
Publications
Bulletin d'analyse - Régions rurales et petites villes du Canada
Évolution de l'emploi dans les secteurs des ressources naturelles : accent sur les chaînes de valeur rurales
Données et définitions
 Consulter la version la plus récente.
Consulter la version la plus récente.
Information archivée dans le Web
L’information dont il est indiqué qu’elle est archivée est fournie à des fins de référence, de recherche ou de tenue de documents. Elle n’est pas assujettie aux normes Web du gouvernement du Canada et elle n’a pas été modifiée ou mise à jour depuis son archivage. Pour obtenir cette information dans un autre format, veuillez communiquer avec nous.
Encadré 1
Niveau géographique de l'analyse
Dans le présent bulletin, deux types de géographies sont utilisés : divisions de recensement et types de régions.
Le terme général division de recensement (DR) désigne des régions créées par les lois provinciales (comtés, municipalités régionales de comté, districts régionaux, etc.) ou leur équivalent. Les divisions de recensement sont des régions géographiques intermédiaires entre le niveau provincial/territorial et la municipalité (subdivision de recensement).
Dans notre étude, une division de recensement (DR) représente une région qui correspond à l'unité élémentaire géographique de base d'où proviennent les types de régions. Étant donné que les limites des DR changent d'un recensement à l'autre, nos données sont totalisées au moyen des limites géographiques constantes de 1996. On a dénombré 288 DR en 1996.
Le type régional se définit au moyen de la typologie de l'Organisation de coopération et de développement économiques (OCDE). Selon l'OCDE, une collectivité rurale a une densité de population correspondant à moins de 150 habitants au kilomètre carré. À partir de cette définition d'une collectivité rurale, la classification suivante des régions est utilisée par l'OCDE :
- Régions essentiellement rurales : plus de 50 % de la population réside dans une « collectivité rurale »;
- Régions intermédiaires : entre 15 % et 49 % de la population vit dans une « collectivité rurale »;
- Régions essentiellement urbaines : moins de 15 % de la population habite dans une « collectivité rurale ».
On subdivise les régions essentiellement rurales pour en reconnaître la diversité. Il y a trois types de régions essentiellement rurales : région rurale adjacente à une zone métropolitaine, région rurale non adjacente à une zone métropolitaine et régions rurales du Nord (Ehrensaft et Beeman, 1992).
Les Bulletins d'analyse – Régions rurales et petites villes du Canada abordent les questions qui intéressent le Canada rural, comme les tendances de l'emploi, les niveaux de scolarité, l'état de santé, l'utilisation d'Internet et le nombre d'entreprises par type, entre autres.
Comme le décrivent Puderer (2009) et du Plessis et coll. (2001), il y a plusieurs définitions opérationnelles possibles des régions urbaines et rurales. Dans le présent bulletin, nous utilisons la définition qui, selon nous, convient le mieux à cette analyse.
Fini encadré 1
Encadré 2
Source des données et définition de la chaîne de valeur des secteurs des ressources
Les données de l'emploi utilisées dans cette analyse proviennent des recensements de la population de 1991, de 1996 et de 2001 et visent la population active expérimentée pour les deux sexes de 15 ans et plus. La population active expérimentée désigne les personnes qui avaient un emploi pendant la semaine précédant le jour du recensement, en plus des personnes qui étaient sans emploi, mais qui avaient travaillé contre rémunération ou à leur compte depuis le 1er janvier de l'année précédente.
La délimitation des chaînes de valeur utilisée dans cette analyse est basée sur la Classification type des industries pour établissements de 1980 (ci-après la CTI-E) (Statistique Canada, 1980).
Aux fins de la présente recherche, nous avons défini des structures comparables de chaînes de valeur pour chaque secteur de ressources. Cinq secteurs des ressources naturelles sont concernés : (1) agriculture; (2) pêche; (3) foresterie; (4) mines; et (5) énergie. Le tableau A.1 en annexe indique les composantes comparables de la chaîne de valeur de chaque secteur des ressources, ainsi que les codes d'activité économique correspondants pour chaque composante dans chaque chaîne de valeur.
Nous utilisons les codes de la Classification type des industries (CTI-E), au lieu des codes plus récents du Système de classification des industries de l'Amérique du Nord (SCIAN) (Statistique Canada, 2003), parce que seuls les codes de la CTI-E peuvent être appliqués aux données du recensement pour 1991, 1996 et 2001. On obtient ainsi une meilleure perspective historique (une analyse semblable peut maintenant être effectuée grâce à une comparaison de 2001 et de 2006 au moyen de la classification du SCIAN). Les données de l'emploi du Recensement de la population ont été codées au niveau à trois chiffres de la CTI-E. Par conséquent, notre classification se limite au niveau à trois chiffres. L'ensemble complet des codes de la CTI-E qui peuvent être utilisés dans l'analyse est accessible en ligne sur la page Web de Statistique Canada (Statistique Canada, 1980).
