
Rapports sur les projets spéciaux sur les entreprises
Mesure de la proximité des services et commodités : ensemble expérimental d'indicateurs pour les quartiers et les localités
par Alessandro Alasia, Nick Newstead, Joseph Kuchar et Marian Radulescu
Remerciements
Ce projet a été lancé et financé par la Société canadienne d’hypothèques et de logement (SCHL). Nous remercions vivement cette organisation et son personnel pour leur soutien. En particulier, Jean-Philippe Deschamps-Laporte (au cours des premières années du projet), Stephanie L. Shewchuk et George A. Ngoundjou Nkwinkeum ont continuellement offert des conseils et de précieux commentaires concernant la mise en œuvre du projet. À Statistique Canada, plusieurs autres personnes ont contribué à l’achèvement de ce travail; Jean Le Moullec a géré la première phase du projet et a fourni des données essentielles à traiter. Marina Smailes a contribué aux efforts de recherche. L’équipe de l’innovation numérique de Statistique Canada (et tout particulièrement Marc-Philippe St. Amour et Jean-Philippe Tissot), ainsi que l’équipe responsable du projet d’infonuagique (dont Francis Mailhot) ont joué un rôle déterminant pour faciliter l’accès aux outils de TI nécessaires à l’analyse.
Sommaire
Dans un monde hautement connecté et réseauté, l’importance que revêt le concept de géographie a incontestablement changé. Cependant, le rôle que joue l’espace (tel que mesuré par la proximité physique) dans les résultats économiques et sociaux est tout aussi important qu’auparavant. La proximité spatiale des services et commodités demeure un élément moteur des résultats socioéconomiques, aussi bien pour les entreprises que pour les individus. Par ailleurs, la pandémie de COVID-19 a mis en relief l’importance des données de cette nature, non seulement pour la gestion de crise et l’intervention d’urgence, mais aussi pour l’ensemble de la population.
Pour rendre compte de l’effet de la proximité des services et commodités, les responsables de l’élaboration des politiques à l’échelle nationale et locale ont besoin de mesures qui sont aussi détaillées que possible et comparables d’un secteur de compétence à l’autre. Au Canada, un cadre de mesure de la proximité, à l’appui des politiques et de la planification, faisait défaut. Pour combler cette lacune et soutenir le pilier de l’inclusion sociale de la Stratégie nationale sur le logement, Statistique Canada a collaboré avec la Société canadienne d’hypothèques et de logement (SCHL) à la création d’un ensemble de mesures de proximité. Le résultat de cette collaboration est la publication de la Base de données des mesures de proximité (BDMP), la première base de données nationale de la sorte, qui est maintenant accessible au public.
Le présent article décrit la méthodologie qui a utilisée pour générer la première mouture de cette base de données, qui contient les résultats obtenus à partir d’un premier ensemble de dix mesures. Les méthodes de calcul sont présentées sous forme de modèle généralisable, car il est maintenant possible d’appliquer des méthodes similaires à une multitude d’autres services et commodités, avec diverses autres spécifications.
En raison de l’échelle du projet, le calcul des mesures a exigé un certain nombre de solutions novatrices. Plus précisément, les méthodes de calcul reposent en grande partie sur des logiciels libres et ont été mises en œuvre dans un environnement infonuagique, et certaines des mesures sont entièrement fondées sur de nouvelles bases de données ouvertes et accessibles au public.
À l’heure actuelle, la BDMP contient des mesures de proximité pour 10 types de services et commodités : les emplois, les épiceries, les pharmacies, les établissements de soins de santé, les services de garde d’enfants, les établissements d’enseignement primaire, les établissements d’enseignement secondaire, le transport en commun, les parcs de quartier et les bibliothèques. De plus, un indicateur composite qui combine certaines mesures a été mis au point pour évaluer l’accessiblité générale des services et commodités.
Toutes les mesures sont au niveau de l’îlot de diffusion (ID), lequel correspond à un îlot urbain ou à une zone délimitée par des routes ou des éléments naturels en milieu rural. Le pays entier est subdivisé en environ un demi-million d’ID. Il s’agit de la plus petite unité géographique normalisée qu’utilise Statistique Canada et, par conséquent, elle offre la plus haute résolution géographique qu’il est actuellement possible d’obtenir. La couverture de certaines mesures qui figurent dans la base de données varie selon la disponibilité de sources sûres de données ouvertes. Cependant, le nombre de sources sûres s’accroît depuis quelques années, et si la tendance se maintient, les prochaines versions des mesures de proximité bénéficieront d’une couverture plus complète.
Les mesures de proximité sont fondées sur un modèle gravitationnel simple qui tient compte des distances entre un ID de référence et tous les ID qui se situent dans un rayon donné et où le service en question est offert. Les mesures de proximité tiennent également compte de la taille des services ainsi que de leur présence dans l’ID de référence.
Toutes les mesures, à l’exception de celles qui concernent le transport en commun, sont fondées sur les distances qui séparent les centroïdes des ID dans le réseau piétonnier ou routier (par opposition aux distances en ligne droite). En ce qui concerne le transport en commun, une distance dans le réseau piétonnier est définie comme la distance à parcourir à pied à partir du centre d’un ID pour atteindre un arrêt de transport en commun situé dans un rayon donné autour de cet îlot. La taille d’un service est déterminée par son nombre total d’employés ou son revenu total ou, plus simplement, par la présence de points d’accès au service dans un rayon donné autour de l’ID considéré. La mesure de la taille d’un service est propre à chaque mesure.
Les mesures de proximité sont présentées sous forme de valeurs indices normalisées, ce qui signifie que les valeurs découlant des calculs ont été ramenées à une échelle de 0 à 1, où 0 correspond à la plus faible proximité, et 1 à la plus élevée au Canada. Cette normalisation à l’échelle nationale a été effectuée pour conserver un meilleur niveau de détail possible.
En utilisant les spécifications (types de service, distances et facteurs de pondération) requises par la SCHL, les principaux résultats agrégés peuvent être résumés comme suit.
- Environ 20 % des Canadiens vivent dans un quartier à « forte densité de services et commodités », c’est-à-dire qu’il répondent aux critères suivants : accès à au moins une épicerie, une pharmacie et un arrêt de transport en commun à 1 km de marche; accès à un service de garde d’enfants, un établissement d’enseignement primaire et une bibliothèque à 1,5 km de marche; accès à un établissement de soins de santé à 3 km de route; et accès à des emplois à 10 km de route.
- Près de la moitié des Canadiens vivent dans une localité ou un quartier situé à 1 km de marche d’une épicerie. Dans les grandes régions métropolitaines, c’est le cas pour 55 %. Ce pourcentage passe à 30 % pour les résidents de petites régions métropolitaines et à 16 % pour la population rurale.
- Près de 60 % des Canadiens vivent dans une localité ou un quartier situé à 1 km de marche d’une pharmacie. Environ 88 % des Canadiens vivent dans une localité ou un quartier situé à 3 km de route d’un établissement de soins de santé. Le pourcentage est de 97 % pour les résidents des grandes régions métropolitaines, de 87 % pour ceux des petites régions métropolitaines et d’environ 50 % pour ceux des régions rurales.
- Environ 70 % des Canadiens vivent dans une localité ou un quartier situé à 1,5 km de marche d’une école primaire, et le pourcentage est similaire pour la distance à un service de garde d’enfants. Le pourcentage est moins élevé pour l’accès à une école secondaire : environ 42 % des Canadiens vivent à 1,5 km de marche d’une école secondaire. Le pourcentage est de 49 % pour ceux qui vivent dans les grandes régions métropolitaines, de 38 % pour ceux qui vivent dans les petites régions métropolitaines et de 20 % pour ceux qui vivent dans les régions rurales.
- Les services de transport en commun sont représentatifs des régions métropolitaines. Dans les grandes régions métropolitaines du Canada, près de 90 % de la population vit à 1 km de marche d’un arrêt de transport en commun. La Colombie-Britannique, le Québec et l’Alberta affichent le pourcentage le plus élevé de population métropolitaine vivant à proximité (1 km de marche) d’un arrêt de transport en commun. La Colombie-Britannique est la seule province où une forte proportion des résidents des petites régions métropolitaines (environ 70 %) et des résidents des régions rurales (près de 20 %) vivent à 1 km de marche d’un arrêt de transport en commun.
- Environ 75 % des Canadiens vivent dans une localité ou un quartier situé à 1 km de marche de parcs de quartier. En général, ce pourcentage est plus élevé dans les grandes régions métropolitaines, mais on observe des différences significatives entre les provinces. Par exemple, à Terre-Neuve-et-Labrador et au Nouveau-Brunswick, 50 % ou moins des résidents de régions métropolitaines vivent à proximité d’un parc. En revanche, une proportion relativement importante de résidents ruraux du Québec et de la Colombie-Britannique (environ 20 % ou un peu plus) vit à proximité de parcs de quartier.
- Environ 30 % des Canadiens vivent à 1,5 km de marche d’une bibliothèque. Le pourcentage est relativement semblable d’une région à l’autre, se situant à 33 % dans les grandes régions métropolitaines et à 22 % dans les régions rurales.
Bien que ces chiffres agrégés fournissent de précieux renseignements, le véritable intérêt du travail présenté dans cet article réside dans la disponibilité et la visibilité de ces mesures au niveau de l’îlot de diffusion pour l’ensemble du Canada. Le Visualiseur de données sur les mesures de proximité mis au point pour cette analyse donne facilement accès à des données géographiques au niveau de détail souhaité pour montrer les mesures correspondantes : Visualiseur de données sur les mesures de proximité
Le cadre méthodologique et de données élaboré pour cette analyse, qui comprend une base de données de 2,6 milliards de distances point à point, peut maintenant être adapté pour le calcul de diverses autres spécifications pour les mêmes mesures, ou pour le calcul de nouvelles mesures de proximité relatives à d’autres services ou commodités, dans le but de répondre à un éventail de besoins stratégiques et de planification.
Introduction
De récentes publications ont souligné la pertinence continue de la proximité et de l’emplacement physiques dans une économie de plus en plus numérique, souvent perçue comme hors de l’espace (OCDE, 2019). Même dans un monde qui évolue rapidement vers les technologies numériques, des données probantes ont montré que la proximité physique entre les entités, les acteurs sociaux et économiques, ou les consommateurs et les fournisseurs de services demeure un catalyseur pertinent des résultats socioéconomiques.
La proximité physique des services et commodités joue un rôle déterminant dans la performance économique des entreprises, dans la qualité de vie de la population, et dans les décisions que prennent les personnes et les entreprises en matière d’emplacement. Pour les particuliers, l’accès physique aux services et aux commodités de base joue un rôle déterminant dans leur inclusion sociale, dans la satisfaction de leurs besoins fondamentaux, et dans leur pleine participation au développement social et économique de leur localité. Et pour les villes, un certain nombre de services et de commodités doivent être offerts pour assurer l’atteinte d’une viabilité sociale et économique à l’échelle locale.
Pour établir un cadre de mesure de la proximité des services et commodités, Statistique Canada s’est associé avec la Société canadienne d’hypothèques et de logement (SCHL). Celle-ci est chargée de la mise en œuvre de la Stratégie nationale sur le logement, laquelle devrait donner lieu à d’importants investissements, au cours des 10 prochaines années, dans l’amélioration de la qualité du logement et des quartiers au paysNote . La proximité physique des services et commodités est considérée comme un élément clé d’une notion plus large de l’accessibilité qui, à son tour, est un pilier de l’inclusion sociale. Ces concepts sont de plus en plus intégrés dans la planification municipale et l’aménagement urbain. Au Canada et dans le monde entier, les municipalités commencent à faire explicitement référence au concept de « quartier 15 minutes » dans leurs plans d’aménagement. Dans un tel quartier, les services essentiels ou ceux auxquels on se rend quotidiennement sont à 15 minutes du domicileNote .
La collaboration entre Statistique Canada et la SCHL a mené à la diffusion de la première Base de données des mesures de proximité (BDMP) nationale. Cette base de données ainsi qu’un outil de visualisation qui montre la répartition géographique des mesures de proximité ont fait l’objet d’une diffusion anticipée en réponse aux besoins urgents de données pour faire face à la crise de COVID-19.
Cet article décrit en détail les méthodes utilisées pour élaborer la BDMP. L’approche utilisée à cette fin comblait une lacune de mesure existante en fournissant des mesures de proximité au niveau de la localité ou du quartier, en utilisant le niveau de détail géographique le plus élevé possible et en maintenant la comparabilité à l’échelle du Canada.
Plus important encore, les méthodes utilisées pour établir la BDMP sont fondées sur un modèle généralisable qui a un potentiel considérable en matière d’extensions et d’adaptations, ainsi que d’applications à plusieurs autres services ou commodités. C’est pourquoi le présent article met l’accent sur les aspects méthodologiques plutôt que sur l’analyse des mesures de proximité générées dans cette première mouture de la BDMP. Un des objectifs de cet article consiste à susciter des commentaires des parties concernées, en vue d’apporter de nouvelles améliorations méthodologiques aux processus de calcul des mesures et d’actualiser les mesures lorsque de nouvelles sources de données seront disponibles.
Ce rapport est divisé en six sections. Dans l’introduction, la lacune dans les mesures est décrite, ainsi que le défi en matière d’innovation qu’il a fallu relever pour la combler. La deuxième section présente un modèle de calcul général, q modèle conceptuel fondamental qui sous-tend toutes les mesures présentées dans cet article. La troisième section décrit les sources de données utilisées, et met en relief les avantages que présente l’intégration des données ouvertes aux sources statistiques officielles. La quatrième section décrit en détail les méthodes de mise en œuvre, alors que la cinquième section traite des spécifications des dix mesures de proximité. La sixième section présente le premier ensemble de mesures de proximité calculé pour la SCHL. Enfin, l’article se termine par des considérations plus poussées en matière d’études.
Comprendre les lacunes en matière de mesures
De nombreuses publications de sciences sociales prouvent que le degré de proximité physique détermine des résultats et des comportements socioéconomiques. Des études dans le domaine économique (Melo et coll., 2017) ont montré que les externalités des agglomérations — les avantages en matière de réduction des coûts et d’amélioration de l’efficacité qui découlent de la proximité des agents économiques — se manifestent principalement dans un court rayon et demeurent petites à de plus grandes distances. Des analyses de marketing suggèrent que l’importance de la proximité géographique augmente avec le nombre services de marketing qui utilisent les emplacements géographiques des consommateurs (Becker et coll., 2017). Dans le même ordre d’idées, des études comportementales ont montré que, malgré l’utilisation et les incidences croissantes des médias sociaux, la proximité des individus demeure un facteur déterminant de la probabilité de nouer des amitiés (Nguyen et Szymanski, 2012).
Pour ces raisons, il est peu surprenant que la recherche méthodologique concernant les mesures de proximité ait prospéré, et ce, dans différentes disciplines et sous différentes désignations, dont les mesures de proximité, d’accessibilité et d’éloignement (OCDE, 2013, 2018)Note . Alasia et coll. (2017) ont fait un survol de la recherche à ce jour, notamment du point de vue de l’éloignement et de l’accessibilité, et une analyse documentaire a été entreprise en vue de cette étude.
Ces revues de la littérature ont permis de relever deux choses : d’une part, la diversité des approches conceptuelles et méthodologiques sans définition unique ou majoritairement acceptée, et d’autre part, les défis opérationnels qui empêchaient l’élaboration d’un cadre de mesure complet. En effet, la création d’un cadre exhaustif de mesure de la proximité était limitée par la couverture des données ou la disponibilité d’une capacité de calcul suffisante pour effectuer une analyse de réseau relativement complexe.
L’insuffisance de données associées aux emplacements précis des services et commodités, la couverture incomplète et la difficulté d’obtenir les données requises pour déterminer les emplacements des activités économiques ont été déplorées dans certaines études (Head et Mayer, 2004; Duranton et Kerr, 2015). De même, la capacité de calcul requise pour traiter des analyses de réseau même relativement simples, lorsque les liaisons de réseau se comptent par milliards, représentait jusqu’à récemment un défi opérationnel majeur.
Les conséquences de ces limitations ont été triples. Tout d’abord, des mesures de proximité ou d’accessibilité ont été établies pour un certain nombre de régions géographiques, comme des régions métropolitaines particulières (voir Apparicio et Séguin, 2006). Ensuite, les mesures qui ont été élaborées pour assurer une vaste couverture nationale ont été fondées sur des unités territoriales relativement grandes, comme des régions ou grandes régions métropolitaines, ce qui a entraîné une importante perte de détail géographique (voir OCDE, 2013). Enfin, les chercheurs qui ont essayé d’assurer une vaste couverture et un niveau élevé de détail géographique ont souvent dû faire des compromis méthodologiques. En particulier, ils ont utilisé des approximations moins exigeantes sur le plan des calculs pour déterminer les distances aux services, comme des mesures de distance « à vol d’oiseau » à un seul point de prestation de services (voir OCDE, 2013). L’augmentation de la capacité de calcul, combinée à l’amélioration du géocodage des statistiques officielles et à l’existence de nouvelles sources de microdonnées géocodées, rend maintenant possible ce type d’analyse.
Les éléments novateurs qui nous ont permis de progresser
Dans le contexte décrit dans la section précédente, trois éléments novateurs ont rendu la présente analyse possible dans le respect d’échéanciers et de budgets réalistes : l’augmentation de la capacité de calcul par utilisation de l’infonuagique, l’amélioration du géocodage des statistiques officielles, de nouvelles sources de microdonnées géocodées et une utilisation intensive de logiciels libres et d’outils analytiques.
La puissance de traitement requise pour générer les mesures de proximité au niveau du quartier correspondant à l’ensemble du Canada, c’est-à-dire plus d’un milliard de distances réseau, était impossible à obtenir il y a quelques années à peine. Grâce à l’infonuagique, il a été possible d’atteindre la capacité et la vitesse de traitement requises pour travailler à l’échelle réelle et obtenir un niveau de détail géographique inaccessible dans le passé.
Le projet a également bénéficié d’améliorations dans le géocodage des statistiques officielles, mais, plus important encore, plusieurs des mesures élaborées et décrites dans la présente ont pu être calculées au moyen de nouvelles sources de données, en particulier des microdonnées ouvertes sur l’emplacement des services et commodités. Partout au Canada, les autorités municipales et provinciales fournissent des volumes importants de données de ce type.
Enfin, les logiciels et les outils libres étaient un autre élément clé qui a rendu ce projet possible. Tout le code de traitement a été écrit en Python, tandis que l’analyse spatiale a été réalisée avec QGIS. Cette approche visait à éliminer les obstacles à la transférabilité du code ainsi qu’à la reproductibilité, aux extensions ou aux améliorations possibles. De plus, l’utilisation de solutions infonuagiques de navigation à code source libre s’est avérée l’approche la plus efficace, compte tenu de la portée du projet.
Un modèle général
Dans sa formulation la plus élémentaire, une mesure de la proximité physique est la distance entre un point d’origine (emplacement d’une personne ou d’une entreprise) et un point de destination (p. ex. emplacement d’un service ou d’une commodité). Cette idée abstraite peut ensuite être adaptée aux types de problèmes que la mesure de proximité vise à résoudre.
Aux fins de cette analyse, un ensemble de principes directeurs a été utilisé pour élaborer le modèle de calcul. Ces principes sont présentés ci-dessous. Ils sont suivis des particularités générales du modèle de calcul.
