6. Évaluations empiriques
Piero Demetrio Falorsi et Paolo Righi
Précédent | Suivant
Plusieurs simulations ont été exécutées
sur des ensembles de données réelles et de données simulées pour étudier les
propriétés empiriques de la stratégie d’échantillonnage proposée. Ici, nous
montrons les résultats obtenus pour un seul exercice portant sur des données
réelles se rapportant à la population d’entreprises de 1999 dont le nombre
d’employés était compris entre 1 et 99 et qui appartenaient au secteur des
Activités informatiques (code à deux chiffres de la Nomenclature statistique des activités économiques dans la Communauté
européenne, Rév. 1, dont l’acronyme est NACE). Nous avons effectué
trois expériences. L’expérience (a) avait pour but de vérifier si la
répartition obtenue au moyen de l’algorithme proposé convergeait vers la
solution de l’algorithme de Chromy sous le plan EASSRS. L’expérience
(b) visait à comparer les tailles d’échantillon du plan EASSRS classique
avec celles du plan d’échantillonnage stratifié incomplet (ESI), dans lequel
les strates définies par classification croisée étaient des sous-populations
non planifiées; cette expérience consistait à étudier le risque de fardeau
statistique dû à la sélection répétée lors de différentes éditions de
l’enquête. Enfin, l’expérience (c) avait pour objet de mesurer les discordances
entre le coefficient de variation (CV) prévu calculé par l’algorithme et le CV
empirique obtenu par une simulation Monte Carlo.
Dans les trois expériences, les valeurs
de
ont été fixées uniformément à 1. La variance
anticipée obtenue conformément à l’approximation proposée à la
remarque 4.1 a également été calculée.
La taille de la population choisie pour
les expériences était de
entreprises. Les domaines d’intérêt
définissaient deux partitions de la population cible, à savoir la région géographique, avec
20 domaines marginaux (DOM1), et le groupe
d’activités économiques (code à 3 chiffres de la NACE avec
6 groupes distincts) selon la classe
de taille (définie en fonction du nombre d’employés :
avec 24 domaines marginaux (DOM2). Le
nombre global de domaines marginaux était égal à 44, tandis que le nombre de
strates formées par classification croisée ou de strates multidimensionnelles
ayant une taille de population non nulle était de 360. La valeur modale de la
distribution des tailles de population était de 1, et 29,17 % des strates
formées par classification croisée ne contenaient au plus que 2 unités. Ce type
de strate représente un problème critique dans le contexte des approches
d’échantillonnage stratifiées classiques. En effet, pour calculer des
estimations de variance sans biais, ces strates doivent être à tirage complet
(afin qu’elles ne contribuent pas à la variance des estimations), alors que la
règle de répartition exigerait un moins grand nombre d’unités et, en général,
un nombre non entier d’unités échantillonnées. Le coût de la main-d’œuvre et la valeur
ajoutée étaient les variables d’intérêt pour lesquelles les données sont
fournies par une source administrative pour chaque unité de la population.
Habituellement, les deux variables ont une distribution fortement asymétrique.
Pour toutes les études empiriques, les
estimations cibles étaient les 88 totaux au niveau du domaine (2 variables fois 44 domaines marginaux). Dans chaque expérience, les
probabilités d’inclusion ont été déterminées en fixant la variance
dans (5.1), ce qui équivaut à fixer à
10 % le niveau accepté maximal du CV en pourcentage des estimations au
niveau du domaine.
Étude empirique (a). La première expérience tenait compte
de la partition DOM1. Ces domaines représentaient à la fois les domaines planifiés et les domaines d’estimation. Puisque les domaines
planifiés définissaient une partition de la population d’intérêt, ils pouvaient
également être considérés comme des strates dans les plans d’échantillonnage
classiques. Le modèle de travail prédictif était donné par
où
est un effet
fixe et les variances dans la superpopulation
étaient
estimées au moyen de la variance résiduelle du modèle prédictif dans chaque
région. L’algorithme proposé à la section 5 a été exécuté en utilisant
trois valeurs initiales distinctes des probabilités d’inclusion
égales à
0,01, 0,50 et 0,99, respectivement. Les valeurs initiales des probabilités
d’inclusion n’avaient aucune incidence sur la solution finale, mais celle-ci
était obtenue à la suite d’un nombre différent d’itérations. Nous constatons que
le nombre global de boucles internes était de 17 pour
La
convergence a été obtenue avec 13 boucles internes pour
14
boucles internes ont été nécessaires pour
Cependant, après la neuvième itération, les
trois tailles d’échantillon étaient relativement similaires (figure 6.1).
