4. Une application
Jiming Jiang, Thuan Nguyen et J. Sunil Rao
Précédent
Nous considérons une application des méthodes
développées aux sections précédentes aux données du TVSFP. Pour une description
complète de l'étude du TVSFP, voir Hedeker,
Gibbons et Flay (1994). L'étude originale a été conçue pour tester les
effets indépendants ainsi que combinés d'un programme de résistance sociale en
milieu scolaire, d'une part, et télévisé, d'autre part, concernant la
prévention et l'arrêt du tabagisme. Les sujets étaient des élèves de septième
année de Los Angeles (LA) et de San Diego, dans l'État de Californie, aux
États-Unis. Les élèves ont été prétestés en janvier 1986 dans le cadre d'une
première étude. Les mêmes élèves ont rempli un questionnaire directement après
l'intervention en avril 1986, un questionnaire de suivi un an plus tard (en avril
1987), et un questionnaire de suivi deux ans plus tard (en avril 1988). Dans la
présente analyse, nous considérons un sous-ensemble des données du TVSFP portant
sur les élèves de 28 écoles de Los Angeles, où les écoles ont été affectées aléatoirement à l'une de quatre
conditions d'étude : a) un programme scolaire de résistance sociale (PS);
b) une intervention médiatique (télévision) (TV); c) une combinaison des
conditions PS et TV; et d) un groupe de contrôle sans traitement. L'une
des principales variables de résultat de l'étude était la cote obtenue sur une
échelle des connaissances concernant le tabac et la santé (THKS pour tobacco and health knowledge scale), et est
celle utilisée dans la présente analyse. La THKS consistait en un questionnaire
à sept items utilisé pour évaluer les connaissances des élèves concernant le
tabac et la santé. La cote THKS de l'élève a été définie comme la somme des
items auxquels l'élève avait répondu correctement. Seules les données du prétest
et de l'évaluation directement après l'intervention sont disponibles pour la
présente analyse. Plus précisément, les données portent uniquement sur les
sujets qui avaient rempli le questionnaire THKS à ces deux points dans le temps.
D'une part, les données des enregistrements complets représentent une situation
« avant-après » idéale; d'autre part, les données manquantes, c'est-à-dire
celles fournies par les sujets qui ont rempli le questionnaire à un seul point
dans le temps, auraient pu fournir des renseignements supplémentaires utiles. Par
exemple, il se peut qu'un sujet n'ait pas rempli le questionnaire de suivi
parce qu'il n'avait pas trouvé le programme utile. Malheureusement, les données
incomplètes n'étaient pas disponibles. Par conséquent, l'analyse des
enregistrements complets seulement comporte un risque de biais de sélection. Dans
l'ensemble, l'échantillon comprenait 1 600 élèves répartis entre 28 écoles,
le nombre d'élèves provenant de chaque école variant de 18 à 137.
Hedeker et coll.
(1994) ont procédé à une analyse avec modèles mixtes basée sur un certain
nombre de modèles REE pour illustrer l'estimation du maximum de vraisemblance pour
l'analyse des données groupées. Ici, nous considérons le problème d'estimation
des moyennes de petit domaine de l'écart entre les cotes THKS (la réponse)
obtenues directement après l'intervention et au prétest. Ici, le « petit
domaine » s'entend d'un certain nombre de caractéristiques importantes (par exemple,
région de résidence, ratio enseignant/élèves) qui affectent la réponse, mais
dont ne rendent pas compte les covariables du modèle (c'est-à-dire combinaison
linéaire des indicateurs PS, TV et PSTV). Notons qu'habituellement, le terme « petit
domaine » fait référence à de petites régions géographiques ou sous-populations
pour lesquelles un échantillon adéquat n'est pas disponible (par exemple, Rao 2003), et des renseignements tels que les caractéristiques
résidentielles ou les ratios enseignant/élèves seraient utilisés comme covariables
supplémentaires. Cependant, les données sur ce genre de caractéristiques ne
sont pas disponibles. C'est pourquoi nous définissons cette information non
disponible comme étant « au niveau du domaine », afin qu'elle puisse
être traitée comme les effets aléatoires (de petit domaine). Cette approche est
en harmonie avec les caractéristiques fondamentales des effets aléatoires qui
sont souvent utilisées pour traduire les effets ou l'information inobservable (par exemple,
Jiang 2007), et étend la notion classique
d'estimation sur petits domaines. Donc, un petit domaine correspond aux élèves
de septième année dans toutes les écoles des États-Unis dont les
caractéristiques principales sont similaires à celles d'une école de Los Angeles
comprise dans les données durant une période raisonnable (par exemple, cinq ans)
afin que ni ces caractéristiques, ni la pertinence sociale/éducative des
programmes PS et TV n'aient beaucoup évolué au fil du temps. Les données du
TVSFP englobent 28 écoles de Los Angeles qui correspondent à 28 ensembles
de caractéristiques, de sorte que les données sont considérées comme des
échantillons aléatoires provenant de 28 petits domaines définis comme il
est indiqué plus haut. Ainsi, chaque
population de petit domaine est suffisamment grande pour que
Rappelons que les
dans l'échantillon TVSFP varient
de 18 à 137, tandis que les
devraient être au moins de
l'ordre de dizaines de milliers. Notons que, dans le calcul de la MPO, le seul
endroit où il est nécessaire de connaître
est dans le ratio
Le modèle REE proposé peut être exprimé comme en
(1.1) avec
où
dans le cas PS, et autrement;
dans le cas TV, et autrement.