Principes directeurs pour l’élaboration des mesures
En l’absence d’une spécification méthodologique unique et largement acceptée de la proximité, il est important de rendre explicites les principes directeurs qui ont été utilisés pour élaborer les mesures. Dans une large mesure, ces principes ont été calculés à partir de ceux qui ont été utilisés précédemment pour l’élaboration d’un indice d’éloignement précédent (Alasia et coll., 2017).
Premièrement, les mesures de proximité devaient couvrir l’ensemble du Canada, et offrir la meilleure résolution géographique possible. C’est ce qui a mené à l’utilisation de l’îlot de diffusion (ID) comme unité géographique d’analyse. Deuxièmement, les mesures ont été élaborées comme des mesures continues, plutôt que comme des mesures catégoriques; cela se reflète dans la spécification mathématique du modèle. Troisièmement, les mesures étaient essentiellement fondées sur la proximité physique, et non sur d’autres dimensions qui rendraient compte de barrières ou de distances économiques, sociales ou culturelles, et cela doit être reconnu dès le départ comme une caractéristique clé de ces mesures.
En s’appuyant sur l’expérience de l’indice d’éloignement, les mesures de proximité présentées dans le présent article visent à représenter à la fois la proximité de multiples points de prestation de services ainsi que la taille des services à ces points. Cette approche contraste avec des méthodes plus simplistes qui tiennent compte de la proximité d’un point de service unique (p. ex. le point d’accès le plus proche); ne pas tenir compte de la taille de nombreux services revient à ignorer l’importance de l’agglomération où ils se trouvent et la diversité des options offertes aux utilisateurs.
En même temps, il s’agissait de maintenir des spécifications relativement simples des mesures. Sur la base de l’expérience acquise avec des indices d’éloignement précédents, cette décision était justifiée parce que des calculs trop complexes peuvent avoir des incidences sur la facilité future de maintenance des mesures et surtout sur l’aptitude des utilisateurs à les interpréter. Pour préserver la transparence des calculs, on a évité les approches qui exigent la combinaison de mesures qualitativement différentes (p. ex. de différents types de services) pour obtenir un indicateur indépendant en faisant appel au jugement d’un expert ainsi que les systèmes de pondération ou des méthodes statistiques plus complexes comme les techniques de réduction des données ou d’analyse multidimensionnelle. Par conséquent, des mesures de proximité ont été élaborées pour chaque type de service et d commodité.
Enfin, on a tenu compte de la facilité et du coût des activités de maintenance et des mises à jour futures. Il s’agissait de générer un extrant qu’un processus relativement simple d’actualisation des jeux de données clés et de réexécution des programmes informatiques permettrait de mettre à jour. Plus précisément, un tel processus devait être fondé sur des données d’entrée régulièrement mises à jour et facilement accessibles à des coûts relativement faibles, ainsi que sur des programmes informatiques entièrement documentés.
Modèle de calcul
Une approche fondée sur un modèle gravitationnel est le point de départ méthodologique du calcul des mesures de proximité. Dans sa forme la plus simple, le modèle gravitationnel tient compte de deux grandeurs : la masse et la distance. La masse peut être interprétée comme la « taille » du service ou de la commodité qui se trouve à l’emplacement. Par exemple, un grand hôpital offre probablement un plus grand nombre de services médicaux qu’une petite clinique. Par conséquent, une mesure idéale de la masse devrait tenir compte de la variété et du nombre des services offerts. D’autre part, la distance est une mesure de l’écart entre les points d’origine et de destination. À mesure que la distance entre le point A et le point B augmente, l’accès qu’à le point A aux services offerts au point B diminue.
Le niveau de service auquel on a accès à un point d’origine en raison d’un point de destination est proportionnel à la taille du service (Masse) à et inversement proportionnel à la distance (Dist) entre et . Le niveau de proximité du point d’origine est la somme des niveaux de service auquel on a accès au point à cause de la présence de toutes les destinations de l’ensemble dans un rayon spécifié .
En termes mathématiques, l’équation (1) illustre la formule et les conditions qui définissent le niveau de proximité d’une unité géographique :
où
si
La condition garantit que le dénominateur sera toujours un nombre réel positif. La valeur assure qu’il y a au moins une certaine distance de déplacement pour accéder à un service situé dans les limites de l’îlot de diffusion (ID) d’origine. La valeur garantit que l’ID ne sera pas séparé de l’ID d’une distance inférieure au rayon de l’ID . La valeur 100 garantit que la distance « minimale » n’est pas trop petite. Plusieurs ID sont très petits, ce qui leur donne un poids extrême dans le calcul des mesures de proximité.
Le niveau de proximité correspondant à l’unité géographique peut être interprété comme la somme des tailles des instances du service (exprimés dans l’unité de mesure de ) sur les distances (exprimés dans l’unité de mesure de ) à parcourir pour atteindre chaque instance (endroit où la prestation du service est assurée ), le rayon de déplacement maximal étant . Par exemple, si la taille d’une épicerie est représentée par les revenus totaux que cette épicerie génère et que de multiples épiceries se trouvent à l’intérieur de la zone considérée, on peut métaphoriquement interpréter comme la somme des rapports entre les revenus de chaque épicerie et la distance à parcourir pour s’y rendre. Plus cette valeur est élevée, et plus la proximité du service d’épicerie est grande.
Dans le modèle général décrit dans ce document, il est possible de distinguer deux formes d’une même mesure de proximité. La première forme est une mesure exprimée en termes absolus (unités de masse par unité de distance) comme le niveau de proximité ( ) décrit ci-dessus. La deuxième forme est la mesure exprimée sous forme de valeur indice normalisée. Voici une explication de la spécification mathématique et de l’interprétation de l’indice de proximité ( ).
Dans le cadre de cette analyse, toutes les mesures de proximité sont présentées en termes relatifs, comme indices rééchelonnés. C’est-à-dire que chaque valeur de niveau de proximité NP est transformée en une valeur d’indice de proximité IP, en rééchelonnant ses valeurs dans un intervalle compris entre 0 et 1. Pour ce faire, la formule de rééchelonnage standard suivante est appliquée :
Cette transformation présente des avantages et des inconvénients. Son principal avantage réside dans le fait que les indices sont généralement plus faciles à interpréter. Tout d’abord, cela facilite la compréhension de la position relative d’un ID par rapport à d’autres. Cela permet également des comparaisons plus intuitives entre les mesures en éliminant les unités qui peuvent dépendre du type de service ou de commodité. L’inconvénient de cette approche est que la comparaison de l’indice au fil du temps devient moins pertinente, car le minimum et le maximum peuvent varier au cours de chaque période.
Ce modèle général a trois caractéristiques souhaitables. Premièrement, il traduit l’idée fondamentale que plus le point de service est proche, plus l’interaction potentielle est forte, ce qui devrait se refléter dans la mesure de proximité. Deuxièmement, il tient compte de la possibilité de multiples points d’accès à un service donné. Troisièmement, il permet de mesurer la taille du service en tenant compte du fait que, par exemple, la proximité d’un arrêt d’autobus par lequel passe un autobus d’une ligne une fois par heure ne correspond pas au même niveau de service que la proximité d’un arrêt d’autobus par lequel passent les autobus de dix lignes à intervalles de 15 minutes.
L’application de ce modèle général à des mesures de proximité particulières a exigé des rectifications et des modifications qui ont été dictées par le type de services ou de commodités ainsi que par la nature des données utilisées dans le calcul. Ces adaptations sont décrites à la section 3.
Sources des données
Deux principaux types de données ont servi à la production des mesures de proximité : des statistiques officielles, provenant des fonds de données de Statistique Canada, et des données ouvertes ou publiques provenant d’autorités provinciales et municipales et de plateformes en ligne. Les deux types de données ont fait l’objet d’un processus rigoureux de nettoyage, de validation, de révision ou d’amélioration du géocodage avant leur utilisation dans le calcul des mesures de proximité.
Pour ce qui est des données de Statistique Canada, la principale source utilisée est le Registre des entreprises (RE), une base de données centrale des entreprises et des institutions actives au Canada, qui est continuellement mise à jour. Pour ce projet, les données de 2017 à 2019 du RE ont été utilisées. Bien que les données sur l’emploi et les variables que contient le RE ne soient pas aussi précises et actuelles que celles qui proviennent de programmes particuliers d’enquêtes sur la population active, le RE a le grand avantage d’offrir une couverture nationale exhaustive. Peu d’autres sources de données sur les entreprises offrent cet avantage.
Néanmoins, l’utilisation des données du RE pour calculer les mesures de proximité pose un certain nombre de défis. Malgré l’amélioration considérable de la géolocalisation de ses données, certains enregistrements du RE ne sont géocodés qu’au niveau de la municipalité, par conséquent, d’importants ajustements doivent être effectués pour générer des mesures au niveau du quartier. Les entreprises complexes présentent un autre problème, car leurs indicateurs d’emploi et financiers sont fondés sur les activités à l’échelle de l’entreprise. Autrement dit, les renseignements pour l’ensemble de l’entreprise sont agrégés à l’échelle du siège social, et ne sont pas accessibles pour les emplacements d’exploitation. À bien des égards, une telle caractéristique ne pose pas de problème. En ce qui concerne le calcul des mesures de proximité au niveau de la localité (et la plupart des indicateurs à ce niveau), les déclarations de niveau de l’entreprise peuvent surestimer la masse (p. ex. les revenus ou l’emploi) dans les régions où se trouvent des sièges sociaux et la sous-estimer dans des régions où se déroulent des activités d’exploitation qui devraient être prises en compte dans le calcul. Pour les mesures de proximité touchées par ces problèmes, la méthode utilisée pour redistribuer, au niveau de l’emplacement, les revenus ou les chiffres de l’emploi déclarés au niveau de l’entreprise est décrite à la section 4.
Le deuxième grand type de données provient des bases de données publiques et des bases de données qui font l’objet d’une licence ouverte. Le calcul des mesures de proximité a été rendu possible grâce à une autre initiative de Statistique Canada, l’Environnement de couplage de données ouvertes (ECDO). Cette initiative exploratoire vise à améliorer l’utilisation et l’harmonisation des microdonnées ouvertes provenant principalement de sources municipales, provinciales et fédéralesNote .
L’utilisation de données ouvertes et publiques était nécessaire pour obtenir certaines des mesures de proximité. Par exemple, des données géographiques complètes sur les établissements d’enseignement n’étaient pas disponibles dans le Registre des entreprises ou d’autres fonds de données de Statistique Canada avant l’élaboration de la Base de données ouvertes sur les établissements d’enseignement (BDOEE)Note . De même, les renseignements géographiques concernant les bibliothèques publiques, les parcs de quartier ou les points d’accès au transport en commun ne figurent pas dans les statistiques officielles ou les fonds de données. Les données correspondantes ont été recueillies au moyen de portails de données ouvertes et de pages Web publiques, puis comparées avec celles tirées de multiples sources. Des efforts ont été déployés pour établir un jeu de données aussi complet que possible. Cependant, il est important de reconnaître que des problèmes de couverture demeurent associés à chaque type de données. Ils sont examinés plus en détail dans le cadre de la spécification de chaque mesure.
De plus, comme la plupart des données ouvertes et publiques ne sont pas aussi complètes que celles qui figurent dans le RE, les données recueillies se limitent généralement aux noms des installations et aux données de géolocalisation correspondantes. Les établissements d’enseignement constituent une exception. Ils sont catégorisés en types primaires et/ou secondaires au moyen de Classification internationale type de l’éducation (CITE). Les données sur le transport en commun, qui respectent la General Transit Feed Specification (GTFS), en constituent une autre. Les données GTFS comprennent les emplacements des arrêts ainsi que des renseignements détaillés sur les horaires.
Finalement, les distances entre les points d’origine et de destination ont été calculées au moyen du réseau routier utilisé par OpenStreetMap (OSM) et d’OpenRouteService (ORS), un logiciel de navigation ouvert. D’autres logiciels ont été envisagés pour le calcul des distances dans le réseau routier. Cependant, cette approche a été considérée comme peu pratique pour des raisons de coût ou de temps d’exécution. À cause du nombre considérable de calculs de distance requis, ces calculs ont été effectués dans un environnement infonuagique et la combinaison d’OSM et d’ORS s’est révélée la meilleure solution. Une description détaillée de la mise en œuvre technique et des méthodes de calcul est présentée dans la section suivante.
Méthodes de mise en œuvre
Cette section décrit les aspects techniques des méthodes de calcul. L’accent est mis sur les aspects généraux de la méthodologie, mais il sera inévitablement question aussi des mesures spécifiques mises au point pour cette analyse. Elle commence par une discussion de l’unité géographique d’analyse et des méthodes utilisées pour établir la base de données des distances réseau.
Unité géographique d’analyse
Toutes les mesures de proximité présentées sont calculées au niveau de l’îlot de diffusion (ID). Cela signifie qu’une valeur pour chaque mesure de proximité est associée à chaque ID du Canada. Un ID est défini comme une zone délimitée de tous les côtés par des routes et/ou les limites de régions géographiques normalisées. Les îlots de diffusion couvrent tout le territoire du Canada et constituent la plus petite région géographique pour laquelle les chiffres de population et des logements sont diffusés (Statistique Canada, 2017b)Note .
Aux fins de l’analyse, les mesures de proximité calculées correspondent aux 489 676 îlots de diffusion qui figurent dans les fichiers des limites cartographiques de Statistique Canada. Cela exclut 299 ID qui sont entièrement situés dans les eaux côtières (Statistique Canada, 2017). Le tableau 1 montre le nombre d’ID et les populations moyennes correspondantes par province et type de région.
| Région géographique | Îlot de diffusion (ID) | Population totale | Surface moyenne des ID | ||||||
|---|---|---|---|---|---|---|---|---|---|
| RMR | AR | Rural | RMR | AR | Rural | RMR | AR | Rural | |
| nombre | nombre | km carré | |||||||
| T.-N.-L. | 1 722 | 995 | 6 039 | 205 955 | 70 405 | 243 356 | 0,5 | 4,2 | 65,0 |
| Î.-P.-É. | Note ..: indisponible pour une période de référence précise | 1 455 | 2 184 | Note ..: indisponible pour une période de référence précise | 85 912 | 56 995 | Note ..: indisponible pour une période de référence précise | 0,8 | 2,3 |
| N.-É. | 3 513 | 3 886 | 7 880 | 403 390 | 205 184 | 315 024 | 1,8 | 2,2 | 5,5 |
| N.-B. | 4 140 | 3 400 | 6 805 | 271 012 | 197 031 | 279 058 | 1,6 | 5,6 | 7,2 |
| Qc | 55 333 | 14 048 | 36 870 | 5 760 407 | 864 450 | 1 539 504 | 0,3 | 1,5 | 39,0 |
| Ont. | 80 601 | 17 168 | 35 445 | 10 956 264 | 1 106 057 | 1 386 173 | 0,4 | 1,5 | 25,9 |
| Man. | 8 112 | 2 632 | 19 925 | 778 489 | 131 111 | 368 765 | 0,7 | 1,2 | 31,1 |
| Sask. | 7 836 | 4 618 | 41 664 | 531 576 | 175 700 | 391 076 | 1,3 | 1,8 | 14,7 |
| Alb. | 24 650 | 6 815 | 35 284 | 2 831 429 | 502 663 | 733 083 | 0,7 | 12,3 | 15,3 |
| C.-B. | 20 802 | 14 156 | 17 892 | 3 206 601 | 901 527 | 539 927 | 0,4 | 4,7 | 47,2 |
| Yn | Note ..: indisponible pour une période de référence précise | 612 | 907 | Note ..: indisponible pour une période de référence précise | 28 225 | 7 649 | Note ..: indisponible pour une période de référence précise | 13,7 | 493,2 |
| T.N.-O. | Note ..: indisponible pour une période de référence précise | 268 | 1 227 | Note ..: indisponible pour une période de référence précise | 19 569 | 22 217 | Note ..: indisponible pour une période de référence précise | 0,5 | 1 040,8 |
| Nt | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 792 | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 35 934 | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 2 538,6 |
| Canada | 206 709 | 70 053 | 212 914 | 24 945 123 | 4 287 834 | 5 918 761 | 0,5 | 3,6 | 43,2 |
|
Note : RMR signifie « région métropolitaine de recensement »; les RMR sont de grandes agglomérations de 100 000 habitants ou plus. |
|||||||||
Idéalement, les mesures de proximité des services doivent être calculées au niveau le plus détaillé possible. Plus concrètement, il pourrait s’agir des distances mesurées d’un endroit précis (p. ex. un immeuble) jusqu’à un autre endroit précis, où l’utilisateur peut avoir accès au service ou aux commodités. Cependant, la puissance de calcul et l’espace de stockage requis pour générer et enregistrer les distances mesurées dans le réseau routier à partir des emplacements des logements à l’échelle nationale seraient énormes. En outre, la confidentialité des renseignements opérationnels qui figurent dans le RE peut rendre difficile le partage des résultats à un microniveau. Pour toutes ces raisons, un certain degré d’agrégation spatiale est nécessaire.
Néanmoins, l’agrégation au niveau de l’ID présente certains inconvénients. Tout d’abord, la taille des ID varie beaucoup. Par exemple, dans la seule région d’Ottawa–Gatineau, la surface des ID va de 1 300 mètres carrés à 77 millions de mètres carrés. Le choix du centroïde des grands ID peut poser problème, car ce n’est pas nécessairement là que se trouvent les consommateurs ou les points de service. La distance de déplacement dans un ID est définie comme une fonction de la taille de l’ID. Lorsque l’ID est de petite taille, cette approximation ne pose pas de problème, mais elle peut être problématique pour les ID de plus grande taille. Les bâtiments et les populations des grands ID sont probablement étroitement regroupés dans une petite partie de l’ID plutôt que répartis uniformément dans son ensemble. Par conséquent, l’utilisation de la surface de l’ID pour estimer la distance de déplacement dans l’ID mènera probablement à une surestimation de la distance à parcourir pour se rendre aux services ou aux commodités dans cet ID. Cela peut signifier que la distance entre un petit ID et le centroïde d’un plus grand ID voisin peut être plus petite que la distance de déplacement au sein même de ce plus grand ID. Pour éviter ce problème, il faut prendre des mesures spéciales (voir l’équation 1).
Cela dit, à cause de la portée de l’analyse et de la classification géographique actuelle à Statistique Canada, la base de données fournit le meilleur équilibre entre la capacité de calcul et le détail géographique. Cette unité d’analyse couvre l’ensemble du Canada et fournit donc un niveau géographique de base auquel l’analyse peut être étendue pour couvrir l’ensemble du pays. Les limites des ID correspondent aux limites provinciales et municipales et ont tendance à se former autour des barrières naturelles, comme les cours d’eau. Les ID sont généralement plus petits dans les centres urbains et plus grands dans les régions moins peuplées. Par conséquent, les ID fournissent généralement un niveau élevé de détail géographique dans les régions à forte densité de population, et moins de détail géographique dans les régions moins peuplées. Les ID permettent aussi d’agréger les mesures à l’échelle des grandes régions géographiques de recensement comme les aires de diffusion (AD), les subdivisions de recensement (SDR), etc., car ces régions sont des agglomérations d’ID.
Calcul des distances
Le processus de calcul des distances réseau au moyen de la solution élaborée pour cette analyse comportait quatre étapes principales. Premièrement, déterminer les centroïdes des unités géographiques choisies (ID); deuxièmement, associer une latitude et une longitude à ces points; troisièmement, créer des paires au moyen de tous les points pertinents dans un rayon choisi et, finalement, soumettre ces paires de points au service de navigation hébergé à l’interne pour générer les distances réseau. Les distances obtenues ont ensuite été combinées pour produire un jeu de données qui a été utilisé comme un intrant principal dans le calcul des mesures de proximité.