Dans l’expérience, les tailles d’échantillon globales étaient de 3 105
pour la répartition de Chromy servant de référence et de 3 110 pour la
méthode proposée ici. Cependant, les différences entre les deux tailles
d’échantillonnage au niveau du domaine étaient des nombres fractionnaires qui
étaient toujours inférieurs à 1, et la différence relative absolue la plus
importante était inférieure à 0,3 %. Cela met en relief le fait que
l’algorithme proposé définit en fait les mêmes tailles d’échantillon de domaine
que celles calculées pour la répartition de référence. En ce qui concerne la
convergence, les valeurs initiales des probabilités d’inclusion n’ont aucune
incidence sur la solution finale, quoique celle-ci soit obtenue moyennant des
nombres différents d’itérations.
Figure 6.1 Convergence de l’algorithme avec différentes
probabilités d’inclusion initiales dans l’étude empirique (a)
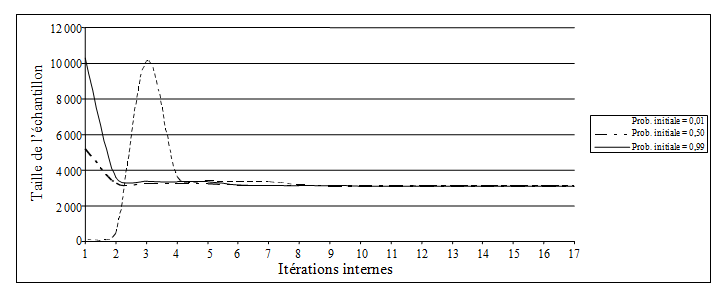
Description de la figure 6.1
Des résultats similaires ont été
obtenus quand les domaines d’intérêt étaient définis par la partition DOM2.
Études empiriques (b). Soit
une
région particulière
de DOM1, et soit
(avec
un
groupe d’activités économiques particulier selon la classe de taille
d’entreprise de la partition DOM2. Nous avons utilisé deux modèles de
prédiction,
et
En se référant à
la notation des modèles ANOVA,
est le
modèle saturé donné par
dans
lequel
et
sont les effets
principaux, reliés aux domaines
et
respectivement,
et où
est l’effet
d’interaction. Les variances de modèle
ont été estimées
par la méthode des moindres carrés ordinaires en calculant les variances des
termes résiduels au niveau
Le modèle
est identique au
modèle
sans le facteur
d’interaction. Le tableau 6.1 montre la qualité de l’ajustement des deux
modèles.
Tableau 6.1
Qualité de l’ajustement des modèles utilisés pour la prédiction
Sommaire du tableau
Le tableau montre les résultats de Qualité de l’ajustement des modèles utilisés pour la prédiction. Les données sont présentées selon Modèle (titres de rangée) et Qualité de l’ajustement (figurant comme en-tête de colonne).