Notre analyse vise principalement la production primaire, les services à la production primaire, le commerce de gros et la première transformation (c.-à-d. la fabrication). Au-delà de la première transformation, il devient de plus en plus difficile d'attribuer une industrie à une chaîne de valeur particulière. En fonction de la description détaillée des codes de la CTI-E (Statistique Canada, 1980), nous avons attribué des industries qui semblent avoir des corrélations raisonnablement solides avec le secteur des ressources naturelles. Pour certains codes d'activité économique, les tableaux d'entrées-sorties 2000 de Statistique Canada ont été utilisés pour vérifier les principales corrélations industrielles le long de la chaîne de production. Bien que nous n'ayons pas utilisé de seuils fixes, les tableaux d'entrées-sorties ont fourni des données suffisantes pour déterminer les principales corrélations afin d'attribuer le code de la CTI-E à une chaîne de valeur particulière.
Nous reconnaissons que la délimitation opérationnelle d'une chaîne de valeur, en général, et que le fondement sur un système de codes d'activité économique, en particulier, demeurent problématiques. D'abord, il est difficile en théorie de délimiter la chaîne parce que les corrélations sectorielles d'une étape à une autre de la transformation deviennent de plus en plus complexes à mesure que nous passons à des activités à valeur ajoutée des échelons supérieurs. Il y a plusieurs activités dont l'association avec un secteur donné est difficile, voire impossible à attribuer (ce problème est courant pour certains secteurs de services, comme les assurances, les transports, l'emballage, etc.). Une société d'assurance ou une entreprise de camionnage peut avoir des clients associés à différentes chaînes de valeur. Ainsi, ces établissements ne peuvent généralement pas être attribués à une chaîne de valeur donnée. La complexité et la durabilité des facteurs de production s'intensifient également à mesure que nous nous éloignons de l'étape de la production primaire, ce qui rend difficile l'attribution d'un établissement à une chaîne de valeur particulière. Ensuite, la délimitation d'une chaîne de valeur est problématique à cause de la façon dont les statistiques sur l'industrie sont déclarées. Par exemple, la Classification type des industries ne recoupe pas toujours une chaîne sectorielle particulière. En conséquence de ces difficultés, la définition opérationnelle d'une chaîne de valeur, même en termes sectoriels larges, laisse supposer un certain degré de simplification.
En dépit de ces contraintes, la classification présentée au tableau A.1 en annexe démontre nos efforts en vue d'établir un cadre qui permet une certaine comparabilité à l'étendue du principal secteur des ressources naturelles et qui autorise une analyse des variations dans l'espace et au fil du temps.
Fini encadré 2
Encadré 3
Méthodologie : Mesure de l'association spatiale
Pour évaluer la répartition spatiale des segments de la chaîne de valeur, nous utilisons un ensemble d'indicateurs et de méthodes d'analyse. Toutes ces méthodes reposent sur la définition des interactions spatiales telles qu'elles apparaissent dans la matrice de pondération spatiale.
Matrice de pondération spatiale (W). Une matrice de pondération spatiale définit la disposition spatiale des observations dans l'espace. Les éléments de la matrice, wi,j, expriment la présence ou l'absence d'interaction spatiale entre chaque paire d'emplacements possible, ainsi que le degré de cette interaction. Nous utilisons une matrice de pondération basée sur la distance. Par conséquent, la valeur wi,j est calculée comme l'inverse du carré de la distance entre les centroïdes géographiques de chaque paire de divisions de recensement (DR). Notre mesure des centroïdes correspond au centre géographique de chaque DR. Nous supposons qu'il existe une interaction dans le rayon de distance de 1 200 km entre les centroïdes de la DR, et au-delà de ce rayon, la valeur du poids est établie à zéro. La matrice est normalisée par ligne. La même matrice de pondération spatiale est utilisée dans tous les calculs ci-après.
Autocorrélation spatiale du segment de la chaîne de valeur. Une autocorrélation spatiale survient lorsque la répartition spatiale de la variable à l'étude affiche une tendance systématique. Le degré d'autocorrélation spatiale des segments de la chaîne de valeur se mesure par la statistique I de Moran, qui est définie pour chaque année de référence comme suit :
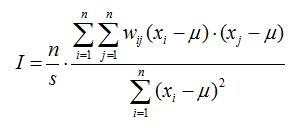
où wij est l'élément de la matrice de pondération spatiale W pour la paire d'observation i,j; x est l'indicateur à l'étude pour les emplacements i et j, la moyenne étant égale à μ; n est le nombre d'observations; et s est un coefficient d'échelle équivalant à la somme des éléments de W, qui dans le cas particulier de la matrice normalisée par ligne équivaut aussi à n (étant donné que la somme de chaque ligne est de 1). La valeur I de Moran est semblable mais pas équivalente à un coefficient de corrélation. Toutefois, la statistique n'est pas centrée autour de 0. La moyenne théorique de la valeur I de Moran est en fait -1/n-1. Cependant, la valeur I de Moran varie de -1 (autocorrélation spatiale négative parfaite) à +1 (autocorrélation spatiale positive parfaite).