Pour mesurer la proximité géographique, il faut transformer une surface géographique continue et bidimensionnelle en un ensemble de points discrets au moyen desquels on peut mesurer des distances. Il faut donc un point de départ et un point d’arrivée pour calculer les distances. Pour ce faire, on a établi un point représentatif dans chaque ID utilisé dans l’analyse. Ces points correspondent aux centroïdes géographiques. Dans les cas où le centroïde d’un ID était éloigné et ne se trouvait pas dans le réseau routier, il était associé à la route la plus proche pour permettre le calcul des distances.
Les distances réseau ont été calculées au moyen d’une combinaison d’OpenRouteService (ORS) et du réseau routier canadien utilisé par OpenStreetMap (OSM)Note . L’ORS est un service de navigation ouvert qui génère des distances sur le réseau routier en utilisant les données du réseau routier utilisé par OSM. Ce service peut être interrogé au moyen de Python et d’un ordinateur connecté à Internet. Cependant, l’API d’ORS impose une limite de 2 500 requêtes par jour. Pour remédier à ce problème, une machine virtuelle a été configurée dans un environnement infonuagique identique à l’API d’ORS. Cela a permis de dépasser la limite de 2 500 requêtes par jour. Cela a été rendu possible grâce à la nature ouverte du code d’ORS.
L’élaboration d’une méthode permettant de calculer efficacement les distances point à point dans le réseau routier a été un obstacle particulièrement difficile à surmonter dans le cadre de ce projet. Même avec la puissance de traitement élevée que l’instance d’ORS hébergée à l’interne sur une infrastructure infonuagique évolutive permettait d’atteindre, le calcul de toutes les distances dans le réseau routier a été particulièrement exigeant en matière de ressources informatiques. La génération de la base de données des distances correspondant à l’ensemble du Canada exigé environ 361 heures pour les paires d’ID situées dans un rayon de 30 km (tableau 2, note : les temps de calcul sont exprimés en minutes).
Pour tenir compte des différentes spécifications des mesures de proximité, trois bases de données de distances ont été calculées. La première est une base de données de distances de route dans le réseau routier entre des points de départ et tous les points d’arrivée correspondants dans un rayon de 30 km autour des points de départ. La base de données contient environ 2,6 milliards de distances d’ID à ID dans le réseau (tableau 2).
Les deuxième et troisième bases de données contiennent des distances dans le réseau piétonnier. La deuxième contient environ 226 millions de distances de marche d’ID à ID dans un rayon de 5 km autour des points de départ (tableau 2). La troisième contient environ 8 millions de distances de marche d’ID à arrêt de transport en commun dans un rayon de 1,5 km autour des points de départ.
| Région géographique | Paires d’ID à ID à situées dans un rayon géodésique de 30 km | Paires d’ID à ID situées dans un rayon de 30 km de route | Temps approximatif de calcul des distances dans le réseau routier | Paires d’ID à ID situées dans un rayon géodésique de 5 km | Paires d’ID à ID situées dans un rayon de 5 km de marche | Temps approximatif de calcul des distances dans le réseau routier |
|---|---|---|---|---|---|---|
| nombre | nombre | minutes | nombre | nombre | minutes | |
| T.-N.-L. | 5 935 501 | 4 244 621 | 49,46 | 1 113 164 | 790 674 | 9,28 |
| Î.-P.-É. | 3 781 022 | 2 679 558 | 31,51 | 541 504 | 360 228 | 4,51 |
| N.-É. | 19 415 455 | 14 368 806 | 161,8 | 3 300 982 | 2 061 498 | 27,51 |
| N.-B. | 15 335 142 | 11 039 253 | 127,79 | 2 798 496 | 1 767 710 | 23,32 |
| Qc | 1 089 561 404 | 707 844 112 | 9 079,68 | 74 628 916 | 44 952 737 | 621,91 |
| Ont. | 895 294 673 | 587 329 893 | 7460,79 | 72 033 085 | 47 204 161 | 600,28 |
| Man. | 72 807 306 | 56 467 920 | 606,73 | 10 248 154 | 6 547 074 | 85,4 |
| Sask. | 46 430 544 | 32 603 342 | 386,92 | 8 738 814 | 6 084 920 | 72,82 |
| Alb. | 223 542 898 | 169 797 165 | 1862,86 | 25 582 262 | 15 835 204 | 213,19 |
| C.-B. | 228 919 650 | 170 937 391 | 1 907,66 |
27 131 540 | 18 364 274 | 226,1 |
| Yn | 323 692 | 308 281 | 2,7 | 146 862 | 102 764 | 1,22 |
| T.N.-O. | 133 129 | 130 909 | 1,11 | 95 113 | 77 715 | 0,79 |
| Nt | 24 808 | 24 808 | 0,21 | 24 016 | 22 474 | 0,2 |
| Canada | 2 601 505 224 | 1 757 776 059 | 21 679,21 | 226 382 908 | 144 171 433 | 1 886,52 |
|
Note : Lorsque les points entre lesquels une mesure est calculée se trouvent de part et d’autre d’une frontière provinciale ou territoriale, la mesure est associée à l’ID de départ. Source : Calculs des auteurs. |
||||||
Pour calculer les indices de proximité d’un service donné, il faut introduire un rayon pour des raisons pratiques liées à la complexité des calculs et pour tenir compte du fait que la distance qu’une personne est susceptible de parcourir pour se rendre à la plupart des services est limitée. Le rayon d’application de cette analyse peut dépendre des services considérés. En général, on peut aisément supposer que les personnes sont disposées à parcourir une plus longue distance pour un emploi que pour accéder à la plupart des autres services. Par exemple, une personne qui cherche un emploi rémunérateur pourrait être disposée à se déplacer plus loin pour un tel emploi qu’elle le serait pour se rendre à l’épicerie. La sensibilité de l’indice de proximité aux changements dans le rayon a été testée. Dans le cadre de cet essai, on a constaté que les changements dans les petits rayons peuvent entraîner des changements significatifs (par exemple, accroître le rayon pour passer de 1 km à 3 km), mais que la sensibilité diminue pour les plus grands rayonsNote .
Un dernier problème méthodologique est le calcul d’un rayon qui limite les déplacements à l’intérieur de chaque ID. Ce rayon doit être introduit dans le modèle pour que la présence de services et de commodités à l’intérieur des ID d’origine soit correctement prise en compte. Comme les tailles des ID varient considérablement en fonction de l’emplacement, il faut définir un rayon limite propre à chaque ID et qui tient compte de sa taille. Ainsi, ce rayon, qui est la distance maximale à parcourir pour se rendre à un service dans un ID, a été défini comme une fonction de la taille de cet ID.
Pour éviter la surpondération (ou la sous-pondération) de taille des services (dont ceux d’emploi) dans un ID lors du calcul des mesures de proximité, la surface de cet ID est prise en compte de la façon suivante : elle est associée à un cercle de superficie identique, et le rayon de ce cercle est calculé; ce rayon est ensuite attribué comme distance au sein de cet ID. Par exemple, pour un ID dont la superficie est de 6 000 m2, si la même superficie était attribuée à un cercle, cela donnerait lieu à un rayon de 44 m pour cet ID.
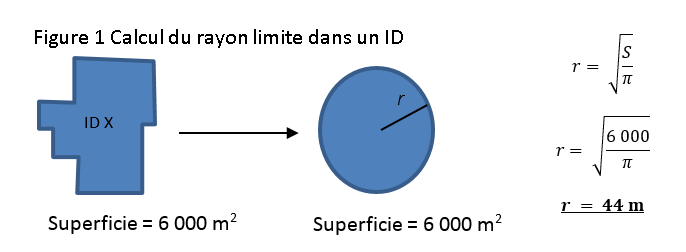
Description de la figure 1
La superficie d’un ID donné est liée à un cercle de superficie identique, et le rayon de ce cercle est calculé. Ce rayon est celui qui limite les déplacements dans l’ID. Par exemple, pour un ID dont la superficie est de 6 000 m2, si la même superficie était attribuée à un cercle (), cela donnerait lieu à un rayon de 44 m pour cet ID.
Mesure de la présence et de la taille des services
La mesure de la masse dépend en grande partie de la nature des services ou des commodités faisant l’objet de la mesure de proximité. Cette section présente certaines considérations générales ainsi que les approches utilisées pour calculer les neuf mesures de proximité mises au point dans le cadre de la présente analyse.
En général, on pourrait distinguer deux grandes approches : la pondération uniforme et la pondération non uniforme. Lorsque la pondération uniforme est utilisée, on attribue la valeur « 1 » à chaque ID qui contient l’emplacement d’un service ou des commodités donnés. Il en découle que tous les ID avec une quantité non nulle de services ou de commodités se voient accorder la même masse. Cette approche ne tient donc pas compte de l’ampleur de la prestation de services. Par exemple, un ID où se trouve un dépanneur aurait le même poids qu’un ID où se trouve un supermarché d’une grande chaîne. Avec la pondération non uniforme, la masse est proportionnelle à la taille du service. Par conséquent, le revenu d’une entreprise ou le nombre de ces employés pourraient être utilisés comme mesures de la masse.
En général, la pondération selon les revenus ou le nombre d’employés mène à une répartition asymétrique et dispersée des valeurs. Comme on pourrait le penser intuitivement, les revenus sont plus susceptibles de différencier les entreprises que la pondération uniforme. On peut se demander si la différenciation des entreprises par les revenus est une bonne mesure indirecte de la prestation de services, mais elle permet au moins de différencier un petit épicier et un grand supermarché en matière de services offerts. Cependant, bien que les revenus bruts ou le nombre d’employés soient d’imparfaites mesures indirectes de la disponibilité des services (p. ex. une épicerie ayant un revenu de 500 000 $ n’offre probablement pas cinq fois plus de services qu’une épicerie dont le revenu est de 100 000 $). Avec certaines transformations élémentaires des valeurs brutes, une mesure indirecte plus précise de la prestation de services peut être créée.
Toutes les masses sont déduites d’un jeu de données extrait du RE et concernant toutes les entreprises qui étaient actives de 2017 à 2019. L’information qui figurent dans le RE provient de nombreuses sources, dont les déclarations d’activités au niveau de l’entreprise. À la plupart des fins d’analyse, une telle caractéristique ne pose pas de problème. En ce qui concerne le calcul de mesures de proximité au niveau de la localité, les déclarations au niveau de l’entreprise peuvent surestimer la masse dans les régions où se trouvent des sièges sociaux et la sous-estimer dans des régions où se déroulent des activités d’exploitation. Prenons l’exemple d’une chaîne d’épiceries. Le siège social peut déclarer le nombre d’employés de tous ses magasins alors que les magasins sont les points de service. Pour atténuer ce problème, une méthode de répartition des employés des entités déclarantes entre emplacements a été élaborée. Les emplois sont répartis entre les emplacements proportionnellement aux populations des subdivisions de recensement (SDR) où ils se trouvent. Autrement dit, les emplacements situés dans les grandes SDR sont présumés avoir plus d’employés que ceux qui trouvent dans les petites SDR. Ce problème a été évité avec les revenus, car ils sont habituellement disponibles au niveau de l’emplacement.
Ensuite, les entités du RE qui ont une case postale comme adresse sont supprimées parce que l’emplacement réel de l’entité ne pouvait pas être déterminé, et les cases postales ne sont probablement pas des points de service. De plus, les coordonnées des entités pourraient être peu fiables au niveau de l’ID. Bien que de nombreuses entités soient géocodées au niveau de l’ID, bon nombre d’entre elles sont géocodées au moyen des codes postaux, et la précision des coordonnées pourrait être insuffisante. Les valeurs du RE qui n’étaient pas géocodées au niveau de précision requis ont été supprimées. Le plus grand nombre possible de ces valeurs ont été géocodées par appariement d’adresses au moyen d’OpenAddresses, un ensemble de données d’adresse ouvertes. Ces valeurs ont ensuite été ajoutées aux données d’analyse.
Ensuite, les entités définies comme des travailleurs autonomes aux revenus inférieurs à 30 000 $ ont été retirées des données d’analyse. Il s’agissait de s’assurer que les entreprises analysées étaient exploitées à temps plein.
Les données générales de l’emploi ont été vérifiées au niveau du SDR au moyen des valeurs annuelles d’emploi obtenues au Recensement de 2016 et dans le cadre de l’Enquête sur la population active (EPA) de 2017-2019. Comme 2016 était la plus récente année de recensement, les données de l’EPA de 2017-2019 ont été utilisées pour interpoler les données d’emploi du Recensement de 2016 et obtenir des valeurs de 2019 qui pourraient être comparées avec les données de l’emploi du RE.
Les microdonnées du Registre des entreprises ont été associées à un code à six chiffres du SCIAN. Cela offre une souplesse considérable pour pondérer la masse des entreprises de tous les secteurs ou de certains d’entre eux. Le niveau de détail du SCIAN peut être réduit ou augmenté selon les besoins analytiques du projet (cependant, la qualité des résultats et la capacité de les diffuser seront d’autant plus affectées que le niveau sectoriel sera fin). La spécification utilisée a été choisie à la suite d’essais d’autres options.
Sensibilité à d’autres spécifications
Pendant toute la mise en œuvre, divers tests de sensibilité ont été effectués. Pour chaque mesure de proximité, les spécifications méthodologiques ont pu être ajustées de plusieurs façons. Compte tenu du délai et des ressources nécessaires pour produire ces résultats expérimentaux, un effort concerté a été déployé pour mettre à l’essai les éléments méthodologiques jugés les plus importants. De plus, la plupart des essais ont été réalisés pour la région géographique sélectionnée au début du projet, et ils ne sont que brièvement résumés ici.
Une grande partie des essais porte sur la modification des données d’entrée ou de valeurs des variables de masse, de distance et de rayon dans l’équation. Plus précisément, des essais ont été effectués relativement aux spécifications suivantes :
- Concept de la distance : en particulier, l’approche du réseau routier (meilleure sur le plan conceptuel) par opposition à l’approche linéaire (plus pratique, puisqu’elle est moins onéreuse sur le plan des calculs).
- Niveau de détail géographique : en particulier, la classification par îlot de diffusion (ID) (meilleure sur le plan conceptuel) par opposition au concept des aires de diffusion (AD)Note (plus pratique, car elle est moins lourde sur le plan des calculs).
- Options en matière de masse : en particulier, l’utilisation des revenus et du nombre d’employés de l’entreprise (dans de nombreux cas, cette approche est meilleure conceptuellement) par opposition à une pondération uniforme des entreprises (plus pratique parce qu’elle pourrait poser moins de problèmes liés à la confidentialité et à la suppression des données).
- Rayon : en particulier, les grands rayons (dans certains cas, requis sur le plan conceptuel) par opposition à de petits rayons (plus pratiques, car ils sont moins lourds sur le plan des calculs).
- Mise à l’essai des options en matière de codes du SCIAN : en particulier, évaluation de l’efficacité de la méthodologie élaborée lorsque différents secteurs et niveaux de détail sont pris en considération.
Pour comparer les approches du réseau routier et des distances géodésiques, des mesures de proximité ont été calculées au niveau de l’AD lorsque la masse est fondée sur les revenus et le nombre d’employés. Les niveaux moyens et médians de proximité étaient généralement plus élevés lorsqu’ils étaient calculés au moyen d’une approche géodésique, ce qui est logique étant donné que plus d’AD se trouvent généralement dans un rayon géodésique que dans un rayon de réseau. L’utilisation des distances géodésiques peut mener à l’inclusion de services qui ne devraient pas l’être (par exemple, une épicerie de l’autre côté d’une rivière peut être proche au sens géodésique, mais être éloignée lorsqu’elle n’est accessible que par le réseau routier ou piétonnier). Comme une solution a été trouvée pour calculer efficacement les distances dans le réseau routier, ce sont ces distances qui ont été finalement choisies.
Des essais avec diverses spécifications suggèrent que la masse appropriée dans le modèle gravitationnel dépend probablement du contexte. Bien que les revenus puissent constituer une masse appropriée pour certains types de services (comme les épiceries), une pondération égale peut être plus logique dans d’autres cas (par exemple, en matière d’accès à une station-service ou à un café, la taille relative de cette entreprise n’a probablement pas d’intérêt).
Bien qu’on ait admis que l’ID est préférable à l’AD pour ce projet, une petite région géographique reflétant mieux une mesure locale qu’une plus grande, on a effectué des essais pour déterminer si la différence entre les résultats obtenus par les deux concepts géographiques était importante. Si une analyse au moyen des AD produisait des résultats semblables à une analyse au moyen des ID avec un coût de calcul considérablement réduit, l’AD serait l’unité géographique à utiliser. Les mesures n’étaient pas aussi similaires qu’attendu, car bien que les AD soient constituées d’ID, le remplacement des ID par des AD entraîne un changement du nombre de services dans le rayon considéré (en effet, le rayon d’une AD, tel que mesuré à partir de son centroïde, ne couvre pas les mêmes services que tous les ID qui la constituent). Les essais effectués avec des estimations de proximité au niveau de l’AD ont montré que les résultats étaient suffisamment différents des résultats obtenus avec les ID pour justifier l’effort de calcul et le temps requis pour générer les distances ID à ID.
Dans l’ensemble, les essais de sensibilité suggèrent une diminution de la sensibilité de l’indice de proximité lorsque le rayon augmente. Les essais ont aussi indiqué que la sensibilité de la mesure a tendance à diminuer lorsque le rayon augmente. Cela est élémentaire du point de vue conceptuel. À mesure que le rayon associé à un ID représentatif augmente, il couvre des services qui se trouvent dans un nombre croissant d’autres ID, ce qui augmente son niveau de proximité de ces services. Par conséquent, un indice de proximité représentatif augmente aussi avec le rayon, le niveau de proximité maximal étant relativement insensible aux changements du rayon. Par exemple, les résultats des essais indiquent que lorsqu’on utilise le revenu comme mesure indirecte et que l’on augmente le rayon pour le faire passer de 1 km à 3 km, cela donne lieu à des changements significatifs de l’indice moyen et à des changements d’envergure moyenne dans le classement. Cependant, les changements sont beaucoup plus petits lorsque le rayon est plus grand (par exemple, lorsque le rayon passe de 10 km à 15 km). Cela laisse entendre que la plupart des rayons supérieurs à 10 km sont à peu près équivalents, mais qu’il faudra peut-être accorder une attention particulière aux plus petits rayons.
Les agrégations de codes particuliers du SCIAN peuvent également avoir un effet sur la mesure de proximité, surtout si l’on tient compte du fait que des services particuliers présentent un intérêt stratégique particulier. Les entreprises des codes 44-45 du SCIAN (Commerce de détail), extraites comme sous-ensemble de l’ensemble de données du RE, en constituent un exemple. Certaines entreprises à revenu élevé jouent un rôle plus important que d’autres en matière de prestation de services dans la catégorie de commerce de détail, et la proximité de ces entreprises à revenu élevé peut être très souhaitable pour les résidents. Cependant, se limiter à des catégories particulières du SCIAN peut augmenter les difficultés liées à la confidentialité des données.
Ajustements visant à assurer le respect des exigences en matière de confidentialité
Les préoccupations relatives à la confidentialité de cette analyse concernant l’utilisation des fonds de microdonnées de Statistique Canada actuellement protégés par les dispositions de la Loi sur la statistique, dont le Registre des entreprises. La principale préoccupation en matière de confidentialité concerne le risque de pouvoir déterminer le revenu ou le nombre d’employés d’une entreprise donnée grâce aux mesures de proximité.
