3. L’estimation de la fonction de densité des revenus
Eric Graf et Yves Tillé
Précédent | Suivant
Dans une approche basée sur le plan (design based) en population
finie, l’inférence se fait par rapport au plan de sondage
utilisé pour
sélectionner l’échantillon
dans la population
de taille finie
. Dans cette approche, seules les indicatrices d’inclusion
dans l’échantillon sont aléatoires, toutes les autres grandeurs sont fixes. La
fonction de répartition des revenus au niveau de la population est alors une
fonction en escaliers : et sa dérivée, la
fonction de densité, n’existe pas à cause des discontinuités. Si l’on ne veut
pas se placer dans une approche basée sur le modèle (model based) avec
un modèle de super population pour justifier le terme de fonction de densité
des revenus, il faut artificiellement lisser la fonction de répartition pour
qu’elle devienne dérivable. C’est donc par abus de langage que nous nous
autorisons ici à parler de fonction de densité. Avec cette volonté de lissage,
Deville (2000) et Osier (2009) proposent d’estimer la fonction de densité des
revenus par noyau gaussien :
où
est la largeur de la bande qu’Osier
estime par
et
est l’écart-type estimé de la
distribution empirique des revenus :
Notons que
cette estimation de
n’est pas robuste étant très
sensible aux valeurs extrêmes de
Des données de revenus ont très
souvent une queue de distribution étendue vers la droite avec des valeurs très
élevées possibles, on parle de valeurs aberrantes représentatives (representative
outliers) au sens de Chambers (1986) et Hulliger (1999). Comme le montrent
nos simulations dans la section 4, cela peut fortement biaiser nos estimations
de variance. Verma et Betti (2011) procèdent également par noyau rappelant que,
selon Silverman (1986), le choix du noyau n’est pas crucial pour assurer la
convergence de
vers
alors que celui de la largeur de
bande l’est. Ils utilisent une valeur conseillée par Silverman dans le cas de
distributions avec un coefficient d’asymétrie positif,
Dans leurs conclusions, ils
relèvent que la méthode par linéarisation peut être problématique en raison
d’irrégularités de la fonction de densité empirique. On ajoutera que ces
problèmes sont d’autant plus préoccupants qu’il est fréquent, dans les données
issues d’enquêtes, d’avoir des agglomérats d’observations à certaines valeurs
(dues à des arrondis ou des questions-fourchettes), ce qui peut compliquer
l’estimation de la densité. La suite de l’article décrit des solutions que nous
avançons pour réduire le biais de la variance estimée.
3.1 Passer par le logarithme
Une solution qui, comme on le verra plus loin, donne de très bons
résultats est de simplement passer par le logarithme pour estimer la densité en
Si l’on pose
où
est le revenu et
un nombre réel
positif par exemple égal à
dans le cas où l’on
aurait des revenus négatifs ou nuls (en négligeant le fait que
serait estimé), on
a que
où
et
seraient de variables aléatoires.
Donc,
Autrement
dit
ce qui nous donne l’estimateur
suivant de la densité en
L’estimation de la densité en
de
peut donc s’évaluer
en estimant celle du logarithme de la variable, divisée par la valeur de la
variable au point qui nous intéresse. La propriété reste valable en population
finie. Le fait de passer par le logarithme a l’avantage de diminuer l’effet
levier exercé par les grandes valeurs des revenus dans le calcul de
l’approximation de la densité par noyau. Les simulations montrent que cette
méthode très simple réduit fortement le biais.
3.2 Plus
proches voisins avec largeur de bande minimale
Deville (2000) esquisse une autre manière du type « plus proches
voisins » (voir Silverman 1986) d’estimer la densité en utilisant le noyau
avec
et où le choix de
et
vérifiant
reste à déterminer et pourrait
dépendre de
La distance
représente la largeur de bande
L’estimation de la densité vaudrait
alors
avec
Notons que l’estimation de la densité (3.3) n’est pas une fonction
continue et qu’elle ne serait pas très adaptée pour estimer des valeurs de
densité à l’extrémité des queues de la distribution. Puisque nos travaux ne
reposent pas trop sur les queues de la distribution, nous considérons cette
approche comme une option.