| Modèle |
Qualité de l’ajustement |
| Coût de la main-d’œuvre |
Valeur ajoutée |
| Modèle (expression 6.2) |
68,1 |
64,1 |
| Modèle (expression 6.2 sans les interactions) |
65,1 |
61,0 |
Dans le cas du modèle
nous avons considéré trois
répartitions différentes pour l’EASSRS : i) aucune contrainte de taille d’échantillon de strate n’est
imposée; ii) au moins une unité
échantillonnée par strate est requise (pour obtenir des estimations ponctuelles
sans biais); iii) au moins
deux unités échantillonnées par strate sont requises (pour obtenir des
estimations de variance sans biais) pour toutes les strates ayant une taille de
population de deux entreprises ou plus. Les deux premières répartitions
sont plutôt théoriques, puisque dans toutes les enquêtes-entreprises réalisées
par l’Institut national de statistique de l’Italie, la sélection d’au moins
deux unités par strate est requise. Les résultats de l’expérience sont présentés
plus bas au tableau 6.2. Seuls les résultats pour le cas où les
probabilités d’inclusion initiales étaient égales à
sont examinés ici; des
tailles d’échantillon identiques ont été obtenues pour les autres valeurs
initiales des probabilités d’inclusion, avec un processus de convergence un peu
plus lent. Les trois plans EASSRS comptaient 716,6, 944 et 1 042 unités
d’échantillonnage, respectivement. Le plan d’échantillonnage stratifié
incomplet (ESI) a donné 936 unités pour le modèle
tandis qu’il a donné
991 unités pour le modèle
Le meilleur résultat donné
par le modèle
comparativement au modèle
tenait au fait que son
ajustement était meilleur. Enfin, les plans ESI ont aidé à aborder la question
du fardeau statistique des entreprises répondantes. En effet, si l’on suppose
que les probabilités d’inclusion restent fixes pour les différentes éditions de
l’enquête, leurs distributions peuvent être utilisées pour évaluer le fardeau
statistique dans les enquêtes répétées. Le tableau 6.2 montre que le
nombre d’entreprises sélectionnées avec certitude lors de chaque édition de
l’enquête était de 175 pour le troisième plan EASSRS, tandis que 30 et
40 entreprises ont été sélectionnées avec certitude sous le premier et le
deuxième plan ESI, respectivement. L’analyse des tailles (mesurées par
l’effectif) des entreprises incluses dans l’échantillon avec certitude montre
que, dans le cas du troisième plan EASSRS, la taille moyenne était égale à
20,6. Dans certains cas, des entreprises comptant deux employés étaient
incluses dans l’échantillon sélectionné avec certitude. Inversement, nous
constatons que dans le cas du premier et du deuxième plan ESI, la taille
minimale des entreprises était de 17 et 16 employés, respectivement, et
que la taille moyenne était supérieure à 40 unités.
Tableau 6.2
Tailles d’échantillon et répartition des entreprises incluses avec certitude dans l’échantillon, pour différents plans d’échantillonnage
Sommaire du tableau
Le tableau montre les résultats de Tailles d’échantillon et répartition des entreprises incluses avec certitude dans l’échantillon. Les données sont présentées selon Plan d’échantillonnage (titres de rangée) et Taille de l’échantillon , Entreprises sélectionnées avec certitude, Nombre et Nombre d’employés(figurant comme en-tête de colonne).
| Plan d’échantillonnage |
Taille de l’échantillon |
Entreprises sélectionnées avec certitude |
| Nombre |
Nombre d’employés |
| Moyen |
Minimum |
| Stratifié classique avec le modèle
|
Pas de contrainte de taille d’échantillon de strate |
716,6 |
10 |
47,0 |
23,0 |
| Au moins une unité échantillonnée par strate |
944,0 |
119 |
24,0 |
2,0 |
| Au moins deux unités échantillonnées par strate |
1 042,0 |
175 |
20,6 |
2,0 |
| Échantillonnage stratifié incomplet avec le modèle
|
936,0 |
30 |
50,1 |
17,0 |
| Échantillonnage stratifié incomplet avec le modèle
sans interactions |
991,0 |
40 |
42,9 |
16,0 |
Enfin, pour évaluer la sensibilité de
la solution, nous avons répété l’expérience artificiellement et modifié les
valeurs de
et
dans le problème d’optimisation
(5.1). En particulier, nous avons augmenté les valeurs prédites de
de 20 % et 120 % respectivement,
et diminué de 20 % les valeurs de
prédites par le modèle
Comme prévu, les tailles
d’échantillon ont augmenté, mais le plan EASSRS avec au moins une unité
échantillonnée par strate et le premier plan ESI ont défini approximativement
les mêmes tailles d’échantillon (tableau 6.3).