En raison du grand volume de données requis pour calculer les mesures de proximité, ainsi que de la nature de ces données, l’utilisation d’approches normalisées en matière de confidentialité pose plusieurs difficultés. Trois principales sources peuvent contribuent au risque sur le plan de la confidentialité : la classification géographique, la taille du rayon et le niveau des codes du SCIAN. Plus le détail de classification géographique utilisé est petit, plus grande est la probabilité d’avoir des régions géographiques qui ne comportent pas le nombre minimal d’entreprises requis et/ou d’avoir des problèmes concernant une entreprise dominante. De même, plus le rayon est petit, plus grande est la probabilité qu’une région géographique ne respecte pas le nombre minimal d’entreprises ou qu’il y ait une entreprise dominante. Enfin, la stratification par niveaux plus détaillés du SCIAN augmente la probabilité que des problèmes de confidentialité de la nature indiquée surviennent.
L’approche la plus simple a consisté à classer les variables d’entrée confidentielles (revenu et emploi) en intervalles. Le groupement par classe de ces données et la complexité des calculs ont réduit le risque de divulgation à un point tel que les exigences en matière de confidentialité ont été respectées.
Sommaire des 10 mesures de proximité
La méthodologie décrite dans la section précédente a servi au calcul de 10 mesures de proximité Les spécifications utilisées pour chacune d’elles sont décrites ci-après.
La mesure de la proximité des emplois établit la proximité d’un ID à tout autre ID où se trouve une source d’emplois et qui est situé à une distance d’au plus 10 km de route. Cette mesure est calculée en fonction du nombre d’employés de toutes les entreprises, c’est-à-dire de tous les codes du Système de classification des industries de l’Amérique du Nord (SCIAN) dans le Registre des entreprises (RE). Environ 3 millions d’entreprises ont servi au calcul de cette mesure. À titre de comparaison, le nombre total d’entreprises canadiennes (avec ou sans employés) était de 4 147 129 en décembre 2019, selon les données diffusées par Statistique CanadaNote . Il convient de noter que ces chiffres ne sont pas directement comparables, car trois années de données (2017 à 2019) ont été extraites du RE pour établir cette mesure de proximité, et les deux sources comportaient des différences méthodologiques pour ce qui est de la détermination des entreprises actives à analyser.
La masse de l’emploi a été déterminée en classant les entreprises selon leur nombre d’employés. Les entreprises ont été réparties en huit lots. Celles qui n’avaient pas d’employés (travailleurs autonomes) ont été retirées lorsque leurs revenus étaient inférieurs à 30 000 $. Les lots sont fondés sur le nombre d’employés de l’entreprise, soit : de 0 à 4 employés, de 5 à 9 employés, de 10 à 19 employés, de 20 à 49 employés, de 50 à 99 employés, de 100 à 199 employés, de 200 à 499 employés et plus de 500 employés. Dans chaque cas, la masse attribuée est la limite inférieure de la classe respective (par exemple, une entreprise qui a 7 employés se verrait attribuer une masse de 5). Lorsque le nombre d’employés a été déclaré au niveau du siège social (parent) plutôt qu’au niveau de l’emplacement de prestation de service individuel, le total a été réparti entre tous les emplacements enfants par pondération selon la population. La masse totale en matière d’emploi d’un îlot de diffusion est la somme des masses des services qui s’y trouvent.
La mesure de la proximité des épiceries établit la proximité d’un ID à tout autre ID où se trouve une épicerie et qui est situé à une distance de marche d’au plus 1 km. Cette mesure est calculée en fonction du revenu total de toutes les entreprises du code 4451 (Épiceries) du SCIAN qui figurent dans le Registre des entreprises. Environ 11 000 entreprises ont servi au calcul de cette mesure. À titre de comparaison, le nombre total d’entreprises canadiennes associées à ce code du SCIAN (avec ou sans employés) était de 22 579 en décembre 2019, selon les données diffusées par Statistique Canada. La masse totale d’un îlot de diffusion est la somme des masses des services qui s’y trouvent.
La masse de chaque entreprise a été déterminée à partir de ses revenus en lui attribuant une valeur de 1, 2, 3 ou 4, selon le quartile de revenus de l’entreprise à l’échelle nationale. Ce type de pondération fait en sorte que la masse d’une grande épicerie est au plus quatre fois plus grande que celle d’une petite épicerie. Une utilisation directe du revenu aurait pu mener à des différences de masse de plusieurs ordres de grandeur. Lorsque le nombre d’employés a été déclaré au niveau du siège social (parent) plutôt qu’au niveau de l’emplacement de prestation de service individuel, le total a été réparti entre tous les emplacements enfants par pondération selon la population.
La mesure de la proximité des pharmacies établit la proximité d’un ID à tout autre ID où se trouve une pharmacie et qui est situé à une distance de marche d’au plus 1 km. Cette mesure est calculée fondée sur la présence de toutes les entreprises du code 446110 du SCIAN (Pharmacies) qui figurent dans le Registre des entreprises. Environ 27 000 entreprises ont servi au calcul de cette mesure. À titre de comparaison, le nombre total d’entreprises canadiennes associées à ce code du SCIAN (avec ou sans employés) était de 12 965 en décembre 2019, selon les données diffusées par Statistique Canada. Le nombre élevé d’entreprises utilisées pour calculer la mesure de proximité des pharmacies par rapport aux données sur le nombre d’entreprises canadiennes peut être un signe que les pharmacies sont beaucoup plus sensibles aux différences méthodologiques, comme l’utilisation de trois années de données (2017 à 2019), que les autres types d’entreprises étudiées.
Comme on ne s’attend pas à ce que le service de base offert par une pharmacie soit proportionnel aux revenus ou au nombre d’employés, on a choisi une masse constante. Cela évite les problèmes potentiels liés aux sources de revenus non pharmaceutiques (vente de produits d’épicerie, etc.) qui peuvent masquer le « vrai » niveau de prestation de services. Comme la masse est constante, la masse d’un îlot de diffusion est de 1 si au moins une pharmacie s’y trouve.
La mesure de la proximité des établissements de soins de santé établit la proximité d’un ID à tout autre ID où se trouve un établissement de soins de santé et qui est situé à une distance de route d’au plus 3 km. Cette mesure est fondée sur le nombre d’employés de toutes les entreprises des codes 6211 (Cabinets de médecin), 6212 (Cabinets de dentiste), 6213 (Cabinets d’autres prestataires de services de santé), 621494 (Centres de santé communautaires) et 622 (Hôpitaux) du SCIAN qui figurent dans le Registre des entreprises. Environ 180 000 entreprises ont servi au calcul de cette mesure. À titre de comparaison, le nombre total d’entreprises canadiennes associées à ces codes du SCIAN (avec ou sans employés) était de 189 426 en décembre 2019, selon les données diffusées par Statistique Canada.
La masse de l’emploi a été déterminée en classant les entreprises selon leur nombre d’employés. Les entreprises ont été réparties en huit lots, et celles qui n’avaient pas d’employés (travailleurs autonomes) ont été retirées lorsque leurs revenus étaient inférieurs à 30 000 $. Les lots sont fondés sur le nombre d’employés de l’entreprise, soit : de 0 à 4 employés, de 5 à 9 employés, de 10 à 19 employés, de 20 à 49 employés, de 50 à 99 employés, de 100 à 199 employés, de 200 à 499 employés et plus de 500 employés. La masse totale d’un îlot de diffusion est la somme des masses des services qui s’y trouvent.
La mesure de la proximité des services de garde d’enfants établit la proximité d’un ID à tout autre ID où se trouve un service de garde d’enfants et qui est situé à une distance de marche d’au plus 1,5 km. Cette mesure est fondée sur la présence de toutes les entreprises du code 624410 (Services de garderie) du SCIAN qui figurent dans le Registre des entreprises, à l’exception des entreprises de travailleurs autonomes dont les revenus annuels sont inférieurs à 30 000 $. Environ 39 000 entreprises ont servi au calcul de cette mesure. À titre de comparaison, le nombre total d’entreprises canadiennes associées à ce code du SCIAN (avec ou sans employés) était de 41 383 en décembre 2019, selon les données diffusées par Statistique Canada.
Comme la prestation de ce service est assurée par un nombre relativement important de travailleurs autonomes qui compliquaient la définition d’une masse fondée sur l’emploi, une masse constante a été choisie. De plus, la masse d’un ID est de 1 si au moins un service de cette nature s’y trouve.
La mesure de la proximité des établissements d’enseignement primaire établit la proximité d’un ID à tout autre ID où se trouve une école primaire et qui est situé à une distance de marche d’au plus 1,5 km. Les écoles primaires sont classées comme des établissements d’enseignement de niveau 1 dans la Classification internationale type de l’éducation (CITE). Cette mesure est fondée sur une combinaison de données de la Base de données ouvertes sur les établissements d’enseignement (BDOEE)Note et d’autres sources de données de cette nature. Un total d’environ 11 000 écoles primaires ont servi au calcul de cette mesure. De plus, la masse d’un ID est de 1 si au moins un service de cette nature s’y trouve.
La BDOEE contient les écoles classées selon les niveaux de la CITE, lesquels sont associés à des fourchettes d’années. De plus amples détails sur les correspondances figurent dans Statistique Canada (2019). Pour le calcul de cette mesure, les niveaux suivants de la CITE ont été utilisés : Primaire (CITE1), qui va de la 1re à la 6e année; Secondaire de premier cycle (CITE2), qui va de la 7e à la 9e année; et Secondaire de deuxième cycle (CITE3), qui va de la 10e à la 12e année. À cet égard, l’avantage de la BDOEE par rapport au RE tient au fait qu’elle permet de considérer les écoles primaires séparément des écoles secondaires. Lorsqu’on tient compte du nombre total d’écoles appartenant à ces deux catégories, qui figurent dans les deux bases de données, il est évident que la BDOEE est préférable au RE. Le RE contient environ 3 300 écoles primaires et secondaires. En revanche, la BDOEE contient plus de 16 000 enregistrements répartis entre les niveaux 1, 2 et 3 de la CITE.
Les données sur les établissements d’enseignement ont été géocodées, au besoin, et filtrées pour exclure les écoles non publiques, dans la mesure du possible. Il a parfois été nécessaire de déterminer le niveau de la CITE à partir d’une fourchette d’années ou du nom de l’école.
La mesure de la proximité des établissements d’enseignement secondaire établit la proximité d’un ID à tout autre ID où se trouve une école secondaire et qui est situé à une distance de marche d’au plus 1,5 km. Les écoles secondaires sont classées selon les niveaux CITE2 (de la 7e à la 9e année) et CITE3 (de la 10e à la 9e année). Cette mesure est fondée sur une combinaison de données de la BDOEE et d’autres sources de données de cette nature.
Un total d’environ 5 000 écoles secondaires ont servi au calcul de cette mesure. De plus, la masse d’un ID est de 1 si au moins un service de cette nature s’y trouve.
La mesure de la proximité du transport en commun établit la proximité d’un ID à tout point de service de transport en commun qui est situé à une distance de marche d’au plus 1 km. Cette mesure de masse est fondée sur le nombre de déplacements effectués entre 7 h et 10 h, obtenu d’un ensemble de sources de données de la General Transit Feed Specification (GTFS).
La proximité au transport en commun est calculée à partir des données de la GTFS. La mesure de la proximité présentée dans cette analyse tient compte du nombre d’autobus ou de trains individuels qui desservent chaque arrêt au cours d’un intervalle de temps donné (entre 7 h et 10 h les matins de semaine). Pour cette mesure, les masses ne sont pas appliquées aux îlots de diffusion, mais aux arrêts individuels de transport en commun.
Bien qu’il n’existe pas de liste de tous les réseaux de transport en commun au Canada, et encore moins une liste de tous les réseaux de transport en commun au Canada pour lesquels des données GTFS sont disponibles, des efforts ont été déployés pour recueillir le plus grand nombre de données possible. Ainsi, 94 sources de données GTFS individuelles ont été utilisées pour créer la base de données, qui couvre les réseaux locaux et intermunicipaux de transport en commun. Puisque ce ne sont pas toutes les sources de données qui mettent fréquemment à jour leurs données dans la GTFS, les périodes de référence des ensembles de données ne sont pas uniformes. Pour produire une mesure qui rend compte du service moyen en semaine le matin, on a déterminé le nombre de déplacements un mercredi matin donné, pour tous les ensembles de données. Environ 130 000 arrêts individuels ont servi au calcul de cette mesure.
De plus, pour cette mesure, on a tenté de déterminer les régions qui ont des services de transport en commun, mais qui n’ont pas de données GTFS, ou qui semblent avoir des données GTFS (sur la base de l’horaire du système de transport en commun intégré dans Google Maps). Lorsqu’on a déterminé l’existence de données sur le transport en commun et qu’il n’a pas été possible de les trouver au moyen de recherches sur le Web, on a communiqué avec les municipalités et les administrations de transport en commun pour demander ces données. La base de données obtenue indique s’il existe des données sur le transport en commun dans la colonne transit_na, où les entrées ont été associées au code 2 si les données GTFS n’étaient pas accessibles, mais qu’on a supposé qu’elles existent pour la SDR considérée. Il s’agit d’une mise en correspondance imparfaite, car il n’y a pas de relation entre les limites des SDR et les réseaux de transport en communNote .
La mesure de la proximité des parcs de quartier établit la proximité d’un ID à tout autre ID où se trouve un parc de quartier et qui est situé à une distance de marche d’au plus 1 km. Cette mesure est fondée sur la présence de tous les parcs, selon les renseignéments tirés de sources sûres de données ouvertes et d’OpenStreetMap. Un total d’environ 48 000 parcs ont été utilisés pour calculer cette mesure. De plus, la masse d’un ID est de 1 si au moins un service de cette nature s’y trouve.
Après avoir obtenu les renseignements concernant les parcs à partir de portails de données ouvertes, un petit nombre d’enregistrements ont été géocodés, et tous les enregistrements ont été nettoyés à l’aide des renseignements disponibles sur les types de parcs. Il n’existe pas de système de classification standard des parcs, de sorte que les ensembles de données contenaient parfois des entrées qui étaient considérées comme hors du champ de l’étude (p. ex. musées, terrains de golf, arénas). Un certain nombre de tels parcs ont été supprimés de l’analyse.
En ce qui concerne les données d’OpenStreetMap, certains parcs n’avaient pas de nom. Lorsqu’ils avaient un nom qui comportait le mot « provincial », « national » ou « régional », ils ont été supprimés. Il s’agissait de faire en sorte, dans la mesure du possible, que seuls les parcs communautaires locaux soient inclus. Comme la présence d’information en double était possible dans les données d’OpenStreetMap et des sources de données ouvertes, tous les doublons ont été éliminés sur la base de considérations de proximité. Ainsi, tous les parcs situés à moins de 25 mètres d’un autre parc ont été considérés comme des doublons et ont été supprimés. Ce seuil a été choisi après avoir effectué une analyse des plus proches voisins pour déterminer la distance moyenne la plus courte entre parcs dans l’ensemble de données. Il est beaucoup plus petit que la distance moyenne. Sur le plan conceptuel, un seuil relativement petit a été choisi, car les parcs peuvent être assez proches les uns des autres (p. ex. ils peuvent se trouver de part et d’autre d’une rue).
La mesure de la proximité des bibliothèques publiques établit la proximité d’un ID à tout autre ID où se trouve une bibliothèque et qui est situé à une distance de marche d’au plus 1,5 km. Cette mesure est fondée sur tous les renseignements concernant les bibliothèques tirés d’un ensemble de sources de données ouvertes et publiques. Au total, environ 3 000 bibliothèques ont servi au calcul de cette mesure. De plus, la masse d’un ID est de 1 si au moins un service de cette nature s’y trouve.
Au besoin, les données sur les bibliothèques ont été géocodées au moyen d’une combinaison de Nominatim, de Bing et de recherches manuelles sur Internet. Les entrées qui ne pouvaient pas être géocodées avec précision ont été supprimées. Les bibliothèques dont le nom suggérait une bibliothèque universitaire ou professionnelle privée n’ont pas été prises en compte. Enfin, des bibliothèques en double été éliminées sur la base d’un critère de proximité. Un seuil de 150 mètres a été utilisé. Ainsi, une bibliothèque située à une distance de 150 mètres d’une autre a été considérée comme un doublon et a été supprimée. Ce seuil a été choisi en cours de traitement, après une analyse des plus proches voisins visant à déterminer la distance moyenne entre les bibliothèques. Il est beaucoup plus petit que la plus courte distance moyenne entre bibliothèques. Sur le plan conceptuel, cette distance est voisine de la taille d’un îlot standard, et il est peu probable que deux bibliothèques publiques se trouvent à un ou deux pâtés de maisons l’une de l’autre.
Résultats
Cette section présente les résultats obtenus pour les indicateurs décrits dans la section précédente, en commençant par la mesure la plus générale de proximité, soit celle des emplois, suivie par les mesures fondées sur les données du Registre des entreprises, puis par les trois mesures entièrement fondées sur des données ouvertes et accessibles au public.
Pour chaque mesure, les résultats sont présentés selon le pourcentage de la population qui se trouve à l’intérieur de différents rayons de proximité par rapport aux services ou commodités. Dans les tableaux, les résultats sont ventilés selon la région métropolitaine de recensement (RMR, l’agglomération de recensement (AR) (ci-après désignées ensembles comme régions urbaines) et les régions hors RMR/AR (ci-après désignées comme régions rurales)Note .
De plus, pour chaque type de région, les tableaux indiquent la part de la population qui se trouve dans trois tertiles de proximité, définis comme inférieur, intermédiaire et supérieur, pour des raisons de simplicité et de comparabilité. Ces champs montrent le pourcentage de la population qui se situent dans les trois tertiles de l’indice de proximité (qui va de 0 à 1). Le champ « extérieur » montre le pourcentage de la population qui vit dans un ID à l’extérieur du rayon utilisé pour calculer la mesure de proximité du service en question — cette population n’a pas accès au service, en raison des spécifications utilisées à l’heure actuelle.
De plus, la colonne « F » de chaque tableau indique le pourcentage de la population des ID pour lequel les mesures de proximité sont « trop peu fiables pour être publiées ». Les colonnes « F » sont identiques dans tous les tableaux suivants, car lorsque les résultats ne sont pas fiables, toutes les mesures de proximité des ID sont supprimées. Le symbole qui figure dans ces tableaux indique qu’une valeur de l’indice de proximité a été supprimée en raison d’une incohérence entre les sources de données et/ou de très faibles chiffres de population. Il convient de noter que les valeurs de ces colonnes sont identiques, pour chaque type de région, dans tous les tableaux de mesures de proximité; elles sont cependant présentées dans tous les tableaux par souci d’exhaustivité, de sorte que la somme des pourcentages régionaux donne 100 %.
Chaque tableau présente les résultats par province et territoire, et pour le Canada dans son ensemble (ces données sont fondées sur l’agrégation de tous les ID). En outre, la dernière ligne du tableau présente les pourcentages par rapport à la population totale du Canada (au lieu de la population totale des régions considérées de chaque type).
Il convient de noter que la Base de données des mesures de proximité a été diffusée dans le format CSVNote . Chaque enregistrement d’ID de la base de données comporte le code d’identification unique de l’ID, les chiffres de population, dix valeurs indices normalisées, ainsi qu’une mesure composite de la densité des services dans le quartier. En outre, les résultats correspondant à chaque ID peuvent être visualisés au moyen d’une application cartographique en ligne qui a initialement été élaborée pour effectuer des vérifications de qualité et des validations. Une version plus avancée a ensuite été diffusée sous le nom deVisualiseur de données sur les mesures de proximitéNote . Le Visualiseur permet aux utilisateurs de passer d’une vue à l’autre de différentes mesures, d’effectuer des recherches au niveau régional par subdivision de recensement (municipalité), et de regarder rapidement différentes localités de plus près. La Base de données et le Visualiseur rendent possible des analyses, des comparaisons et l’établissement de repères détaillés, pour les quartiers et les localités partout au Canada.