Notre deuxième proposition d’estimation de la densité en
s’inspire de l’idée
ci-dessus. Elle est du type « plus proches voisins », mais impose
aussi une largeur de bande minimale : notre méthode impose d’utiliser au
minimum les
plus proches
observations du point
tout en imposant
une largeur de bande minimale
où
est la règle
empirique (rule of thumb) de Silverman (1986) pour déterminer la largeur
de la bande. Cette valeur est aussi utilisée par défaut par la fonction R density pour la largeur de la bande si rien n’est
spécifié. Cette solution est plus robuste que (3.1) et évite les problèmes que
l’on rencontre lorsque plusieurs valeurs
sont très proches les unes des
autres, ce qui arrive fréquemment parce que les personnes interrogées ont
tendance à arrondir leur revenu.
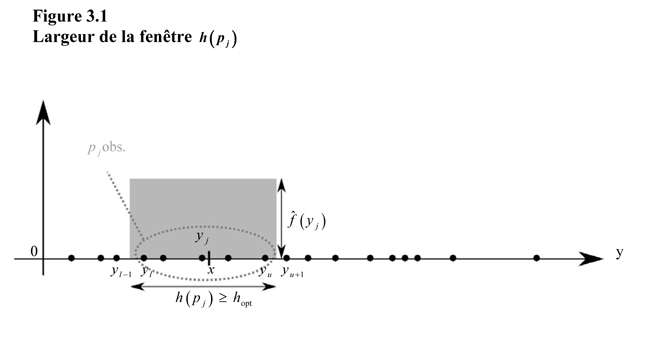
Les valeurs
étant supposées
ordonnées par leur rang, la largeur
de la fenêtre
autour de
est initialement
déterminée par les
plus proches
observations, avec
Pour les
simulations exposées dans la section suivante, après différents essais, le
initial a été fixé
à 30. On impute comme densité en
la densité estimée
au point observé
le plus proche
inférieur ou égal à
c’est-à-dire
La largeur de la
bande en
dépendra en fait
des
plus proches
observations autour de
avec
On la
désignera par
dans la suite pour
le rappeler. La densité n’est donc estimée qu’en des points observés sans qu’un
lissage ou une interpolation soient menés entre les
L’algorithme pour
estimer
est le suivant
(voir aussi Figure 3.1) :
1. La
largeur initiale de la fenêtre autour du point
avec
est définie par :
2. Si
la largeur de fenêtre
ainsi obtenue est inférieure à
, on incrémente les deux
bornes :
borne
supérieure :
tant que
borne
inférieure :
tant que
ce qui
implique
nbsp;sauf si
ou
on n’a alors plus le même nombre de points à
gauche et à droite de
3. Répéter 2 jusqu’à ce que
4. La
densité estimée en
est alors donnée par
avec les
poids standardisés
Le nombre
d’observations
prises en compte pour le calcul
peut varier et dépend de la courbure locale de la fonction de répartition
empirique. La condition
garantit une largeur de fenêtre
minimale aux endroits où beaucoup d’observations seraient concentrées sur un
petit intervalle. On rend la procédure encore plus solide en combinant cette
approche avec la précédente, c’est-à-dire en estimant la densité du logarithme
de la variable divisée par sa valeur (non logarithmisée) :
3.3 Robustesse de la linéarisée
Comme mentionné plus haut, dans le cas de la médiane ou pour les autres
quantiles, Croux (1998) relève que la fonction d’influence empirique ou
linéarisée estimée à partir de l’échantillon n’est pas aussi robuste qu’il n’y
paraît, même si l’on connaît la fonction de densité. Nous avons vérifié cela
pour les données SILC utilisées dans les simulations modélisées avec une loi
Bêta Généralisée de seconde espèce (GB2) grâce à la fonction profml.gb2 de R (Graf et Nedyalkova
2011). Sur de petits échantillons
le biais potentiel
de la linéarisée engendré par un trop grand nombre de valeurs extrêmes peut
aussi biaiser l’estimation de la variance calculée à partir de cette dernière.
Pour de plus grands échantillons
un biais relatif
maximal dans la variance estimée à l’aide de la linéarisée empirique vs. théorique peut atteindre jusqu’à
5 %. Il est cependant en-dessous du pourcent en valeur absolue dans les
trois quarts des cas.
Précédent | Suivant