Tableau 6.3
Tailles d’échantillon avec valeurs prévues modifiées des prédictions du modèle (4.1)
Sommaire du tableau
Le tableau montre les résultats de Tailles d’échantillon avec valeurs prévues modifiées des prédictions du modèle (4.1). Les données sont présentées selon Plan d’échantillonnage (titres de rangée) et Taille de l’échantillon (figurant comme en-tête de colonne).
| Plan d’échantillonnage |
Taille de l’échantillon |
|
augmenté de 20 % |
augmenté de 120 % |
diminué de 20 % |
| EASSRS avec modèle
|
Aucune contrainte de taille d’échantillon de strate |
821,0 |
1 269,0 |
993,8 |
| Au moins une unité échantillonnée par strate |
1 035,0 |
1 472,0 |
1 206,0 |
| Au moins deux unités échantillonnées par strate |
1 125,0 |
1 536,0 |
1 283,0 |
| Plan ESI avec modèle
|
1 039,7 |
1 460,9 |
1 207,5 |
Étude empirique (c). Nous avons utilisé le modèle de prédiction linéaire hétéroscédastique
où
est le nombre d’employés dans la
entreprise,
et
et
sont les
paramètres de régression. Notons que le nombre d’employés est disponible dans
la base de sondage en Italie.
Nous avons calculé
deux estimations différentes de la variance du modèle :
a)
et b)
dans lesquelles
où
est la population
d’entreprises, de taille
pour laquelle la
variable
prend la valeur
et
sont les
estimations de
et
respectivement,
par les moindres carrés pondérés pour la population dénombrée complète. La
somme des variances de modèle obtenue par la méthode (a) était plus faible que
celle obtenue par la méthode (b). Cela a été reflété par les tailles
d’échantillon calculées. La première répartition définit une taille
d’échantillon global de 927 unités, tandis que la deuxième répartition définit
une taille d’échantillon de 951. Nous avons tiré successivement 1 000 échantillons
pour chacune des répartitions et avons calculé les ratios
avec
représentant le
CV prévu (%) et
représentant
le CV simulé (ou empirique), obtenu comme résultat de la simulation, en
désignant par
l’estimation HT
dans la
itération
et
Par souci de
concision, seuls les principaux résultats de la répartition (b) sont présentés
à la figure 6.2 pour DOM1 et DOM2, respectivement, pour les deux variables
d’intérêt. En examinant la figure de gauche, nous remarquons que la simulation
produit généralement un CV plus petit que le CV prévu, ce qui donne un ratio
RCV plus grand que 1 pour les deux variables. Une exception a lieu, pour
la valeur ajoutée dans un domaine de DOM1.
Figure 6.2 RCV selon la
taille de la population pour le coût de la main-d’œuvre et la valeur ajoutée
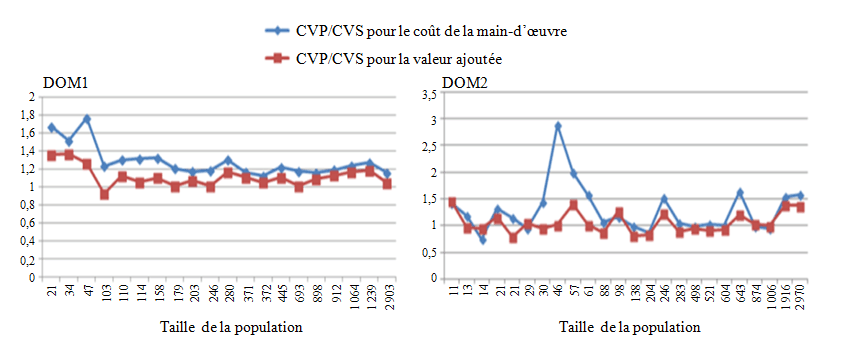
Description de la figure 6.2
La valeur de RCV inférieure à 1 peut
être expliquée par l’augmentation des tailles d’échantillon de domaine en
raison de l’étape de calage. Nous constatons qu’en général, ces divergences
sont observées dans des domaines dont la taille de population est petite; donc,
l’étape de calage peut avoir un effet non négligeable. La figure de droite
présente des données empiriques plus articulées et conflictuelles.
Premièrement, nous constatons que les RCV sont souvent plus grands que 1 ou
très proches de 1. Néanmoins, dans trois domaines, la variable de valeur
ajoutée possède un CV simulé égal à 11,5 %, 12,0 % et 12,3 %,
respectivement. Dans ces cas rares, et certains autres (coût de la main-d’œuvre
dans deux domaines), les divergences sont en harmonie avec les
constatations de Deville et Tillé (2005) quant aux propriétés empiriques
de l’approximation de la variance pour l’échantillonnage équilibré.
Précédent | Suivant