Proximité des emplois
La mesure de la proximité des emplois permet de bien comprendre la concentration géographique des emplois. Elle a été établie au moyen de la base de données la plus complète et la plus précise sur l’emploi au sein des entreprises (le Registre des entreprises) et des renseignements géographiques normalisés les plus détaillés au pays. Par conséquent, les résultats tiennent compte de la concentration des emplois dans les zones urbaines, ainsi que de la taille des agglomérations urbaines.
La grande majorité des Canadiens, soit plus de 98 %, vivent à 10 km de route d’entreprises qui offrent des emplois. Comme on pouvait s’y attendre, la répartition varie considérablement entre les régions plus urbaines, où presque toute la population se trouve à un certain degré de proximité (10 km de route) des emplois, et les régions rurales, où 8,4 % de la population vit à plus de 10 km d’une entreprise comptant des employés (tableau 3).
Le tableau 3 montre les résultats par province et territoire, ainsi que les principales différences entre, d’une part, Terre-Neuve-et-Labrador, les provinces des Prairies et les territoires et, d’autre part, les autres provinces du Canada. Dans le premier groupe, dont la population rurale est plus dispersée, on voit qu’entre 12 % et 40 % de la population vit à plus de 10 km d’une entreprise comptant des employés. Les pourcentages correspondants pour le deuxième groupe sont généralement minimes, moins de 4 % de la population rurale vivant à plus de 10 km d’une telle entreprise.
Cette mesure offre une vue d’ensemble de la concentration spatiale des emplois de tout type offerts par les entreprises ayant des employés. Elles pourraient être recalculées pour des types particuliers d’emplois. Elles pourraient aussi être améliorées pour tenir compte des facteurs d’offre de main-d’œuvre dans les mêmes intervalles de proximités. De plus, il convient de noter que ces mesures de proximité sont calculées au moyen des estimations d’emploi qui figurent dans le RE de 2019. À cause de la crise de la COVID-19, cette mesure est particulièrement pertinente pour établir des données repères qui permettront d’assurer le suivi de changements potentiels dans les lieux d’emploi et de déterminer les quartiers qui pourraient être le plus durement touchés par l’évolution du marché du travail.
| Région géographique | RMR | AR | Rural | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | |
| T.-N.-L. | Note ..: indisponible pour une période de référence précise | 7,8 | 51,7 | 40,5 | 0,0 | 0,2 | 21,9 | 77,0 | 0,2 | 0,7 | 11,9 | 61,5 | 22,6 | 0,1 | 4,0 |
| Î.-P.-É. | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 24,0 | 63,0 | 13,1 | 0,0 | 0,0 | 87,0 | 12,3 | Note ..: indisponible pour une période de référence précise | 0,6 |
| N.-É. | 0,0 | 22,6 | 35,8 | 41,3 | 0,1 | 0,2 | 31,3 | 66,5 | 1,9 | 0,1 | 0,5 | 67,6 | 31,7 | 0,0 | 0,2 |
| N.-B. | 0,1 | 22,4 | 50,4 | 26,9 | 0,2 | 0,2 | 36,9 | 56,3 | 6,5 | 0,1 | 0,5 | 73,7 | 25,7 | Note ..: indisponible pour une période de référence précise | 0,1 |
| Qc | 0,0 | 4,4 | 24,8 | 70,8 | 0,0 | 0,1 | 15,7 | 63,7 | 20,4 | 0,1 | 0,9 | 54,1 | 44,4 | 0,1 | 0,5 |
| Ont. | 0,0 | 4,6 | 20,8 | 74,6 | 0,0 | 0,0 | 22,7 | 62,2 | 14,9 | 0,2 | 2,2 | 55,3 | 41,5 | 0,2 | 0,8 |
| Man. | 0,2 | 6,3 | 19,3 | 74,1 | 0,1 | 1,6 | 11,7 | 68,4 | 17,9 | 0,5 | 21,5 | 38,6 | 33,0 | 0,1 | 6,8 |
| Sask. | 1,6 | 5,1 | 21,2 | 71,8 | 0,2 | 4,5 | 9,9 | 75,0 | 9,4 | 1,1 | 39,6 | 27,7 | 23,1 | 0,0 | 9,5 |
| Alb. | 0,1 | 6,0 | 29,6 | 64,2 | 0,1 | 0,8 | 6,9 | 58,8 | 33,2 | 0,4 | 19,9 | 37,9 | 39,0 | 0,2 | 3,0 |
| C.-B. | 0,0 | 3,0 | 18,7 | 78,3 | 0,0 | 0,1 | 16,0 | 66,5 | 17,3 | 0,1 | 3,2 | 51,9 | 44,2 | 0,1 | 0,7 |
| Yn | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 7,5 | 20,1 | 65,9 | 6,4 | 0,0 | 38,3 | 34,2 | 10,2 | Note ..: indisponible pour une période de référence précise | 17,3 |
| T.N.-O. | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 0,0 | 11,5 | 81,4 | 7,0 | 0,1 | 22,5 | 27,7 | 28,6 | Note ..: indisponible pour une période de référence précise | 21,1 |
| Nt | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 39,3 | 6,8 | 28,1 | 0,5 | 25,4 |
| Canada | 0,1 | 5,1 | 23,2 | 71,6 | 0,1 | 0,4 | 18,2 | 64,0 | 17,1 | 0,2 | 8,4 | 51,3 | 37,9 | 0,1 | 2,2 |
| % de la population totale | 0,0 | 3,6 | 16,5 | 50,8 | 0,0 | 0,1 | 2,2 | 7,8 | 2,1 | 0,0 | 1,4 | 8,6 | 6,4 | 0,0 | 0,4 |
|
Note : La mesure de la proximité des emplois établit la proximité d’un ID à tout autre ID où se trouve une source d’emplois. Cette mesure est calculée selon l’emplacement d’entreprises comptant des employés (tous les codes du SCIAN), situées à une distance de route d’au plus 10 km. Source : Calculs des auteurs. |
|||||||||||||||
Proximité des épiceries
Pour la plupart des Canadiens, une visite à l’épicerie pour acheter de la nourriture est une nécessité quotidienne. C’est pourquoi la proximité a été définie comme la présence de ce type de magasin à une distance de marche d’au plus 1 km. Dans l’ensemble du Canada, près de la moitié (46 %) de la population vit dans un quartier ou une localité qui présente cette caractéristique. Cependant, on constante de grandes différences entre les régions urbaines et rurales, ainsi qu’entre les provinces et les territoires (tableau 4).
Dans l’ensemble, la majorité (55 %) de la population des RMR se trouve à une certaine proximité d’une épicerie; ce pourcentage diminue pour passer à 30 % pour la population des AR, puis à 16 % pour les populations rurales (tableau 4). Le Québec, l’Ontario, le Manitoba et la Colombie-Britannique affichent les proportions les plus élevées de leur population métropolitaine qui vit à proximité d’un grand nombre d’épiceries. Au contraire, les provinces de l’Atlantique présentent les plus fortes proportions de populations des RMR et des AR qui vivent à plus de 1 km d’une épicerie (plus de 64 % ou de 74 %, respectivement). Le Visualiseur de données sur les mesures de proximité fournit une cartographie de ces quartiers à l’échelle du Canada.
En ce qui a trait aux régions métropolitaines, cette mesure de proximité peut contribuer à améliorer la compréhension de ce que l’on appelle les « déserts alimentaires », c’est-à-dire les régions où l’accès à des magasins d’alimentation à distance de marche est limité ou absent. Il convient néanmoins de noter que la spécification actuelle ne rend compte que d’un seul type d’entreprise (code SCIAN) qui donne accès aux aliments. Bien que les épiceries soient le type le plus courant de magasin d’alimentation que les familles canadiennes fréquentent, plusieurs autres types de détaillants offrent différents degrés d’accès aux aliments (p. ex. les marchés de producteurs).
Dans les régions rurales, il n’est pas surprenant que l’accès à une épicerie exige pour la grande majorité de la population un déplacement de plus de 1 km. Cependant, parmi les services pris en compte dans cette analyse, les épiceries figurent parmi les plus accessibles, même en milieu rural. Dans toutes les provinces, de 10 % à 20 % environ de la population rurale vit à moins de 1 km de marche d’une épicerie, sans doute le principal type de magasin que l’on retrouve dans les régions rurales et les petites villes du Canada.
| Région géographique | RMR | AR | Rural | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | |
| T.-N.-L. | 70,0 | 10,2 | 12,8 | 6,9 | 0,0 | 82,8 | 5,7 | 6,7 | 4,2 | 0,7 | 85,1 | 5,5 | 3,9 | 1,6 | 4,0 |
| Î.-P.-É. | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 74,0 | 9,4 | 9,3 | 7,3 | 0,0 | 89,8 | 3,6 | 4,4 | 1,6 | 0,6 |
| N.-É. | 64,3 | 13,6 | 11,1 | 10,8 | 0,1 | 81,3 | 7,0 | 8,0 | 3,5 | 0,1 | 89,8 | 4,1 | 4,7 | 1,2 | 0,2 |
| N.-B. | 77,9 | 7,5 | 8,1 | 6,2 | 0,2 | 84,9 | 4,9 | 6,4 | 3,6 | 0,1 | 88,5 | 5,6 | 4,2 | 1,6 | 0,1 |
| Qc | 41,8 | 15,7 | 15,3 | 27,3 | 0,0 | 62,4 | 12,8 | 14,3 | 10,3 | 0,1 | 79,4 | 8,2 | 7,6 | 4,4 | 0,5 |
| Ont. | 44,3 | 18,3 | 16,7 | 20,6 | 0,0 | 70,5 | 11,9 | 11,0 | 6,3 | 0,2 | 83,8 | 5,9 | 6,5 | 3,0 | 0,8 |
| Man. | 43,2 | 16,4 | 19,1 | 21,2 | 0,1 | 65,7 | 12,6 | 11,3 | 9,8 | 0,5 | 78,8 | 5,2 | 5,2 | 3,9 | 6,8 |
| Sask. | 52,4 | 18,4 | 17,0 | 11,9 | 0,2 | 65,7 | 15,0 | 12,2 | 6,0 | 1,1 | 72,3 | 5,6 | 8,1 | 4,6 | 9,5 |
| Alb. | 52,0 | 19,1 | 16,4 | 12,4 | 0,1 | 62,3 | 16,4 | 13,2 | 7,7 | 0,4 | 79,8 | 6,6 | 6,9 | 3,7 | 3,0 |
| C.-B. | 36,8 | 17,6 | 15,0 | 30,6 | 0,0 | 73,5 | 10,0 | 9,8 | 6,6 | 0,1 | 83,9 | 6,3 | 5,9 | 3,2 | 0,7 |
| Yn | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 72,6 | 11,0 | 12,7 | 3,6 | 0,0 | 81,4 | 1,3 | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 17,3 |
| T.N.-O. | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 63,5 | 13,0 | 16,0 | 7,4 | 0,1 | 57,1 | 5,7 | 10,1 | 6,0 | 21,1 |
| Nt | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 59,6 | 4,3 | 6,1 | 4,6 | 25,4 |
| Canada | 44,7 | 17,4 | 16,0 | 21,9 | 0,1 | 69,6 | 11,7 | 11,3 | 7,1 | 0,2 | 81,5 | 6,4 | 6,5 | 3,4 | 2,2 |
| % de la population totale | 31,7 | 12,3 | 11,4 | 15,5 | 0,0 | 8,5 | 1,4 | 1,4 | 0,9 | 0,0 | 13,7 | 1,1 | 1,1 | 0,6 | 0,4 |
|
Note : La mesure de la proximité des épiceries établit la proximité d’un ID à tout autre ID où se trouve une épicerie et qui est situé à une distance de marche d’au plus 1 km. Les épiceries sont les entreprises du code 4451 (Épiceries) du SCIAN qui figurent dans le Registre des entreprises. Source : Calculs des auteurs. |
|||||||||||||||
Proximité des pharmacies
L’accès aux pharmacies est généralement perçu comme une nécessité fondamentale dans la vie quotidienne d’une famille typique. Pour cette raison, la proximité des pharmacies est définie comme la présence à une distance de marche d’au plus 1 km; il n’y a pas de poids attribué au point de service, de sorte que la mesure repose entièrement sur la distance physique du service.
Selon cette spécification, près de 60 % des Canadiens vivent à proximité d’une pharmacie (tableau 5). C’est dans les grandes régions urbaines (RMR) que se trouve la plus grande proportion de personnes qui vivent à proximité de ce service. En effet, dans ces régions, un peu plus de 70 % de la population vit à 1 km de marche d’une pharmacie. L’Ontario et la Colombie-Britannique affichent les plus grandes proportions de populations urbaines vivant à proximité d’une pharmacie, ainsi que le plus haut niveau d’accès correspondant (le tertile supérieur de la distribution des mesures de proximité). Dans toutes les autres provinces à l’exception des provinces de l’Atlantique, une majorité de la population des RMR vit à proximité d’une pharmacie.
Une part plus petite, mais conséquente, de la population des petites régions métropolitaines (AR) et une part encore plus petite de la population des régions rurales jouissent d’une proximité à ce type de service (distance de marche d’au plus 1 km). Mais il y a encore de grandes différences entre les provinces. Près de la moitié de la population des AR des provinces des Prairies vit à 1 km de marche d’une pharmacie. Dans les provinces de l’Atlantique, cette proportion diminue pour passer à environ 30 %. Dans les territoires, les résidents des AR du Yukon sont ceux dont la proximité des pharmacies est la plus faible. En revanche, les résidents des AR des Territoires du Nord-Ouest ont un assez bon accès aux pharmacies.
Environ 20 % des résidents des régions rurales du Canada vivent à proximité d’une pharmacie (distance de marche d’au plus 1 km). Dans l’ensemble, les résidents des régions rurales de l’Ontario, du Québec et de la Colombie-Britannique sont plus susceptibles de vivre à proximité de ce type de service. La population rurale des provinces de l’Atlantique est la moins susceptible de vivre à proximité de ces services.
| Région géographique | RMR | AR | Rural | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | |
| T.-N.-L. | 57,7 | 17,2 | 15,0 | 10,1 | 0,0 | 69,5 | 16,4 | 10,4 | 3,1 | 0,7 | 86,7 | 6,3 | 2,6 | 0,4 | 4,0 |
| Î.-P.-É. | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 67,1 | 12,0 | 9,7 | 11,2 | 0,0 | 89,5 | 6,4 | 3,3 | 0,2 | 0,6 |
| N.-É. | 50,2 | 19,9 | 14,2 | 15,6 | 0,1 | 70,7 | 13,4 | 10,6 | 5,2 | 0,1 | 84,9 | 7,9 | 4,7 | 2,3 | 0,2 |
| N.-B. | 63,9 | 15,6 | 12,3 | 8,0 | 0,2 | 69,6 | 15,6 | 8,5 | 6,1 | 0,1 | 86,2 | 8,0 | 4,2 | 1,5 | 0,1 |
| Qc | 32,7 | 19,1 | 20,1 | 28,1 | 0,0 | 56,2 | 17,0 | 14,2 | 12,4 | 0,1 | 79,9 | 9,5 | 6,9 | 3,1 | 0,5 |
| Ont. | 23,6 | 20,7 | 25,1 | 30,6 | 0,0 | 57,6 | 17,8 | 13,7 | 10,7 | 0,2 | 79,2 | 9,6 | 7,1 | 3,3 | 0,8 |
| Man. | 28,9 | 21,6 | 27,3 | 22,1 | 0,1 | 50,0 | 18,6 | 15,3 | 15,6 | 0,5 | 77,6 | 7,7 | 5,5 | 2,3 | 6,8 |
| Sask. | 34,3 | 24,4 | 25,4 | 15,7 | 0,2 | 52,2 | 15,0 | 18,4 | 13,3 | 1,1 | 79,3 | 5,8 | 3,5 | 1,9 | 9,5 |
| Alb. | 32,5 | 25,3 | 25,2 | 16,8 | 0,1 | 43,9 | 26,7 | 18,0 | 11,0 | 0,4 | 77,0 | 10,0 | 6,8 | 3,2 | 3,0 |
| C.-B. | 24,1 | 19,2 | 21,1 | 35,6 | 0,0 | 61,3 | 15,3 | 13,5 | 9,8 | 0,1 | 79,9 | 10,6 | 5,7 | 3,1 | 0,7 |
| Yn | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 91,7 | 1,4 | 1,8 | 5,0 | 0,0 | 82,7 | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 17,3 |
| T.N.-O. | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 64,0 | 16,2 | 8,2 | 11,4 | 0,1 | 71,6 | 6,0 | 1,3 | Note ..: indisponible pour une période de référence précise | 21,1 |
| Nt | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 70,1 | 2,6 | 1,8 | 0,0 | 25,4 |
| Canada | 28,3 | 20,7 | 23,1 | 27,8 | 0,1 | 57,9 | 17,5 | 13,9 | 10,5 | 0,2 | 80,0 | 9,0 | 6,0 | 2,8 | 2,2 |
| % de la population totale | 20,1 | 14,7 | 16,4 | 19,8 | 0,0 | 7,1 | 2,1 | 1,7 | 1,3 | 0,0 | 13,5 | 1,5 | 1,0 | 0,5 | 0,4 |
|
Note : La mesure de la proximité des pharmacies établit la proximité d’un ID à tout autre ID où se trouve une pharmacie et qui est situé à une distance de marche d’au plus 1 km. Cette mesure est fondée sur la présence de toutes les entreprises du code 446110 du SCIAN (Pharmacies) qui figurent dans le Registre des entreprises. Source : Calculs des auteurs. |
|||||||||||||||
Proximité des établissements de soins de santé
La mesure de la proximité des établissements de soins de santé a revêtu une pertinence tout particulièrement importante au cours de la dernière année, ce qui a mené à de nouveaux développements en matière de données de géolocalisation des établissements de soins de santéNote . Cette mesure est fondée sur l’emplacement de certains types d'établissements de soins de santé figurant dans le Registre des entreprises (voir la section 3).
Dans l’ensemble, environ 88 % de la population canadienne vit dans une localité ou un quartier situé à 3 km de route d’un établissement de soins de santé (tableau 6). La grande majorité des résidents des grandes régions métropolitaines (97 %) se trouvent à 3 km de route d’un établissement de soins de santé. Pour les résidents des plus petites régions métropolitaines, ce pourcentage diminue pour passer à 87 %. Cependant, dans l’ensemble, seulement la moitié environ des résidents de régions rurales jouissent d’un tel degré de proximité d’un établissement de soins de santé.
Les résidents de la Colombie-Britannique qui vivent dans une RMR affichent du plus haut degré de proximité de ces services, compte tenu des distances et des masses correspondantes. Moins de 1 % des personnes vivent dans des quartiers situés à plus de 3 km de route d’un tel service et près de 56 % de la population est associée au tertile supérieur de la distribution des mesures de proximité. En matière de proximité des établissements de soins de santé, la Colombie-Britannique est suivie de l’Ontario (moins de 3 % de la population vit à l’extérieur du rayon précisé, et 45,6 % est associée au tertile supérieur des indices de proximité) et du Québec (les valeurs correspondantes étant de moins de 3 % et de 43,8 %).