Évaluation de l'association spatiale entre les segments de la chaîne de valeur. On peut démontrer que la valeur I de Moran est équivalente à l'inclinaison de la courbe de régression entre l'indicateur local et son décalage spatial. L'« indicateur local » que nous utilisons dans le présent document est le « quotient de localisation », tel que défini dans l'encadré 4. Pour évaluer le degré de corrélation spatiale entre un segment d'une chaîne de valeur et un autre segment de la même chaîne de valeur, nous estimons un ensemble de régressions :
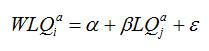
où WLQ est la valeur du décalage spatial du quotient de localisation pour un segment i de la chaîne de valeur a; et LQj est le quotient de localisation pour le segment j (i≠j) de la même chaîne de valeur a. Dans le tableau, nous déclarons la valeur des coefficients estimatifs β.
Mise en correspondance des régions dépendantes et du milieu régional. Les données utilisées dans les cartes correspondent à la classification obtenue par un nuage de points de Moran. Il s'agit d'un tracé de Wz par rapport à z, où W indique une matrice de pondération spatiale normalisée par ligne et z est la variable normalisée, qui dans notre cas est le quotient de localisation de la région i pour la chaîne de valeur a et la composante b. Chaque carte classe les régions en quatre catégories :
a) régions ayant une intensité de l'emploi régional au-dessus de la moyenne (c.-à-d. LQ>1) et une intensité de l'emploi au-dessus de la moyenne dans les environs de la région donnée (c.-à-d. une autocorrélation spatiale relativement élevée). Ce groupe est le noyau principal des régions fortement dépendantes;
b) régions au-dessus de la moyenne pour le premier indicateur et au-dessous de la moyenne pour le deuxième indicateur;
c) régions au-dessous de la moyenne pour le premier indicateur et au-dessus de la moyenne pour le deuxième indicateur; et
d) régions au-dessous de la moyenne pour les deux indicateurs. Ce groupe est le regroupement des régions non dépendantes.
Les mesures spatiales de l'autocorrélation sont calculées au moyen des modules de strates pour l'analyse spatiale (Pisati, 2001).
Fini encadré 3
Encadré 4
Méthodologie : concentration et emplacement
Coefficient géographique de Gini. Le coefficient de Gini est une des mesures les plus utilisées de la concentration. Nous utilisons la version géographique élaborée par Krugman (1993). Pour calculer le coefficient géographique de Gini (LG) pour l'industrie e, nous calculons la proportion de l'emploi dans la région i dans cette industrie (Se,i), par rapport à l'emploi national dans cette industrie et par rapport à la proportion régionale de toutes les industries (Stot,i). Le coefficient géographique de Gini est ensuite calculé au moyen de la formule suivante :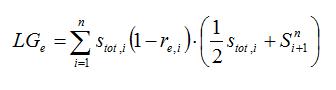
où 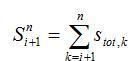 ) et re,i = Se,i/Stot,i en supposant que re,1< re,2< … < re,n.
) et re,i = Se,i/Stot,i en supposant que re,1< re,2< … < re,n.
Par conséquent, pour calculer les proportions cumulatives, le classement des régions s'effectue conformément au ratio re,i= Se,i/Stot,i, où la région ayant le ratio le plus faible est associée à la cote numéro 1. La valeur de ce coefficient oscille de 1 à 0, la valeur 1 laissant supposer une concentration maximale dans un seul emplacement et la valeur 0, une répartition parfaitement uniforme dans l'ensemble des régions.
Quotient de localisation. Le quotient de localisation (LQ) mesure l'intensité de l'emploi dans un secteur donné d'une région par rapport au niveau de l'emploi dans ce secteur à l'échelon national. Le LQ est présenté comme le ratio du pourcentage de l'emploi régional total dans un secteur par rapport au pourcentage de l'emploi total dans ce secteur à l'échelon national. Un LQ est calculé pour chaque composante de la chaîne de valeur. Par exemple :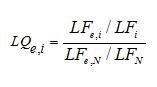
Description de l'équation 4
où LQe,i correspond à l'intensité relative de l'emploi dans le secteur « e » de la région « i » et LFe,i est la population active expérimentée dans le secteur « e » de la région « i ».
Les valeurs essentielles du LQ sont les suivantes : LQ >1 indique que la région a une intensité plus forte de l'emploi par rapport à l'ensemble du pays. LQ = 1 indique que l'intensité de l'emploi dans la région correspond à celle qu'on retrouve dans l'ensemble du pays. LQ < 1 indique que l'intensité de l'emploi dans la région est inférieure à celle qu'on retrouve dans l'ensemble du pays.
Par conséquent, une région dont le LQ>1 est relativement « spécialisée » par rapport à la moyenne nationale.
Fini encadré 4
- Date de modification :