Il s'ensuit que les données auxiliaires
sont des données au niveau du
domaine; par conséquent, la valeur de
est connue pour chaque
Comme nous l'avons mentionné, les tailles
d'échantillon de certains petits domaines sont assez grandes, mais il existe
aussi des domaines dont les tailles d'échantillon sont relativement parlant (beaucoup)
plus petites, ce qui est assez fréquent dans les situations réelles. Comme les
données auxiliaires sont des données au niveau du domaine, nous avons
donc, il est facile de
montrer que le MP (1.5) peut être exprimé sous la forme
Nous
voyons que, quand
est grand, le MP
est approximativement égal à
l'estimateur sous
le plan de sondage, qui n'a rien à voir avec l'estimation du paramètre. Par
conséquent, quand
est grand, la
différence entre la MPO et le MPLSBE est faible. Par contre, si
est petit ou
moyen, nous nous attendons à observer une certaine différence entre la MPO et le
MPLSBE en ce qui concerne l'EQMP. Cependant, il est difficile de dire quelle
est la grandeur de cette différence dans le présent exemple sur données réelles.
Nos résultats de simulation de la section 2 montrent que la différence
entre la MPO et le MPLSBE concernant l'EQMP dépend de la mesure dans laquelle la
spécification du modèle supposé est inexacte. Il convient de souligner que la réponse,
est la différence
entre les cotes THKS, et que les valeurs possibles de la cote THKS sont des
nombres entiers compris entre 0 et 7. Manifestement, de telles données ne
suivent pas une loi normale. L'effet possible de la non-normalité est double. D'une
part, il est probable que le modèle REE, tel qu'il est proposé par Hedeker et coll.
(1994), est spécifié incorrectement, auquel cas l'expression (1.5) n'est plus le
MP, et les estimateurs du MV (MVR) gaussien ne sont plus les vrais estimateurs
du MV (MVR). D'autre part, même si les données ne suivent pas une loi normale, il
reste possible de justifier que (1.5) est le meilleur prédicteur linéaire (MPL;
par exemple, Searle,
Casella et McCulloch 1992, section 7.3). En outre, les estimateurs du
MV (MVR) gaussiens sont convergents et asymptotiquement normaux, même sans
l'hypothèse de normalité (Jiang 1996; voir
aussi Jiang 2007, chapitre 1). D'autres
aspects du modèle REE comprennent l'homoscédasticité de la variance de l'erreur
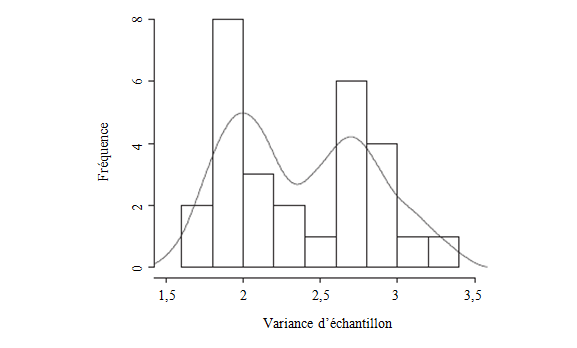
sur l'ensemble des petits domaines. La figure 4.1 montre l'histogramme des
variances d'échantillon des 28 petits domaines. La forme bimodale de l'histogramme
donne à penser que la variance de l'erreur pourrait être hétéroscédastique, soit
encore un autre type possible de spécification inexacte du modèle. Par
conséquent, la méthode de la MPO est un choix naturel.