Les résultats pour les petites régions urbaines (AR) indiquent une certaine diversité macrorégionale. Les résidents des AR des provinces de l’Atlantique étant légèrement plus susceptibles de vivre à plus de 3 km de route d’un établissement de soins de santé. Enfin, environ 50 % des résidents des régions rurales doivent parcourir plus de 3 km de route pour avoir accès à des services de santé. La Colombie-Britannique a la plus faible proportion de population rurale devant faire plus de 3 km de route pour accéder à des services de santé (37,7 %). Les proportions les plus élevées se trouvent à l’Île-du-Prince-Édouard (74,1 %), en Saskatchewan (69 %) et à Terre-Neuve-et-Labrador (62,9 %).
| Région géographique | RMR | AR | Rural | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | |
| T.-N.-L. | 3,0 | 43,3 | 31,1 | 22,6 | 0,0 | 15,8 | 43,9 | 27,6 | 12,0 | 0,7 | 62,9 | 22,3 | 7,7 | 3,2 | 4,0 |
| Î.-P.-É. | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 18,9 | 37,6 | 29,4 | 14,1 | 0,0 | 74,1 | 19,8 | 5,3 | 0,2 | 0,6 |
| N.-É. | 7,5 | 38,0 | 31,1 | 23,2 | 0,1 | 24,0 | 40,2 | 17,8 | 17,9 | 0,1 | 51,6 | 31,9 | 12,5 | 3,9 | 0,2 |
| N.-B. | 15,9 | 33,7 | 28,3 | 21,9 | 0,2 | 21,5 | 46,9 | 23,5 | 8,0 | 0,1 | 55,9 | 35,8 | 6,8 | 1,4 | 0,1 |
| Qc | 2,3 | 19,3 | 34,5 | 43,8 | 0,0 | 9,4 | 34,4 | 33,2 | 22,9 | 0,1 | 43,5 | 42,8 | 11,6 | 1,6 | 0,5 |
| Ont. | 2,4 | 14,1 | 37,9 | 45,6 | 0,0 | 16,2 | 26,0 | 26,5 | 31,2 | 0,2 | 47,4 | 28,3 | 14,6 | 8,9 | 0,8 |
| Man. | 4,6 | 15,7 | 42,1 | 37,5 | 0,1 | 12,2 | 16,0 | 39,3 | 32,1 | 0,5 | 59,8 | 16,5 | 12,8 | 4,1 | 6,8 |
| Sask. | 7,0 | 19,6 | 40,1 | 33,0 | 0,2 | 10,8 | 19,6 | 42,6 | 25,9 | 1,1 | 69,4 | 11,2 | 7,8 | 2,2 | 9,5 |
| Alb. | 3,7 | 17,2 | 47,3 | 31,8 | 0,1 | 3,9 | 20,7 | 54,1 | 20,9 | 0,4 | 56,3 | 21,9 | 17,1 | 1,7 | 3,0 |
| C.-B. | 0,8 | 13,9 | 29,4 | 55,9 | 0,0 | 8,4 | 36,5 | 31,9 | 23,1 | 0,1 | 37,7 | 41,2 | 18,2 | 2,2 | 0,7 |
| Yn | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 15,2 | 57,2 | 7,3 | 20,2 | 0,0 | 59,9 | 22,3 | 0,5 | Note ..: indisponible pour une période de référence précise | 17,3 |
| T.N.-O. | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 2,5 | 39,1 | 53,3 | 4,8 | 0,1 | 42,0 | 32,3 | 4,7 | Note ..: indisponible pour une période de référence précise | 21,1 |
| Nt | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 46,2 | 13,2 | 13,7 | 1,4 | 25,4 |
| Canada | 2,7 | 16,7 | 37,0 | 43,6 | 0,1 | 12,0 | 31,1 | 32,8 | 23,9 | 0,2 | 50,3 | 30,7 | 13,0 | 3,7 | 2,2 |
| % de la population totale | 1,9 | 11,8 | 26,2 | 30,9 | 0,0 | 1,5 | 3,8 | 4,0 | 2,9 | 0,0 | 8,5 | 5,2 | 2,2 | 0,6 | 0,4 |
|
Note : La mesure de la proximité des établissements de soins de santé établit la proximité d’un ID à tout autre ID où se trouve un établissement de soins de santé et qui est situé à une distance de route d’au plus 3 km. Cette mesure est calculée en fonction du nombre d’employés de toutes les entreprises des codes 6211 (Cabinets de médecin), 6212 (Cabinets de dentiste), 6213 (Cabinets d’autres prestataires de services de santé), 621494 (Centres de santé communautaires) et 622 (Hôpitaux) du SCIAN qui figurent dans le Registre des entreprises. Source : Calculs des auteurs. |
|||||||||||||||
Proximité des établissements d’enseignement primaire
Environ 70 % des Canadiens vivent à 1,5 km de marche d’un établissement d’enseignement primaire (tableau 7). Les établissements d’enseignement primaire comprennent les établissements offrant les programmes d’enseignement de la 1re à la 6e année. Pour les familles ayant des enfants, la présence et la proximité d’une école primaire ont une grande incidence sur le choix de quarter. Par conséquent, la proximité de ce type d’établissement est probablement facteur déterminant de la qualité de vie des enfants et des parents.
De manière générale, les RMR affichent les pourcentages les plus élevés de résidents qui vivent dans un quartier situé à proximité d’une école primaire, la proportion s’y élevant à plus de 80 % (tableau 7). Cependant, les résidents des RMR des provinces de l’Atlantique sont plus susceptibles de vivre à plus de 1,5 km de marche d’une école primaire. Au Nouveau-Brunswick et à Terre-Neuve-et-Labrador, environ 50 % de la population des RMR vit au-delà de cette limite (tableau 7). En revanche, les résidents des RMR du Manitoba, de la Saskatchewan et de la Colombie-Britannique sont plus susceptibles de vivre à proximité d’un établissement d’enseignement primaire (75 % ou plus).
Moins de 30 % des résidents de régions rurales, qui comprennent les villages et les petites villes, vivent à 1,5 km de marche d’un établissement d’enseignement. Lorsque la proportion de la population à l’extérieur de cette limite de distance s’ajoute à la proportion de la population vivant dans un ID pour laquelle il n’y a pas de données fiables (colonne « F »), les résultats correspondant aux régions rurales sont semblables dans toutes les provinces. Cependant, les provinces de l’Atlantique sont encore une fois celles où le pourcentage de personnes qui vivent à plus de 1,5 km de marche d’une école est le plus élevé (87 % de la population rurale à l’Île-du-Prince-Édouard et presque 80 % au Nouveau-Brunswick).
| Région géographique | RMR | AR | Rural | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | |
| T.-N.-L. | 50,1 | 19,6 | 20,2 | 10,0 | 0,0 | 64,5 | 19,0 | 11,7 | 4,1 | 0,7 | 73,5 | 15,1 | 5,9 | 1,5 | 4,0 |
| Î.-P.-É. | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 60,5 | 12,9 | 15,0 | 11,5 | 0,0 | 87,1 | 8,3 | 3,2 | 0,8 | 0,6 |
| N.-É. | 36,3 | 27,2 | 19,4 | 16,9 | 0,1 | 64,3 | 19,9 | 13,3 | 2,4 | 0,1 | 79,7 | 13,4 | 5,3 | 1,4 | 0,2 |
| N.-B. | 51,9 | 20,2 | 21,5 | 6,2 | 0,2 | 67,4 | 14,6 | 14,0 | 3,9 | 0,1 | 79,8 | 12,4 | 5,7 | 1,9 | 0,1 |
| Qc | 21,3 | 24,0 | 21,9 | 32,7 | 0,0 | 40,5 | 20,3 | 19,5 | 19,5 | 0,1 | 65,4 | 17,7 | 11,3 | 5,2 | 0,5 |
| Ont. | 16,1 | 20,0 | 26,9 | 36,9 | 0,0 | 41,1 | 19,9 | 23,2 | 15,6 | 0,2 | 69,2 | 14,0 | 10,0 | 6,0 | 0,8 |
| Man. | 13,7 | 17,5 | 24,6 | 44,1 | 0,1 | 27,4 | 24,3 | 22,1 | 25,6 | 0,5 | 62,6 | 12,7 | 11,0 | 6,9 | 6,8 |
| Sask. | 14,2 | 23,4 | 26,5 | 35,7 | 0,2 | 21,5 | 20,2 | 26,8 | 30,3 | 1,1 | 55,3 | 11,8 | 14,5 | 8,9 | 9,5 |
| Alb. | 18,7 | 26,7 | 27,4 | 27,0 | 0,1 | 25,3 | 30,4 | 27,1 | 16,8 | 0,4 | 62,8 | 15,2 | 13,2 | 5,8 | 3,0 |
| C.-B. | 14,6 | 23,3 | 31,7 | 30,4 | 0,0 | 44,7 | 25,9 | 20,4 | 9,0 | 0,1 | 73,1 | 16,4 | 7,4 | 2,4 | 0,7 |
| Yn | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 51,6 | 23,0 | 19,7 | 5,6 | 0,0 | 57,2 | 12,9 | 10,1 | 2,5 | 17,3 |
| T.N.-O. | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 11,7 | 10,4 | 35,1 | 42,6 | 0,1 | 43,4 | 20,4 | 11,6 | 3,4 | 21,1 |
| Nt | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 45,2 | 11,7 | 13,6 | 4,0 | 25,4 |
| Canada | 18,3 | 22,2 | 26,1 | 33,3 | 0,1 | 41,7 | 22,2 | 21,2 | 14,6 | 0,2 | 67,6 | 15,0 | 10,2 | 5,0 | 2,2 |
| % de la population totale | 13,0 | 15,8 | 18,5 | 23,6 | 0,0 | 5,1 | 2,7 | 2,6 | 1,8 | 0,0 | 11,4 | 2,5 | 1,7 | 0,8 | 0,4 |
|
Note : La mesure de la proximité des établissements d’enseignement primaire établit la proximité d’un ID à tout autre ID où se trouve une école primaire et qui est situé à une distance de marche d’au plus 1,5 km. Cette mesure est fondée sur une combinaison de données de la Base de données ouvertes sur les établissements d’enseignement et d’autres sources de données de ce type. Source : Calculs des auteurs. |
|||||||||||||||
Proximité des établissements d’enseignement secondaire
Les établissements d’enseignement secondaire comprennent les établissements offrant les programmes d’enseignement de la 7e à la 12e année. Comme on s’attend à ce que les adolescents soient en mesure de parcourir de plus longues distances pour accéder à un établissement d’enseignement, il est normal qu’une plus petite proportion de la population vive à proximité de ce type d’établissement (tableau 8). Néanmoins, la présence et la proximité d’écoles secondaires peuvent être un moteur de la vitalité pour un quartier et un important facteur de soutien de l’économie locale.
Au Canada, environ 42 % de la population vit dans un quartier situé à 1,5 km de marche d’un établissement d’enseignement secondaire. Ce pourcentage est relativement semblable entre les grandes régions métropolitaines (RMR) et les petites régions métropolitaines (AR), la proportion de la population qui réside dans ces quartiers étant respectivement de 49 % et de 38 %. Pour l’ensemble des régions rurales, ce pourcentage baisse pour passer à moins de 20 %.
Le Manitoba et la Colombie-Britannique affichent la plus grande proportion de la population urbaine vivant dans des quartiers situés à 1,5 km d’une école secondaire : respectivement, environ 77 % et 76 % de la population de leurs RMR vivent à proximité d’un établissement d’enseignement secondaire. De plus, dans ces deux provinces, des pourcentages respectifs de 73 % et de près de 50 % des résidents des petites régions métropolitaines vivent à proximité d’un tel établissement. En Alberta, une proportion relativement élevée de la population des AR (environ 60 %) vit à proximité d’une école secondaire.
Par ailleurs, moins de 20 % de la population rurale vit à proximité (1,5 km de marche) d’un établissement d’enseignement secondaire. Lorsque la proportion de la population vivant à plus de cette distance de ce type d’établissement est ajoutée à la proportion de la population pour laquelle il n’a pas été possible d’obtenir une estimation fiable de la proximité, les résultats sont relativement semblables d’une province à l’autre. La proportion est cependant plus élevée pour les provinces de l’Atlantique et l’Est du Canada (environ 80 % ou plus) et plus faible pour les Prairies et la Colombie-Britannique (environ 70 %).
| Région géographique | RMR | AR | Rural | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | |
| T.-N.-L. | 64,3 | 12,6 | 9,7 | 13,4 | 0,0 | 76,5 | 9,4 | 8,4 | 5,0 | 0,7 | 74,3 | 9,9 | 8,1 | 3,8 | 4,0 |
| Î.-P.-É. | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 64,1 | 12,5 | 11,9 | 11,5 | 0,0 | 89,8 | 4,1 | 3,3 | 2,2 | 0,6 |
| N.-É. | 52,5 | 14,9 | 16,9 | 15,5 | 0,1 | 77,3 | 9,9 | 7,6 | 5,0 | 0,1 | 84,0 | 8,1 | 5,8 | 2,0 | 0,2 |
| N.-B. | 65,7 | 11,0 | 12,9 | 10,1 | 0,2 | 75,9 | 8,1 | 9,2 | 6,7 | 0,1 | 82,2 | 7,4 | 6,3 | 4,1 | 0,1 |
| Qc | 58,9 | 13,8 | 13,3 | 13,9 | 0,0 | 72,3 | 10,2 | 9,8 | 7,6 | 0,1 | 86,0 | 5,9 | 5,5 | 2,1 | 0,5 |
| Ont. | 59,5 | 16,0 | 14,4 | 10,1 | 0,0 | 70,7 | 12,0 | 10,7 | 6,5 | 0,2 | 85,2 | 5,9 | 5,6 | 2,5 | 0,8 |
| Man. | 22,6 | 18,1 | 17,3 | 42,0 | 0,1 | 27,3 | 21,6 | 17,6 | 33,0 | 0,5 | 64,6 | 9,0 | 11,2 | 8,3 | 6,8 |
| Sask. | 57,6 | 15,7 | 14,5 | 12,0 | 0,2 | 55,2 | 14,3 | 12,7 | 16,6 | 1,1 | 60,0 | 9,0 | 13,7 | 7,8 | 9,5 |
| Alb. | 34,8 | 20,9 | 20,7 | 23,5 | 0,1 | 40,5 | 17,2 | 19,1 | 22,8 | 0,4 | 64,7 | 8,0 | 10,3 | 14,0 | 3,0 |
| C.-B. | 23,9 | 15,2 | 15,8 | 45,1 | 0,0 | 52,9 | 14,3 | 15,7 | 17,0 | 0,1 | 73,9 | 9,2 | 9,9 | 6,3 | 0,7 |
| Yn | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 51,6 | 15,2 | 15,3 | 17,9 | 0,0 | 57,1 | 5,1 | 7,2 | 13,3 | 17,3 |
| T.N.-O. | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 12,8 | 11,8 | 22,5 | 52,7 | 0,1 | 47,6 | 13,0 | 12,5 | 5,8 | 21,1 |
| Nt | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 51,5 | 11,8 | 7,5 | 3,8 | 25,4 |
| Canada | 50,8 | 15,9 | 15,1 | 18,1 | 0,1 | 61,9 | 12,8 | 12,7 | 12,4 | 0,2 | 77,9 | 7,3 | 7,6 | 5,0 | 2,2 |
| % de la population totale | 36,0 | 11,3 | 10,7 | 12,9 | 0,0 | 7,6 | 1,6 | 1,5 | 1,5 | 0,0 | 13,1 | 1,2 | 1,3 | 0,8 | 0,4 |
|
Note : La mesure de la proximité des établissements d’enseignement secondaire établit la proximité d’un ID à tout autre ID où se trouve une école secondaire et qui est situé à une distance de marche d’au plus 1,5 km. Cette mesure est fondée sur une combinaison de données de la BDOEE et d’autres sources de données de cette nature. Source : Calculs des auteurs. |
|||||||||||||||
Proximité des services de garde d’enfants
La prestation et l’organisation des services de garde d’enfants sont structurées différemment d’une province à l’autre. De plus, dans certaines régions, la prestation de ces services peut être assurée par des réseaux informels ou peu structurés. Comme nous l’avons indiqué dans la section précédente, cette analyse se limite aux fournisseurs de services de garde agréés, qui figurent dans le Registre des entreprises avec leur emplacement. Des services de garde d’enfants non agréés peuvent être offerts dans un quartier, mais leur existence n’est pas uniforme d’une province à l’autre. Ils ne pouvaient donc pas être utilisés aux fins de la présente analyse. Cette caractéristique des données peut avoir une incidence sur certains résultats.
Dans l’ensemble les résultats concernant la proximité des services de garde semblent comparables à ceux de la proximité des établissements d’enseignement primaire. Selon les résultats à l’échelle nationale, près de 80 % des Canadiens vivent dans un quartier avec un certain degré de proximité aux services de garde. Les résidents des grandes régions urbaines sont plus susceptibles de vivre à proximité de ces services, environ 90 % d’entre eux vivant à 1,5 km de marche d’une garderie. Dans les petites régions urbaines, environ 70 % des résidents visent à proximité d’un service de ce type. Cependant, ce pourcentage diminue pour passer à environ 30 % dans les régions rurales (tableau 9).
C’est le Québec (66,2 %) qui affiche la plus forte proportion au pays de résidents ayant un degré élevé d’accès aux services de garde d’enfants. Il est suivi de la Saskatchewan (46,0 %) et de la Colombie-Britannique (36,0 %). Au Québec, le pourcentage de la population qui vit à proximité de services de garde (c’est-à-dire à une distance d’au plus 1,5 km de marche) est élevé dans les régions urbaines (95 % dans les RMR et 88 % dans les AR) ainsi que dans les régions rurales (53 %). Le Manitoba, l’Alberta, la Saskatchewan et la Colombie-Britannique suivent, avec des proportions relativement élevées dans les régions urbaines, mais des proportions beaucoup plus faibles (moins de 50 %) dans les régions rurales.
