agglomérations de 1 000 habitants ou plus, dont la densité de la population atteint 400 habitants ou plus par kilomètre carré (Statistique Canada, 2007).
End of text box 1
Encadré 2
Données : Lieu de travail et navettage
Toutes les données utilisées dans cette analyse proviennent du Recensement de la population de 2006 et sont totalisées au niveau des subdivisions de recensement. Les données sont dérivées à partir des variables du lieu de travail et du lieu de résidence (déplacement domicile-travail), qui servent à produire les tableaux du navettage à partir du lieu de résidence au lieu de travail. Des détails sont présentés ci-après.
Données sur le lieu de travail
Les « données sur le lieu de travail » désignent les renseignements dérivés des réponses à la question sur le lieu de travail dans le Recensement de la population. En 2006, la question sur le lieu de travail figurait seulement dans le long questionnaire du recensement, lequel a été envoyé à un ménage sur cinq (échantillon de 20 % de la population). La question était formulée comme suit : « À quelle adresse cette personne travaillait-elle habituellement la plupart du temps? » Les choix de réponse étaient les suivants : 1) à domicile (y compris à la ferme); 2) à l'extérieur du Canada; 3) sans adresse de travail fixe; 4) à l'adresse précisée ci-dessous.
Les données sur le navettage (c.-à-d. les données utilisées dans cette analyse) sont dérivées seulement quand la réponse à cette question est 4) et qu'une adresse précise est donnée. Il convient de souligner qu'en 2006, pour les RMR et les AR, l'adresse de travail « précisée » était codée au niveau du côté d'îlot, de l'îlot de diffusion ou du point représentatif de l'aire de diffusion. Le lieu de travail des personnes travaillant dans les RRPV a été codé au niveau de points représentatifs des subdivisions de recensement (SDR) (Statistique Canada, 2007).
Tableaux du navettage
Les tableaux du navettage mesurent le nombre de personnes qui se déplacent entre les diverses régions du Canada. Chaque déplacement contient un point d'origine, une destination et un compte pour représenter le nombre de personnes qui voyagent du point d'origine à la destination. Les personnes qui se déplacent de A à B peuvent ensuite être décrites davantage par d'autres variables de recensement (comme l'âge, le sexe, la profession, le niveau de scolarité, etc.).
Subdivisions de recensement hors du champ d'observation
Toutes les SDR n'ont pu être regroupées dans des zones du marché du travail autonomes.
Dans l'ensemble des 5 418 SDR au Canada en 2006, il n'y avait aucun déplacement dans 1 256 SDR. Ces SDR étaient habituellement petites et, par conséquent, on n'y faisait aucun navettage ou les données sur le navettage ont été supprimées pour des raisons de qualité des données ou pour le maintien de la confidentialité. Ces SDR « hors du champ d'observation » comptaient 128 164 habitants (0,4 % de la population du Canada) (annexe, tableau A1).
Dans 336 autres subdivisions de recensement, il n'y avait aucun navettage en provenance ou à destination de la SDR, mais on constatait le navettage à l'intérieur de la SDR (c.-à-d. que certaines personnes ont choisi la réponse 4) « à l'adresse précisée ci-dessous » et ont donné une adresse dans la SDR donnée). Pour ce qui est des déplacements, ces SDR étaient autonomes à 100 %. Ces SDR englobaient deux types de SDR :
- Les SDR éloignées et pour lesquelles le navettage quotidien vers ces SDR ou les SDR avoisinantes est donc impossible. Il existe neuf SDR ayant une population de plus de 2 500 habitants qui sont autonomes à 100 % (annexe, tableau A1) et il est probable que ces SDR pourraient être décrites comme éloignées :
- Kitimat (Colombie-Britannique) (population de 2006 = 8 987);
- Revelstoke (Colombie-Britannique) (population de 2006 = 7 230);
- Iqaluit (Nunavut) (population de 2006 = 6 184);
- Mackenzie (Colombie-Britannique) (population de 2006 = 4 539);
- Grande Cache (Alberta) (population de 2006 = 3 783);
- Inuvik (Territoires du Nord-Ouest) (population de 2006 = 3 484);
- Lebel-sur-Quévillon (Québec) (population de 2006 = 2 729);
- Fermont (Québec) (population de 2006 = 2 633);
- St. Theresa Point (Manitoba) (population de 2006 = 2 632).