Figure 4.1 Histogramme des variances d’échantillon; un lisseur à noyau de la densité est ajusté
Description de la figure 4.1
Nous effectuons l'analyse de la MPO
pour les 28 petits domaines et les résultats sont présentés au
tableau 4.1. Les MEP des paramètres sont
et
Bien que l'on puisse donner
une interprétation des estimations des paramètres, il se pourrait que la
spécification du modèle soit inexacte (auquel cas l'interprétation pourrait ne
pas avoir de sens), comme nous l'avons mentionné plus haut. Quoi qu'il en soit,
nous nous intéressons principalement à la prédiction et non à l'estimation; donc,
nous nous concentrons sur la MPO. En plus des MPO, nous calculons aussi les
estimateurs
correspondants, et leurs racines carrées comme
mesures de l'incertitude. Aux fins de comparaison, nous incluons aussi dans le
tableau les MPLSBE pour les petits domaines, ainsi que les racines carrées des
estimations de l'EQMP correspondantes,
en utilisant la méthode de Prasad-Rao (P-R; Prasad et Rao 1990). Nous
voyons que les MPO sont toutes positives, même pour les petits domaines dans le
groupe de contrôle. En ce qui concerne la signification statistique (ici, la
« signification » est définie comme le fait que la MPO est plus
grande en valeur absolue que 2 fois la racine carrée de l'estimation de
l'EQMP correspondante), les moyennes de petit domaine sont significativement
positives pour tous les petits domaines du groupe (1,1). Par contre, aucune des
moyennes de petit domaine n'est significativement positive pour les petits
domaines du groupe (0,0). Pour les deux autres groupes, les moyennes de petit
domaine sont significativement positives pour tous les petits domaines du
groupe (1,0), tandis qu'elles sont significativement positives pour tous les
petits domaines sauf deux du groupe (0,1). Les groupes (0,0), (0,1), (1,0) et
(1,1) contiennent 7, 8, 7 et 7 petits domaines, respectivement.
Tableau 4.1
MPO, MPLSBE, mesures de l’incertitude pour les données du TVSFP (Partie 1)
Sommaire du tableau
Le tableau montre les résultats de MPO. Les données sont présentées selon ID (titres de rangée) et PS, TV, MPO, , MPLSBE et (figurant comme en-tête de colonne).
| ID |
PS |
TV |
MPO |
|
MPLSBE |
|
| 403 |
1 |
0 |
0,886 |
0,171 |
0,913 |
0,121 |
| 404 |
1 |
1 |
0,844 |
0,296 |
0,856 |
0,121 |
| 193 |
0 |
0 |
0,215 |
0,207 |
0,217 |
0,120 |
| 194 |
0 |
0 |
0,221 |
0,137 |
0,221 |
0,134 |
| 196 |
1 |
0 |
0,878 |
0,171 |
0,907 |
0,124 |
| 197 |
0 |
0 |
0,225 |
0,158 |
0,223 |
0,126 |
| 198 |
1 |
1 |
0,771 |
0,220 |
0,807 |
0,131 |
| 199 |
0 |
1 |
0,426 |
0,142 |
0,453 |
0,130 |
| 401 |
1 |
1 |
0,826 |
0,133 |
0,844 |
0,127 |
| 402 |
0 |
0 |
0,188 |
0,171 |
0,199 |
0,123 |
| 405 |
0 |
1 |
0,394 |
0,147 |
0,432 |
0,129 |
| 407 |
0 |
1 |
0,508 |
0,300 |
0,508 |
0,133 |
| 408 |
1 |
0 |
0,871 |
0,240 |
0,903 |
0,123 |
| 409 |
0 |
0 |
0,230 |
0,125 |
0,227 |
0,136 |
Tableau 4.2
MPO, MPLSBE, mesures de l’incertitude pour les données du TVSFP (Partie 2)
Sommaire du tableau
Le tableau montre les résultats de MPO. Les données sont présentées selon ID (titres de rangée) et PS, TV, MPO, , MPLSBE et (figurant comme en-tête de colonne).