La proximité physique d’un fournisseur de services de garde n’est manifestement pas le seul déterminant de la disponibilité du service, bien qu’elle demeure une condition préalable importante pour des services comme les services de garde d’enfants, où la présence physique quotidienne dans les locaux est nécessaire.
| Région géographique | RMR | AR | Rural | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | |
| T.-N.-L. | 14,8 | 39,1 | 38,5 | 7,6 | 0,0 | 33,1 | 35,8 | 27,2 | 3,2 | 0,7 | 84,0 | 10,9 | 1,0 | 0,2 | 4,0 |
| Î.-P.-É. | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 35,7 | 30,0 | 28,5 | 5,8 | 0,0 | 90,7 | 7,6 | 1,0 | 0,1 | 0,6 |
| N.-É. | 23,6 | 31,3 | 27,9 | 17,0 | 0,1 | 55,3 | 31,8 | 12,0 | 0,8 | 0,1 | 76,9 | 18,9 | 3,7 | 0,4 | 0,2 |
| N.-B. | 35,9 | 32,4 | 23,2 | 8,3 | 0,2 | 52,6 | 29,6 | 14,8 | 2,9 | 0,1 | 75,2 | 18,8 | 5,3 | 0,6 | 0,1 |
| Qc | 4,2 | 13,7 | 15,9 | 66,2 | 0,0 | 11,6 | 21,0 | 18,3 | 49,0 | 0,1 | 46,0 | 27,5 | 14,2 | 11,8 | 0,5 |
| Ont. | 11,9 | 27,7 | 36,1 | 24,3 | 0,0 | 38,0 | 35,1 | 23,1 | 3,6 | 0,2 | 74,4 | 17,1 | 6,8 | 1,0 | 0,8 |
| Man. | 9,9 | 24,2 | 40,9 | 25,0 | 0,1 | 23,6 | 35,9 | 30,7 | 9,3 | 0,5 | 74,8 | 13,2 | 4,6 | 0,6 | 6,8 |
| Sask. | 7,0 | 13,6 | 33,2 | 46,0 | 0,2 | 14,5 | 20,8 | 46,0 | 17,6 | 1,1 | 76,5 | 9,8 | 3,7 | 0,4 | 9,5 |
| Alb. | 7,3 | 19,6 | 41,3 | 31,8 | 0,1 | 11,0 | 29,3 | 40,7 | 18,6 | 0,4 | 69,2 | 15,0 | 11,4 | 1,4 | 3,0 |
| C.-B. | 8,3 | 20,8 | 34,9 | 36,0 | 0,0 | 31,5 | 31,2 | 29,5 | 7,7 | 0,1 | 74,5 | 17,7 | 6,2 | 0,9 | 0,7 |
| Yn | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 22,2 | 36,4 | 22,6 | 18,8 | 0,0 | 79,4 | 2,7 | 0,6 | 0,0 | 17,3 |
| T.N.-O. | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 0,4 | 24,8 | 25,5 | 49,1 | 0,1 | 56,7 | 15,0 | 6,3 | 0,9 | 21,1 |
| Nt | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 63,3 | 10,3 | 0,6 | 0,3 | 25,4 |
| Canada | 9,5 | 22,4 | 31,7 | 36,4 | 0,1 | 27,8 | 29,7 | 26,0 | 16,3 | 0,2 | 67,1 | 18,6 | 8,3 | 3,7 | 2,2 |
| % de la population totale | 6,7 | 15,9 | 22,5 | 25,8 | 0,0 | 3,4 | 3,6 | 3,2 | 2,0 | 0,0 | 11,3 | 3,1 | 1,4 | 0,6 | 0,4 |
|
Note : La mesure de la proximité des services de garde d’enfants établit la proximité d’un ID à tout autre ID où se trouve un service de garde d’enfants et qui est situé à une distance de marche d’au plus 1,5 km. Cette mesure est fondée sur la présence de toutes les entreprises du code 624410 (Services de garderie) du SCIAN qui figurent dans le Registre des entreprises, à l’exception des entreprises de travailleurs autonomes dont les revenus annuels sont inférieurs à 30 000 $. Source : Calculs des auteurs. |
|||||||||||||||
Proximité du transport en commun
Les réseaux de transport en commun sont généralement des infrastructures dans les régions urbaines, et particulièrement dans les grandes régions métropolitaines. Sur la base d’un seuil de proximité de 1 km de marche (distance maximale entre un ID et le prochain arrêt de transport en commun), les résultats indiquent qu’environ 70 % des Canadiens vivent à proximité d’un arrêt de transport en commun. Cependant, la grande majorité de ces derniers vivent dans de grandes régions métropolitaines (RMR). À l’échelle nationale, seule une petite proportion des Canadiens dans les petites régions métropolitaines (AR) vivent à proximité d’un arrêt de transport en commun. La proportion est négligeable pour les Canadiens des régions rurales.
Le tableau 10 présente les résultats par type de région, par province et par territoire. La Colombie-Britannique, le Québec, le Manitoba et l’Ontario font partie des provinces où le pourcentage de résidents des RMR vivant à proximité d’un arrêt de transport en commun est plus élevé (environ 90 % ou plus). De plus, le Manitoba (47,1 %), le Québec (40,7 %) et la Colombie-Britannique (36,7 %) affichent le pourcentage le plus élevé de résidents des RMR qui ont un niveau élevé d’accès à un arrêt de transport, c’est-à-dire qu’ils se situent dans le 30 % supérieur des valeurs de proximité pour cette mesure.
La proximité des arrêts de transport en commun diminue considérablement dans les petites régions métropolitaines (AR). À l’exception de la Colombie-Britannique, où environ 70 % des résidents des AR vivent à proximité de services de transport en commun, dans les autres provinces du Canada, de 30 % à 40 % des résidents des petites régions métropolitaines vivent à proximité de ces services. Enfin, en Colombie-Britannique, près de 20 % de la population rurale vit à proximité des transports en commun.
Il faut se rappeler que la couverture des données pour cette mesure demeure incomplète, dans une certaine mesure. Lors du calcul de la mesure, on a constaté qu’environ 60 municipalités, généralement des municipalités de petite taille, avaient certains services de transport en commun (p. ex. entreprises de petite taille, comme des taxi-bus, ou des services offerts seulement certains jours). Cependant, les données concernant ces services n’étaient pas accessibles au format GTFS, ce qui rendait leur utilisation particulièrement difficile. Aux fins des estimations provinciales et territoriales présentées dans le tableau 10, aucune imputation n’a été effectuée pour ces municipalités. Ces dernières ont plutôt été exclues des chiffres de population (autrement dit, il a été implicitement admis que leurs proportions sont proportionnelles à celle de leur province/région correspondante).
| Région géographique | RMR | AR | Rural | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | |
| T.-N.-L. | 37,4 | 35,6 | 22,4 | 4,6 | 0,0 | 99,5 | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 0,5 | 96,0 | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 4,0 |
| N.-É. | 26,1 | 22,8 | 23,4 | 27,6 | 0,1 | 99,9 | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 0,1 | 99,8 | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 0,2 |
| N.-B. | 36,6 | 40,8 | 15,3 | 7,0 | 0,2 | 69,4 | 16,6 | 11,6 | 2,3 | 0,1 | 99,9 | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 0,1 |
| Qc | 9,8 | 22,0 | 27,5 | 40,7 | 0,0 | 77,6 | 16,5 | 5,9 | 0,0 | 0,1 | 95,5 | 3,8 | 0,2 | 0,0 | 0,5 |
| Ont. | 10,9 | 28,6 | 28,3 | 32,2 | 0,0 | 63,0 | 15,1 | 16,9 | 4,8 | 0,2 | 97,1 | 2,1 | 0,0 | Note ..: indisponible pour une période de référence précise | 0,8 |
| Man. | 10,7 | 14,8 | 27,3 | 47,1 | 0,1 | 99,3 | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 0,7 | 93,2 | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 6,8 |
| Sask. | 13,4 | 24,7 | 42,0 | 19,6 | 0,2 | 98,0 | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 2,0 | 90,5 | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 9,5 |
| Alb. | 11,3 | 22,9 | 41,0 | 24,7 | 0,1 | 58,5 | 17,9 | 22,1 | 1,2 | 0,4 | 92,2 | 4,3 | 0,5 | Note ..: indisponible pour une période de référence précise | 3,0 |
| C.-B. | 6,4 | 25,9 | 30,9 | 36,7 | 0,0 | 28,8 | 46,5 | 22,2 | 2,4 | 0,1 | 79,5 | 18,3 | 1,5 | 0,0 | 0,7 |
| Yn | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 25,9 | 58,5 | 14,5 | 1,0 | 0,0 | 82,7 | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 17,3 |
| T.N.-O. | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 11,0 | 64,5 | 24,3 | Note ..: indisponible pour une période de référence précise | 0,1 | 78,9 | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 21,1 |
| Population totale avec données GTFS de transport | 10,9 | 25,6 | 29,9 | 33,5 | 0,0 | 59,9 | 23,9 | 14,1 | 1,8 | 0,2 | 93,9 | 3,7 | 0,2 | 0,0 | 2,1 |
| % de la population totale avec données GTFS de transport | 8,1 | 19,1 | 22,2 | 24,9 | 0,0 | 4,9 | 2,0 | 1,2 | 0,1 | 0,0 | 16,4 | 0,6 | 0,0 | 0,0 | 0,4 |
|
Notes : La mesure de la proximité du transport en commun établit la proximité d’un ID à tout point de service de transport en commun qui est situé à une distance de marche d’au plus 1 km. Cette mesure est calculée en fonction du nombre de déplacements effectués entre 7 h et 10 h, obtenu d’un ensemble de sources de données de la General Transit Feed Specification (GTFS). Ce tableau rend compte de la population des municipalités pour lesquelles des données de transport sont accessibles au format GTFS. L’Île-du-Prince-Édouard et le Nunavut ont été exclus du calcul en raison de l’absence de données au format GTFS. Source : Calculs des auteurs. |
|||||||||||||||
Proximité des bibliothèques publiques
Les bibliothèques publiques représentent un important lieu de socialisation et d’accès à du matériel éducatif pour les jeunes et les familles. Dans la plupart des cas, les bibliothèques offrent également des accès Internet au grand public et surtout à la partie de la population qui n’a pas accès aux services Internet à domicile. Pour ces raisons, la présence d’une bibliothèque publique est un indicateur pertinent du bien-être de la collectivité.
Aux fins de la présente analyse, le critère de proximité pour cette mesure est la présence d’une bibliothèque à une distance de marche d’au plus 1,5 km. Fait intéressant, avec cette spécification, la proximité des bibliothèques publiques est assez semblable d’une province à l’autre et d’une région urbaine ou rurale à l’autre. Environ 30 % des Canadiens vivent à proximité d’une bibliothèque publique, tandis qu’environ 70 % doivent parcourir plus de 1,5 km à pied pour y accéder (tableau 11).
Les résultats indiquent que la proximité des bibliothèques publiques est semblable d’une région à l’autre. Environ 33 % des résidents des RMR vivent dans un quartier situé à proximité d’une bibliothèque. À l’échelle nationale, les résidents des régions rurales sont légèrement plus susceptibles de vivre à proximité d’une bibliothèque (22 % de la population rurale) que les résidents des petites régions métropolitaines (21 %). Dans les régions rurales, la proximité de la bibliothèque est quelque peu comparable à celle des établissements d’enseignement primaire, ce qui suggère que ces services sont probablement coïmplantés et intégrés dans le tissu social et économique de nombreux villages ruraux et petites villes.
Les écarts entre les provinces révèlent une tendance observée dans d’autres mesures de proximité : dans les provinces de l’Atlantique, le pourcentage de personnes vivant à plus de 1,5 km d’une bibliothèque est généralement plus élevé qu’ailleurs, se situant généralement près ou au-dessus de 80 %, tandis que dans les provinces de l’Est, les Prairies et la Colombie-Britannique ces pourcentages sont généralement inférieurs à 80 %.
| Région géographique | RMR | AR | Rural | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | |
| T.-N.-L. | 89,3 | 5,8 | 3,6 | 1,2 | 0,0 | 80,0 | 9,3 | 6,3 | 3,7 | 0,7 | 76,6 | 9,0 | 6,5 | 3,9 | 4,0 |
| Î.-P.-É. | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 74,3 | 9,6 | 5,6 | 10,5 | 0,0 | 87,8 | 2,8 | 3,9 | 4,8 | 0,6 | |
| N.-É. | 83,1 | 7,6 | 4,0 | 5,2 | 0,1 | 78,2 | 7,9 | 8,6 | 5,2 | 0,1 | 85,9 | 5,3 | 5,0 | 3,6 | 0,2 |
| N.-B. | 85,9 | 5,9 | 5,4 | 2,6 | 0,2 | 85,9 | 4,5 | 4,0 | 5,6 | 0,1 | 86,3 | 4,9 | 4,9 | 3,8 | 0,1 |
| Qc | 63,0 | 12,8 | 10,9 | 13,3 | 0,0 | 77,3 | 8,9 | 7,1 | 6,6 | 0,1 | 78,5 | 7,4 | 7,1 | 6,5 | 0,5 |
| Ont. | 64,8 | 12,4 | 11,2 | 11,5 | 0,0 | 74,2 | 9,6 | 9,5 | 6,6 | 0,2 | 73,6 | 8,4 | 8,7 | 8,6 | 0,8 |
| Man. | 73,6 | 10,8 | 9,4 | 6,1 | 0,1 | 69,9 | 9,8 | 9,7 | 10,1 | 0,5 | 77,6 | 4,1 | 5,8 | 5,7 | 6,8 |
| Sask. | 66,9 | 11,7 | 10,9 | 10,3 | 0,2 | 70,1 | 9,3 | 7,8 | 11,6 | 1,1 | 57,2 | 6,9 | 10,0 | 16,4 | 9,5 |
| Alb. | 82,3 | 7,8 | 6,1 | 3,8 | 0,1 | 84,5 | 6,4 | 5,5 | 3,3 | 0,4 | 69,9 | 8,4 | 10,1 | 8,7 | 3,0 |
| C.-B. | 60,9 | 14,3 | 13,7 | 11,2 | 0,0 | 83,0 | 7,1 | 6,1 | 3,6 | 0,1 | 79,7 | 7,7 | 7,3 | 4,7 | 0,7 |
| Yn | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 93,6 | 1,9 | 2,8 | 1,7 | 0,0 | 66,1 | 3,3 | 5,3 | 8,0 | 17,3 |
| T.N.-O. | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 64,3 | 7,7 | 16,8 | 11,0 | 0,1 | 52,6 | 6,6 | 11,7 | 8,1 | 21,1 |
| Nt | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 54,4 | 6,8 | 5,9 | 7,4 | 25,4 |
| Canada | 66,9 | 12,0 | 10,6 | 10,5 | 0,1 | 78,5 | 8,2 | 7,3 | 5,8 | 0,2 | 75,4 | 7,3 | 7,7 | 7,3 | 2,2 |
| % de la population totale | 47,5 | 8,5 | 7,5 | 7,5 | 0,0 | 9,6 | 1,0 | 0,9 | 0,7 | 0,0 | 12,7 | 1,2 | 1,3 | 1,2 | 0,4 |
|
Note : La mesure de la proximité des bibliothèques publiques établit la proximité d’un ID à tout autre ID où se trouve une bibliothèque et qui est situé à une distance de marche d’au plus 1,5 km. Cette mesure est fondée sur tous les renseignements concernant les bibliothèques tirés d’un ensemble de sources de données ouvertes. Source : Calculs des auteurs. |
|||||||||||||||
Proximité des parcs de quartier
Les parcs de quartier sont souvent considérés comme un aménagement représentatif d’un environnement urbain où les espaces verts naturels sont rares ou éloignés. Cependant, ils offrent habituellement plus que des espaces verts. Ils sont souvent dotés de terrains de jeu destinés aux enfants et ainsi que de diverses infrastructures sportives et récréatives. Ces caractéristiques rendent particulièrement difficile la définition des parcs de quartier et, par conséquent, la couverture des renseignements comporte certaines lacunes potentielles.
Tout en tenant compte de ces limitations, les résultats confirment que la proximité d’un parc de quartier (à distance de marche d’au plus 1 km) est typique des populations urbaines. Toutefois, un pourcentage considérable de la population rurale profite également de la proximité d’un parc (tableau 12). Environ 75 % de la population canadienne vit à 1 km d’un parc de quartier. Pour les résidents des grandes régions métropolitaines (RMR), ce pourcentage est de 88 %, et pour ceux de petites régions métropolitaines (AR), il est d’environ 63 %. Selon les résultats, près de 30 % des résidents de régions rurales vivent à proximité d’un parc de quartier.
De grandes différences sont constatées entre les provinces, et ce, même dans les grandes régions métropolitaines. À Terre-Neuve-et-Labrador et au Nouveau-Brunswick, environ 50 % des résidents des régions métropolitaines, ou légèrement moins, vivent à proximité d’un parc de quartier. En revanche, une proportion relativement importante des résidents ruraux du Québec et de la Colombie-Britannique (environ 20 % ou légèrement plus) jouissent de la proximité d’un tel parc.
La recherche semble indiquer que la présence d’un parc de quartier, bien qu’il s’agisse d’une condition préalable fondamentale, n’est qu’un des attributs souhaitables de ce type d’aménagement. La population accorde une attention toute particulière aux aspects qualitatifs des parcs de quartier, y compris les caractéristiques esthétiques, la perception de la sécurité, etc. Ces aspects sont particulièrement difficiles à mesurer à grande échelle. Grâce à l’accessibilité accrue aux données, certaines de ces caractéristiques pourraient être prises en compte dans le calcul de la mesure de proximité des parcs de quartier.
| Région géographique | RMR | AR | Rural | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | Extérieur | Inférieur | Intermédiaire | Supérieur | Note F: trop peu fiable pour être publié | |
| T.-N.-L. | 61,9 | 17,9 | 15,0 | 5,1 | 0,0 | 71,3 | 20,8 | 6,9 | 0,4 | 0,7 | 74,1 | 17,3 | 3,9 | 0,7 | 4,0 |
| Î.-P.-É. | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 51,4 | 23,5 | 16,4 | 8,7 | 0,0 | 89,5 | 7,1 | 2,7 | 0,1 | 0,6 |
| N.-É. | 9,2 | 27,2 | 20,1 | 43,3 | 0,1 | 63,2 | 22,7 | 11,8 | 2,1 | 0,1 | 79,8 | 13,8 | 4,4 | 1,8 | 0,2 |
| N.-B. | 47,4 | 23,1 | 19,6 | 9,7 | 0,2 | 56,3 | 16,3 | 11,7 | 15,6 | 0,1 | 77,3 | 16,6 | 5,3 | 0,7 | 0,1 |
| Qc | 13,2 | 24,5 | 29,2 | 33,0 | 0,0 | 33,6 | 28,5 | 23,0 | 14,7 | 0,1 | 67,0 | 19,8 | 9,8 | 2,9 | 0,5 |
| Ont. | 10,7 | 23,0 | 31,8 | 34,4 | 0,0 | 40,8 | 25,4 | 23,9 | 9,7 | 0,2 | 69,4 | 17,6 | 9,8 | 2,5 | 0,8 |
| Man. | 9,2 | 14,7 | 21,8 | 54,1 | 0,1 | 30,8 | 30,5 | 28,7 | 9,5 | 0,5 | 72,3 | 13,0 | 6,2 | 1,6 | 6,8 |
| Sask. | 9,0 | 17,9 | 32,5 | 40,4 | 0,2 | 21,2 | 26,8 | 35,4 | 15,5 | 1,1 | 63,9 | 13,5 | 9,7 | 3,4 | 9,5 |
| Alb. | 8,6 | 18,4 | 21,5 | 51,3 | 0,1 | 16,2 | 24,2 | 29,0 | 30,2 | 0,4 | 69,9 | 11,7 | 9,6 | 5,8 | 3,0 |
| C.-B. | 10,9 | 25,1 | 33,3 | 30,7 | 0,0 | 36,9 | 23,3 | 20,8 | 18,8 | 0,1 | 64,5 | 23,2 | 9,0 | 2,6 | 0,7 |
| Yn | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 65,3 | 13,8 | 12,7 | 8,2 | 0,0 | 67,9 | 8,0 | 5,0 | 1,8 | 17,3 |
| T.N.-O. | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 5,5 | 25,0 | 34,8 | 34,5 | 0,1 | 59,1 | 14,8 | 4,2 | 0,7 | 21,1 |
| Nt | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 68,2 | 3,9 | 1,8 | 0,7 | 25,4 |
| Canada | 11,8 | 22,7 | 29,5 | 35,9 | 0,1 | 37,1 | 24,9 | 22,7 | 15,1 | 0,2 | 69,5 | 16,9 | 8,6 | 2,8 | 2,2 |
| % de la population totale | 8,4 | 16,1 | 20,9 | 25,5 | 0,0 | 4,5 | 3,0 | 2,8 | 1,8 | 0,0 | 11,7 | 2,8 | 1,4 | 0,5 | 0,4 |
|
Note : La mesure de la proximité des parcs de quartier établit la proximité d’un ID à tout autre ID où se trouve un parc de quartier et qui est situé à une distance de marche d’au plus 1 km. Cette mesure est fondée sur la présence de tous les parcs, selon les renseignements tirés d’un ensemble de sources de données ouvertes. Source : Calculs des auteurs. |
|||||||||||||||
Renseignements préliminaires sur les quartiers et localités à forte densité de services et commodités au Canada
À titre d’exemple de l’utilisation des mesures de proximité, huit mesures décrites dans les sections précédentes ont été combinées pour générer un indicateur agrégé des quartiers « à forte densité de services et commodités ». D’une certaine façon, cet indicateur s’aligne sur le concept de « quartiers x minutes », qui est souvent depuis un certain temps dans les projets de planification urbaine.