- De plus, il y a de petites SDR pour lesquelles le navettage est possible. Il convient de mentionner que les données sur le navettage ont été supprimées pour les SDR où l'on dénombrait moins de 20 travailleurs qui faisaient le navettage vers une autre SDR ou moins de 20 travailleurs qui faisaient le navettage à partir d'une autre SDR. Les villes suivantes de Saskatchewan sont des exemples de petites SDR :
- Sintaluta (population de 2006 = 98);
- Chamberlain (population de 2006 = 108);
- Alsask (population de 2006 = 129).
Chacune de ces villes est située le long d'une autoroute principale où se trouvent aussi d'autres villes à une distance raisonnable, ce qui laisse prévoir le navettage. Toutefois, il n'était pas surprenant de dénombrer moins de 20 navetteurs à destination ou en provenance d'une ville avoisinante.
Par conséquent, en raison de leur éloignement ou en raison du petit nombre de navetteurs, on dénombre 336 SDR qui sont dans le champ d'observation mais qui englobent leur propre zone de travail autonome à 100 %.
Les 3 826 SDR restantes ont été regroupées en 349 zones du marché du travail autonomes (annexe, tableau A1). Ces grappes représentent le plus haut niveau d'autonomie réalisable pour chaque groupement selon le modèle (encadré 3), lequel a nécessité une autonomie minimale pour chaque grappe selon une échelle mobile de 75 % à 90 %. Très peu de grappes ont été complètement définies par leur valeur minimale, le résultat moyen atteignant 96 % d'autonomie pour les 349 grappes visées par la discussion.
Il est intéressant de constater que quelques-unes des 3 826 SDR qui ont été attribuées à l'une des 349 grappes ne comptaient aucun travailleur résidant dans la SDR mais dénombraient certains navetteurs à destination de la SDR – ce qui peut être le cas si une usine ou une mine se trouve dans une municipalité adjacente à la ville constituée en personne morale où résident les travailleurs.
Il est important de faire ressortir que la fusion possible des 336 SDR ne comptant aucun navetteur avec les grandes grappes de ZTA ne peut être fondée sur des critères de navettage, mais doit plutôt être fondée sur d'autres critères. Dans cette analyse, nous n'avons intégré aucun autre critère (p. ex. la proximité) pour assigner ces SDR à une ZTA. Cela s'explique par le fait que le résultat de l'autonomie ou du manque de liens de navettage est une constatation intéressante en soi. Toutefois, lors de la discussion des résultats, nous ne concentrons pas notre attention sur ces 336 SDR qui semblent être des zones de travail autonomes à 100 %. Elles semblent constituer leur propre groupe qui mériterait un examen plus attentif (ou une possible nouvelle agrégation fondée sur des critères supplémentaires). Nous présentons certaines données sur ces SDR en annexe, dans les tableaux A1, A3 et A4.
End of text box 1
Encadré 3
Méthodologie
La délimitation des zones de travail autonomes (ZTA) a été fondée sur une procédure de formation de grappes au moyen des données sur le navettage réciproque. La méthode est dérivée de l'algorithme créé par Bond et Coombes (2007) et l'application de l'algorithme a été effectuée dans la langue de programmation SAS. Les principales caractéristiques de la méthode sont exposées ci-après tandis que les détails sont présentés dans un document technique à paraître (Munro et coll., à paraître).
Algorithme de mise en grappes : centré sur l'importance réciproque des déplacements
L'algorithme utilisé dans cette analyse comporte des caractéristiques précises qui le rendent utile pour découvrir les zones de travail rurales. Nous avons utilisé un algorithme fondé sur le principe de « l'importance réciproque » pour indiquer la force des liens entre deux subdivisions de recensement (SDR) données. L'algorithme à la base de la procédure de mise en grappes montre des liens forts entre deux zones si le navettage entre ces deux zones est proportionnellement important pour les deux zones. Plus précisément, notre mesure de l'importance réciproque (RI) est la suivante :
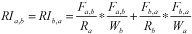
où F correspond aux navetteurs (nombre) qui se déplacent d'une SDR à une autre (a à b, ou b à a); R correspond au nombre de travailleurs qui résident dans la SDR (a ou b), peu importe où ils travaillent; W correspond au nombre de travailleurs qui travaillent dans la SDR, peu importe où ils vivent; et a et b sont les indices pour toute paire de SDR.