| ID |
PS |
TV |
MPO |
|
MPLSBE |
|
| 410 |
1 |
1 |
0,778 |
0,304 |
0,813 |
0,124 |
| 411 |
0 |
1 |
0,409 |
0,195 |
0,444 |
0,115 |
| 412 |
1 |
0 |
0,913 |
0,219 |
0,930 |
0,126 |
| 414 |
1 |
0 |
0,929 |
0,257 |
0,941 |
0,127 |
| 415 |
1 |
1 |
0,869 |
0,199 |
0,872 |
0,135 |
| 505 |
1 |
1 |
0,790 |
0,154 |
0,818 |
0,136 |
| 506 |
0 |
1 |
0,389 |
0,169 |
0,428 |
0,134 |
| 507 |
0 |
1 |
0,426 |
0,148 |
0,452 |
0,135 |
| 508 |
0 |
1 |
0,411 |
0,108 |
0,442 |
0,136 |
| 509 |
1 |
0 |
0,915 |
0,097 |
0,929 |
0,143 |
| 510 |
1 |
0 |
0,880 |
0,119 |
0,905 |
0,143 |
| 513 |
0 |
0 |
0,185 |
0,215 |
0,197 |
0,123 |
| 514 |
1 |
1 |
0,866 |
0,144 |
0,870 |
0,140 |
| 515 |
0 |
0 |
0,180 |
0,102 |
0,192 |
0,143 |
Si l'on compare la MPO au MPLSBE, les valeurs
du second sont généralement plus élevées, et les estimations de l'EQMP correspondantes
sont en majeure partie plus faibles. Du point de vue de la signification
statistique, les résultats du MPLSBE sont significatifs pour les groupes (1,1),
(1,0) et (0,1), et non significatifs pour le groupe (0,0). Il convient de
souligner que l'estimateur P-R de l'EQMP du MPLSBE est calculé sous l'hypothèse
de normalité, alors qu'ici, les données ont clairement une distribution non normale,
comme il est mentionné plus haut. Donc, il se peut que la mesure de l'incertitude
pour le MPLSBE ne soit pas exacte. En particulier, le fait que les (racines
carrées des) EQMP pour les MPLSBE sont plus faibles, comparativement à celles des
MPO ne signifie pas nécessairement que les EQMP réelles correspondantes des
MPLSBE sont plus faibles que celles des MPO. En fait, nos résultats de
simulation (voir la section 2) ont montré l'opposé. Nous constatons aussi que
les estimations de l'EQMP des MPLSBE sont plus homogènes dans les divers petits
domaines. Cela pourrait tenir au fait que l'estimateur P-R de l'EQMP du MPLSBE est
obtenu en supposant que le modèle REE est correct, alors que l'estimateur
proposé de l'EQMP pour la MPO ne s'appuie pas sur une telle hypothèse.
En conclusion, malgré les différences
possibles entre les caractéristiques des petits domaines, les programmes PS et
TV semblaient améliorer les cotes THKS des élèves (savoir si les meilleures
cotes THKS signifient que la prévention et l'arrêt du tabagisme sont améliorés
est toutefois une autre question). Il semble aussi que le programme PS était relativement
plus efficace que le programme TV. Sans l'intervention d'un de ces programmes, la
cote THKS ne semblait pas s'améliorer en ce qui concerne les moyennes de petit
domaine. Pour ce qui est de la signification statistique des résultats, pour PS = 0
et TV = 0, la cote THKS ne semblait pas être améliorée; pour PS = 1,
la cote THKS paraissait être améliorée; et pour PS = 0 et
TV = 1, l'amélioration de la cote THKS n'était pas convaincante.
Remerciements
Les travaux de Jiming Jiang sont financés partiellement par les subventions
DMS-0809127 et SES-1121794 de la NSF. Les travaux de Thuan Nguyen sont financés partiellement par la subvention
SES-1118469 de la NSF. Les travaux de J. Sunil
Rao sont financés partiellement par les subventions DMS-0806076 et
SES-1122399 de la NSF. La recherche des trois auteurs est financée
partiellement par la subvention R01-GM085205A1 du NIH. Les auteurs remercient le
professeur Donald Hedeker d'avoir eu
l'amabilité de fournir les données du TVSFP pour l'analyse. Enfin, les auteurs remercient
le rédacteur associé et deux examinateurs de leurs commentaires.