Dans ce cas précis, la mesure agrégée identifie les quartiers qui permettent à une famille avec d’âge mineur d’accéder à un ensemble de services de base. Par conséquent, un quartier « à forte densité de services et commodités » est défini comme un îlot de diffusion qui donne accès à au moins une épicerie, une pharmacie et un arrêt de transport en commun à une distance d’au plus 1 km de marche; à un service de garde d’enfants, un établissement d’enseignement primaire et une bibliothèque à une distance d’au plus 1,5 km de marche; à un établissement de soins de santé à une distance d’au plus 3 km de route; et à des emplois à une distance d’au plus 10 km de route. Un tel indicateur s’applique essentiellement aux régions majoritairement urbaines en raison des distances et de la présence de services urbains représentatifs, comme le transport en commun.
Le tableau 14 présente les pourcentages de la population vivant dans des quartiers présentent diverses densités de services et commodités, selon la province et le territoire, et le type de région. Dans le tableau, les quartiers à faible densité désignent ceux qui ne donnent pas accès aux huit services dans le rayon spécifié; les quartiers à densité moyenne et élevée correspondent à ceux qui donnent accès aux huit services dans le rayon spécifié; et les quartiers à densité élevée sont ceux dont les mesures de proximité de chaque service se trouvent dans le tertile supérieur de leur répartition.
Selon cette spécification, près de 20 % des Canadiens vivent dans un quartier à moyenne ou haute densité. Autrement dit, ils jouissent d’une proximité relativement élevée aux services et commodités considérés dans ce panier. Comme on pouvait s’y attendre, les quartiers à densité moyenne ou élevée sont surtout situés dans les grandes régions métropolitaines. Près de 24 % de la population des RMR dans des quartiers à densité moyenne à élevée. Cependant, ce pourcentage varie d’un maximum de plus de 30 % en Colombie-Britannique à un minimum de moins de 3 % à Terre-Neuve-et-Labrador. En revanche, dans les régions rurales, les huit services et commodités considérés dans cette spécification ne se trouvent pas dans les rayons spécifiés. Cependant, il est intéressant de constater qu’une petite proportion de la population rurale du Québec, de l’Ontario, d’Alberta et de Colombie-Britannique profite de ce niveau d’accès.
| Région géographique | RMR | AR | Rural | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Faible densité | Densité moyenne | Densité élevée | Note F: trop peu fiable pour être publié | Faible densité | Densité moyenne | Densité élevée | Note F: trop peu fiable pour être publié | Faible densité | Densité moyenne | Densité élevée | Note F: trop peu fiable pour être publié | |
| T.-N.-L. | 97,7 | 2,3 | Note ..: indisponible pour une période de référence précise | 0,0 | 99,5 | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 0,5 | 96,0 | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 4,0 |
| N.-É. | 90,6 | 9,0 | 0,3 | 0,1 | 99,9 | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 0,1 | 99,8 | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 0,2 |
| N.-B. | 92,7 | 7,0 | Note ..: indisponible pour une période de référence précise | 0,2 | 95,6 | 4,3 | Note ..: indisponible pour une période de référence précise | 0,1 | 99,9 | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 0,1 |
| Qc | 72,5 | 21,3 | 6,1 | 0,0 | 95,5 | 4,4 | Note ..: indisponible pour une période de référence précise | 0,1 | 99,1 | 0,4 | Note ..: indisponible pour une période de référence précise | 0,5 |
| Ont. | 75,0 | 20,3 | 4,7 | 0,0 | 96,6 | 3,2 | Note ..: indisponible pour une période de référence précise | 0,2 | 99,1 | 0,1 | Note ..: indisponible pour une période de référence précise | 0,8 |
| Man. | 80,4 | 18,9 | 0,7 | 0,1 | 99,3 | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 0,7 | 93,2 | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 6,8 |
| Sask. | 83,7 | 15,4 | 0,7 | 0,2 | 98,0 | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 2,0 | 90,5 | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 9,5 |
| Alb. | 89,9 | 9,7 | 0,2 | 0,1 | 94,9 | 4,7 | Note ..: indisponible pour une période de référence précise | 0,4 | 96,1 | 0,9 | Note ..: indisponible pour une période de référence précise | 3,0 |
| C.-B. | 68,5 | 28,8 | 2,7 | 0,0 | 92,9 | 7,0 | 0,0 | 0,1 | 98,0 | 1,3 | Note ..: indisponible pour une période de référence précise | 0,7 |
| Yn | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 98,6 | 1,4 | Note ..: indisponible pour une période de référence précise | 0,0 | 82,7 | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 17,3 |
| T.N.-O. | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 77,4 | 22,5 | Note ..: indisponible pour une période de référence précise | 0,1 | 78,9 | Note ..: indisponible pour une période de référence précise | Note ..: indisponible pour une période de référence précise | 21,1 |
| Canada | 76,3 | 19,8 | 3,9 | 0,0 | 95,2 | 4,6 | 0,0 | 0,2 | 97,5 | 0,4 | 0,0 | 2,1 |
| % de la population totale | 56,5 | 14,7 | 2,9 | 0,0 | 7,9 | 0,4 | 0,0 | 0,0 | 17,2 | 0,1 | 0,0 | 0,4 |
|
Notes : L’Île-du-Prince-Édouard et le Nunavut ont été exclus du calcul en raison de l’absence de données au format GTFS. Les données sont arrondies à une décimale; par conséquent, certaines sont présentées comme des zéros réels. Source: Calculs des auteurs. |
||||||||||||
Considérations en vue de futurs travaux
Outre la mise à jour périodique ou l’extension des mesures, de nouveaux développements seront possibles à mesure que de nouvelles données deviendront disponibles. Le modèle général utilisé dans cet article peut être appliqué à presque tous les types de services et commodités géolocalisés dans l’espace, avec un nombre pratiquement infini de variantes de la spécification du modèle.
Les rayons et les mesures de la taille des entreprises (les masses) peuvent être adaptés à des analyses de politiques particulières ou aux besoins des utilisateurs. De même, le modèle peut être facilement modifié pour générer des mesures plus simples de grandeurs comme « la distance à », « la distance minimale à », etc.
De plus, des variantes du même modèle peuvent être appliquées pour générer des données qui permettent de comprendre la répartition des emplacements ou des emplacements de coïmplantation des entreprises, ou des segments de chaînes d’approvisionnement particulières, ce qui fournit ainsi une nouvelle perspective des groupes opérationnels. La proximité d’un type d’entreprises peut être mesurée par rapport à n’importe quel autre type d’entreprise, et les résultats peuvent être utilisés pour faire des analyses de coïmplantation dans les secteurs. Avec une combinaison de données du Registre des entreprises et de données ouvertes et de géolocalisation au niveau de l’îlot de diffusion à l’échelle du Canada, cela peut permettre une analyse spatiale des entreprises qui était auparavant impossible à réaliser.
Le modèle de base peut également être élargi pour inclure des facteurs liés à la demande. Dans la spécification actuelle, le modèle ne tient pas compte de l’utilisation des services ou de la demande potentielle. La demande peut provenir de la population, de la popularité de l’emplacement, de l’achalandage du transport en commun, des lits d’hôpitaux utilisés, de la superficie des bâtiments, et ainsi de suite, et peut être intégrée au cadre actuel du modèle de gravitationnel. Le principal défi concernant ces variantes demeure la disponibilité des données à couverture nationale, au-delà des simples chiffres de population. Des données ouvertes plus complètes constitueront un élément important pour déterminer l’offre et la demande de points de service.
Dans le même ordre d’idées, d’autres facteurs pourraient être considérés en ce qui concerne le « point de départ » du processus de prise en compte de la proximité de services particuliers. La spécification de mesure élaborée jusqu’à maintenant a porté sur la distance entre le lieu de résidence des ménages et une entreprise donnée. Toutefois, l’hypothèse selon laquelle les services ne seront accessibles qu’à partir du domicile n’est pas nécessairement exacte. De nombreux Canadiens font la navette pour se rendre au travail et, par conséquent, ils peuvent avoir accès à des services à proximité de leur lieu de travail qui ne sont pas considérés à proximité de leur résidence. Par exemple, les membres d’un ménage qui travaillent peuvent décider d’accéder à des services bancaires, récréatifs et de vente au détail qui se trouvent à proximité de leur lieu de travail.
Les mesures actuelles sont fondées sur l’utilisation de deux méthodes de transport différentes dans le calcul des distances dans les réseaux piétonnier et routier. Une autre amélioration consisterait à examiner les distances réseau en rapport avec le réseau de transport en commun. Cela mènerait à des mesures qui rendraient mieux compte de la proximité pour les ménages qui utilisent le transport en commun. Les fonctions de réduction de la distance servent à modéliser plus précisément la volonté d’une personne de se déplacer, souvent interprétée comme la volonté d’un voyageur de parcourir une distance donnée. La fonction actuelle de réduction de la distance varie linéairement avec la distance. Toutefois, une forme fonctionnelle plus sophistiquée peut être estimée empiriquement au moyen de données sur les navetteurs. Cela donnerait lieu à un modèle qui rendrait plus fidèlement compte des habitudes de déplacement.
Les problèmes découlant de l’utilisation de l’ID comme unité d’analyse ont été soulevés à la section 4. En particulier, le centroïde des grands ID peut poser problème, car ce n’est peut-être pas là que se trouvent les consommateurs ou les points de service. On peut atténuer ce problème en utilisant des données sur l’empreinte des immeubles (p. ex. la Base de données ouvertes sur les immeublesNote ) pour déterminer un point représentatif où se trouve le groupe le plus dense d’immeubles dans un ID.
Finalement, un certain nombre de problèmes relativement petits demeurent non résolus. Par exemple, les problèmes de « frontière » mènent à un biais à l’égard des ID voisins d’une frontière. Des services disponibles, mais situés au-delà d’une frontière ne sont pas pris en compte à cause de leur accès à de l’approvisionnement hors région. Ils ont cependant une certaine valeur. Des ID proches de la frontière de la frontière canado-américaine pourraient constituer un exemple. Les résidents de ces ID peuvent avoir accès à des services aux États-Unis, mais ces services ne sont pas pris en compte dans les mesures de proximité. Ce problème est plus pertinent pour des types particuliers de services comme la vente au détail.
Conclusions
Cet article décrit une méthodologie servant au calcul de mesures de proximité de services et commodités au niveau du quartier et de la localité, dans l’ensemble du Canada. La méthodologie a été appliquée à dix types de services et commodités, et certaines des mesures qui en ont découlé ont été combinées pour créer un indicateur composite des quartiers à forte densité de services et de commodités.
Cette analyse comble une importante lacune statistique en donnant lieu à la création de la première Base de données des mesures de proximité. Celle-ci peut être utilisée pour établir des mesures de proximité au niveau du quartier ou de la localité, en utilisant les îlots de diffusion de Statistique Canada, lesquels représentent l’unité géographique la plus détaillée actuellement disponible à l’échelle nationale, et qui sont associés à des chiffres de population. Par conséquent, l’analyse fournit un premier cadre méthodologique commun pour calculer des mesures de proximité de près d’un demi-million de quartiers et de localités couvrant l’ensemble du Canada.
Outre des statistiques agrégées présentées dans cet article, les utilisateurs ont accès à l’ensemble de la base de données au niveau du quartier et à un outil de visualisation qui permet d’afficher et d’analyser rapidement les mesures au niveau du quartier souhaitées. Chaque quartier peut être comparé à n’importe quelle autre région du Canada à l’aide au moyen d’un cadre de mesure commun.
Par exemple, ce cadre et les mesures de proximité utilisées pour effectuer la présente analyse indiquent que près de 20 % des Canadiens vivent dans un quartier à « forte densité de services et commodités » qui offre aux familles avec des enfants d’âge mineur un accès relativement facile à un ensemble de services de base (une épicerie, une pharmacie, un arrêt de transport en commun à une distance d’au plus 1 km de marche; un service de garde d’enfants, un établissement d’enseignement primaire et une bibliothèque à une distance d’au plus 1,5 km de marche; un établissement de soins de santé à une distance d’au plus 3 km de route; et des emplois à une distance d’au plus 10 km de route). Il montre également l’emplacement exact de ces quartiers, qui, comme on peut s’y attendre, sont pour la plupart situés dans de grandes régions métropolitaines.
La réalisation de cette analyse a exigé un effort considérable en matière d’élaboration de spécifications de données ainsi que des calculs massifs. Premièrement, le travail a exigé l’élaboration de spécifications de données ainsi que le traitement et la validation de données de géolocalisation de millions de services et commodités au moyen d’une combinaison de sources statistiques officielles (Registre des entreprises de Statistique Canada) ainsi que de données ouvertes et de données accessibles au public. Plus important encore, l’élaboration des spécifications de ces mesures reposait sur le calcul matriciel d’environ 2,6 milliards de distances point à point. Le traitement de ce volume d’information a été possible grâce à un environnement infonuagique et à des applications et des logiciels libres, du moins en grande partie.
Malgré ces efforts considérables, les mesures de proximité actuelles sont publiées sous forme de statistiques expérimentales. La nouveauté des méthodes et une partie importante des données sont susceptibles de donner lieu à des révisions ou à une extension future des mesures, car la qualité et la couverture des données de géolocalisation continuent de croître au fil du temps. Compte tenu du volume des calculs et du niveau de détail géographique atteint dans cette analyse, les résultats ne peuvent être validés que grâce à la rétroaction continue des utilisateurs.
Plus important encore, le cadre méthodologique et de données mis au point pour cette analyse peut maintenant être adapté pour le calcul de diverses autres spécifications pour les mêmes mesures ou de mesures supplémentaires de proximité. Ces mesures supplémentaires peuvent servir à répondre à des besoins stratégiques définis et permettre une compréhension géographique détaillée de l’accessibilité physique à des services ou commodités en particulier.
References
Alasia, A., et coll. 2017. « Mesurer l’éloignement et l’accessibilité : Un ensemble d’indices pour les collectivités canadiennes », Rapports sur les projets spéciaux d’entreprises, produit no 18-001-X au catalogue de Statistique Canada, https://www150.statcan.gc.ca/n1/pub/18-001-x/18-001-x2017002-fra.htm (site consulté le 12 septembre 2019).
Apparicio, P., et coll. 2017. « The Approaches to Measuring the Potential Spatial Access to Urban Health Services Revisited : Distance Types and Aggregation-error Issues », International Journal of Health Geography, vol. 16, no 32, https://doi.org/10.1186/s12942-017-0105-9 (site consulté le 12 septembre 2019).
Apparicio, P., et A.-M. Séguin. 2006. « Measuring the Accessibility of Services and Facilities for Residents of Public Housing in Montréal », Urban Studies, vol. 43, no 1, p. 187 à 211, https://journals.sagepub.com/doi/10.1080/00420980500409334 (site consulté le 12 septembre 2019).
Becker, Jan, et coll. 2017. « The Role of Mere Closeness : How Geographic Proximity Affects Social Influence », Journal of Marketing, vol. 81, no 5, p. 49 à 66, https://doi.org/10.1509%2Fjm.16.0057(site consulté le 12 septembre 2019).
Brownson, R. C., et coll. 2009. « Measuring the Built Environment for Physical Activity: State of the Science », American Journal of Preventive Medicine, vol. 36, no 4, p. 99 à 123.
Duranton, G., et W. R. Kerr. 2015. « The Logic of Agglomeration », National Bureau of Economic Research Working Paper Series, no 21452.
Google Developers. s.d. API de Google Transports en commun , https://developers.google.com/transit?hl=fr (site consulté le 12 septembre 2019).
GTFS. s.d. GTFS : Making Public Transit Data Universally Accessible, https://gtfs.org/ (site consulté le 12 septembre 2019.
Head, K., et T. Mayer. 2004. « The Empirics of Agglomeration and Trade », Handbook of Regional and Urban Economics,vol. 4, Amsterdam, Elvieser, p. 2609 à 2669.
Horner, M. W., et A. K. Mascarenhas. 2017. « Analyzing Location-Based Accessibility to Dental Services: An Ohio Case Study », Journal of Public Health Dentistry, vol. 67, no 2, p. 113 à 118.
Jones, A., M. Hillsdon et E. Coombes. 2009. « Greenspace access, use, and physical activity: understanding the effects of area deprivation », Preventative Medicine, vol. 49, no 6, p. 500 à 505.
Melo, P. C., et coll. 2017. « Agglomeration, Accessibility and Productivity: Evidence for Large Metropolitan Areas in the U.S. », Urban Studies, vol. 54, no 1, p. 179 à 195, https://doi.org/10.1177/0042098015624850 (site consulté le 12 septembre 2019).
Nguyen, T., et B. K. Szymanski. 2012. « Using Location-Based Social Networks to Validate Human Mobility and Relationships Models », IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining,Istambul, p. 1215 à 1221, doi:10.1109/ASONAM.2012.210 (site consulté le 12 septembre 2019).
OCDE. 2018. « Modernizing Statistical Systems for Better Data on Regions and Cities », OECD Workshop Proceedings, http://www.oecd.org/cfe/regionaldevelopment/modernising-statistical-systems.htm (site consulté le 12 septembre 2019).
OCDE. 2013. « Workshop: Accessibility to Services in Regions and Cities: Measures and Policies. », http://www.oecd.org/cfe/regionaldevelopment/accessibilitytoservices.htm (site consulté le 12 septembre 2019).
Pàez, A., D. M. Scott et C. Morency. 2012. « Measuring Accessibility: Positive and Normative Implementations of Various Accessibility Indicators. », Journal of Transport Geography, vol. 25, p. 141 à 153.
Schipperijn, J., et coll. 2010. « Factors Influencing the Use of Green Space: Results from a Danish National Representative Survey », Landscape and Urban Planning, vol. 95, no 3, p. 130 à 137.
Statistique Canada. 2017a. « Fichiers des limites, guide de référence », Année de recensement 2016, produit no 92-160-G au catalogue de Statistique Canada, https://www150.statcan.gc.ca/n1/pub/92-160-g/92-160-g2016001-fra.htm (site consulté le 12 septembre 2019).
Statistique Canada. 2017b. « Centre de population (CTRPOP) », Dictionnaire, Recensement de la population, 2016, produit no 98-301-X au catalogue de Statistique Canada, https://www12.statcan.gc.ca/census-recensement/2016/ref/dict/geo049a-fra.cfm (site consulté le 12 septembre 2019).
Statistique Canada. 2019. La Base de données ouvertes sur les établissements d’enseignement : concepts, méthodologie et qualité des données, no de catalogue 13260001, no d’exemplaire 2020001, https://www.statcan.gc.ca/fra/ecdo/bases-donnees/bdoess (site consulté le 12 septembre 2019).
- Date de modification :