L'importance réciproque décrit notre volonté d'indiquer qu'un déplacement donné de A à B est proportionnellement important pour les zones « A » et « B ». Pour illustrer ce concept, prenons une situation où 100 travailleurs se déplacent de la zone A pour aller à la zone B. Si la zone A est une grande ville qui compte des centaines de milliers de travailleurs résidents, alors le départ de ces 100 travailleurs n'est pas particulièrement important pour la zone A. Toutefois, si la zone A est une très petite ville de seulement 200 travailleurs résidents au total, alors ce déplacement est très important pour la zone A. Par conséquent, un déplacement entre deux petites villes produirait une importance réciproque plus élevée (RI) que le même déplacement entre une petite agglomération et une grande. En conservant cet exemple, le concept d'importance réciproque signifie que l'algorithme aura tendance à regrouper ensemble les petites régions afin de produire de plus grandes augmentations d'autonomie (définition ci-après). Cela signifie que cet algorithme est plus susceptible que les autres algorithmes possibles de permettre de découvrir les zones de travail autonomes parmi des agglomérations relativement petites.
Voici d'autres caractéristiques essentielles de la procédure :
- Toutes choses étant égales, cette procédure a tendance à d'abord regrouper ensemble les petites zones. Cela se produit parce qu'un déplacement relativement faible peut représenter une proportion importante de navetteurs pour une petite zone et, par conséquent, produira des liens plus forts (c.-à-d. une plus grande RI) que si le navettage se produisait dans une plus grande zone. En outre, les grandes zones sont plus susceptibles d'avoir un plus grand nombre de zones qui contribuent ou qui reçoivent des navetteurs, ce qui entraîne une réduction relative de l'importance de chacun des liens.
- Comparativement aux méthodes de mise en grappes qui utilisent des régions urbaines prédéfinies comme points de départ pour chaque grappe, cette procédure réduit au minimum le biais urbain en effectuant une sélection répétée pour les SDR ou le groupe de SDR ayant le plus faible degré d'autonomie, peu importe la classification.
- Cette procédure nécessite un haut niveau d'autonomie pour les très petites zones, lequel empêche les petites zones de parvenir à l'étape finale tant qu'il reste d'importants déplacements, même si ces déplacements sont à destination ou en provenance d'une plus grande région urbaine.
Autonomie
L'autonomie est une mesure du niveau de travailleurs qui résident dans la zone A et qui travaillent aussi dans la zone A. Par conséquent, en regroupant les zones où l'importance réciproque du navettage est élevée et où l'autonomie est faible, nous pouvons créer de nouvelles zones qui auront un niveau de plus en plus élevé d'autonomie. Une fois que sera atteint un certain seuil d'autonomie, la zone sera alors considérée comme un marché du travail autonome parce que la plupart des résidents ayant un emploi travaillent dans la zone de travail donnée et que la plupart des personnes qui vivent dans la zone de travail donnée travaillent aussi dans cette zone du marché du travail donnée.
Il est important de souligner que l'autonomie est définie par deux composantes. La première est l'autonomie des travailleurs : le pourcentage de travailleurs d'une zone qui vivent aussi dans cette zone; et la deuxième est l'autonomie des résidents : le pourcentage de résidents d'une zone qui travaillent aussi dans cette zone. Dans le présent bulletin, chaque fois que nous utilisons l'expression d'autonomie, elle renvoie à l'ensemble de ces deux composantes.
Afin de définir un seuil d'autonomie, nous avons utilisé une échelle mobile qui nécessite un haut degré d'autonomie si la zone (SDR ou regroupement de SDR) compte une (plus) petite population active de résidents. Par conséquent, dans les SDR de moins de 1 000 travailleurs résidents, nous fixons le niveau d'autonomie minimal à 90 %. Pour les grandes SDR (de plus de 25 000 travailleurs résidents), notre niveau d'autonomie était inférieur (à 75 %). Ainsi, peu importe la taille de la zone, l'autonomie minimale d'une ZTA correspond à 75 %. Il y a deux raisons d'utiliser une échelle mobile pour établir le seuil d'autonomie. D'abord, pour faire en sorte que les petites zones de travail ne soient pas formées par l'exclusion des grands liens numériques, nous avons utilisé un seuil plus élevé d'autonomie quand une petite zone de travail est délimitée à titre de zone de travail autonome. Ensuite, afin d'éviter l'agglomération de toutes les régions urbaines au Canada en une énorme zone de travail, les grandes zones doivent avoir un seuil inférieur d'autonomie pour être désignées zone de travail autonome.
End of text box 1
- Date de modification :