Annexe
A.1.
MPO sous régression à erreurs emboîtées. L'EQMP basée sur le plan de sondage est donnée
par (1.6). Notons que toutes les espérances
et plus tard les
prédictions
sont basées sur
le plan de sondage, en supposant un échantillonnage aléatoire simple. Notons
que En outre, notons
que
et
et
sont les estimateurs
sans biais sous le plan des moyennes de sous-population correspondantes).
Donc, nous avons
Par
conséquent, en utilisant la notation présentée sous (1.7), nous avons
Nous
pouvons exprimer le paramètre
inconnu dans
(A.1) par
Nous avons
également besoin d'un estimateur sans biais sous le plan de
qui est donné
par (1.8). Autrement dit, nous avons
Pour montrer
l'absence de biais sous le plan de (1.8), notons que
où
est l'ensemble
d'indices échantillonnés correspondant au
petit domaine. En
outre, nous avons
et
Donc,
après combinaison des éléments, nous obtenons
Il
s'ensuit que le deuxième membre de (A.1) peut être exprimé sous la forme
Le
MEP s'obtient en minimisant l'expression à l'intérieur de l'espérance, qui
correspond à (1.7).
Bibliographie
Battese, G.E., Harter, R.M. et Fuller, W.A. (1988). An error-components model for prediction of county crop areas using survey and satellite data. Journal of the American Statistical Association, 83, 401, 28-36.
Chatterjee, S., Lahiri, P. et Li, H. (2008). Parametric bootstrap approximation to the distribution of EBLUP and related prediction intervals in linear mixed models. The Annals of Statistics, 36, 3, 1221-1245.
Datta, G.S., Kubokawa, T., Molina, I. et Rao, J.N.K. (2011). Estimation of mean squared error of model-based small area estimators. Test, 20, 367-388.
Efron, B. (1979). Bootstrap method: Another look at the jackknife. The Annals of Statistics, 7, 1, 1-26.
Efron, B., et Tibshirani, R.J. (1993). An Introduction to the Bootstrap, Chapman & Hall/CRC.
Fay, R.E., et Herriot, R.A. (1979). Estimates of income for small places: An application of James-Stein procedures to census data. Journal of the American Statistical Association, 74, 366a, 269-277.
Hall, P., et Maiti, T. (2006). Nonparametric estimation of mean-squared prediction error in nested-error regression models. The Annals of Statistics, 34, 4, 1733-1750.
Hedeker, D., Gibbons, R.D. et Flay, B.R. (1994). Random-effects regression models for clustered data with an example from smoking prevention research. Journal of Consulting and Clinical Psychology, 62, 4, 757-765.
Jiang, J. (1996). REML estimation: Asymptotic behavior and related topics. The Annals of Statistics, 24, 1, 255-286.
Jiang, J. (2007). Linear and Generalized Linear Mixed Models and Their Applications, New York : Springer.
Jiang, J., et Nguyen, T. (2012). Small area estimation via heteroscedastic nested-error regression. The Canadian Journal of Statistics/La revue canadienne de statistique, 40, 3, 588-603.
Jiang, J., Lahiri, P. et Wan, S.-M. (2002). A unified jackknife theory for empirical best prediction with estimation. The Annals of Statistics, 30, 6, 1782-1810.
Jiang, J., Nguyen, T. et Rao, J.S. (2011). Best predictive small area estimation. Journal of the American Statistical Association, 106, 494, 732-745.
Lahiri, P. (2012). Estimation of average design-based mean squared error of synthetic small area estimators. Présenté au 40th Annual Meeting of the Statistical Society of Canada, Guelph, ON.
Nandram, B., et Sun, Y. (2012). A Bayesian model for small area under heterogeneous sampling variances. Rapport technique.
Prasad, N.G.N., et Rao, J.N.K. (1990). The estimation of mean squared errors of small area estimators. Journal of the American Statistical Association, 85, 409, 163-171.
Rao, J.N.K. (2003). Small Area Estimation, New York : John Wiley & Sons, Inc.
Searle, S.R., Casella, G. et McCulloch, C.E. (1992). Variance Components, New York : John Wiley & Sons, Inc.
Torabi, M., et Rao, J.N.K. (2012). Estimation of mean squared error of model-based estimators of small area means under a nested error linear regression model. Rapport technique.
Précédent
